图片短链接生成器哈尔滨seo优化效果
参考:
不用找咒语了!Midjourney图生文功能特征解析,玩转Describe命令,快速搞定AI绘画_哔哩哔哩_bilibili
1 登录 discord

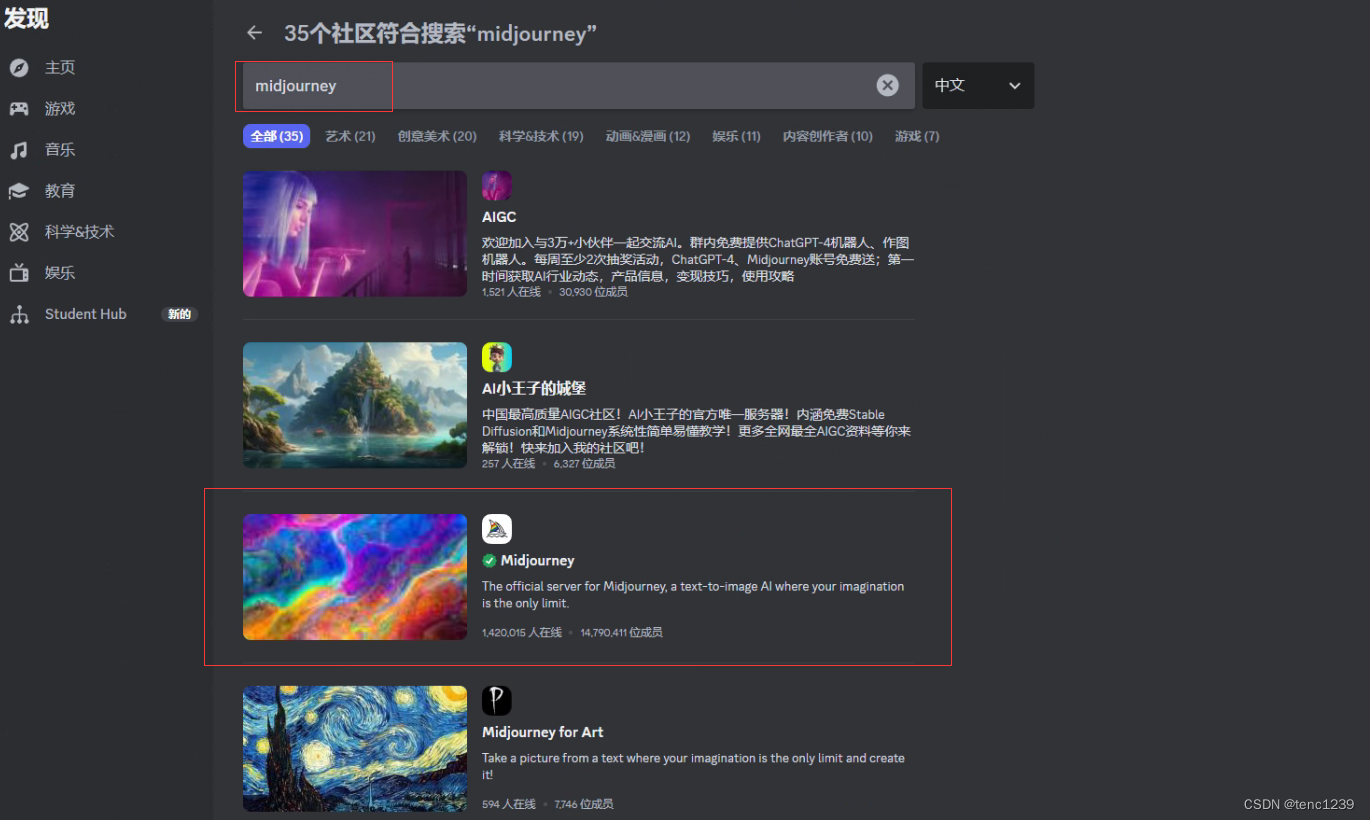
2 点发现 找 midjourney
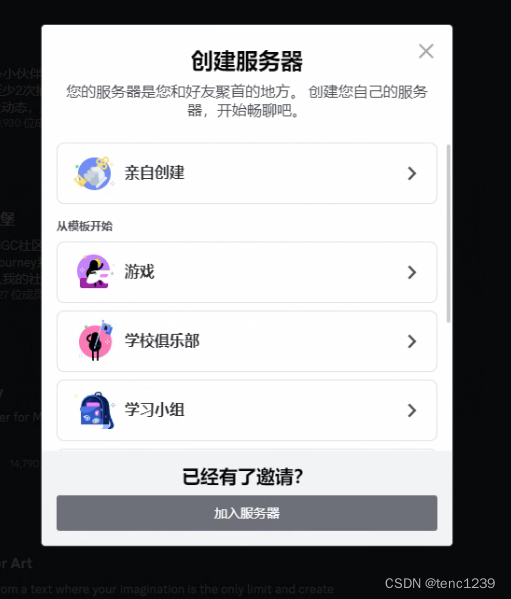
3 创建 服务器 -> 亲自创建
4 选 仅供我和我的朋友使用

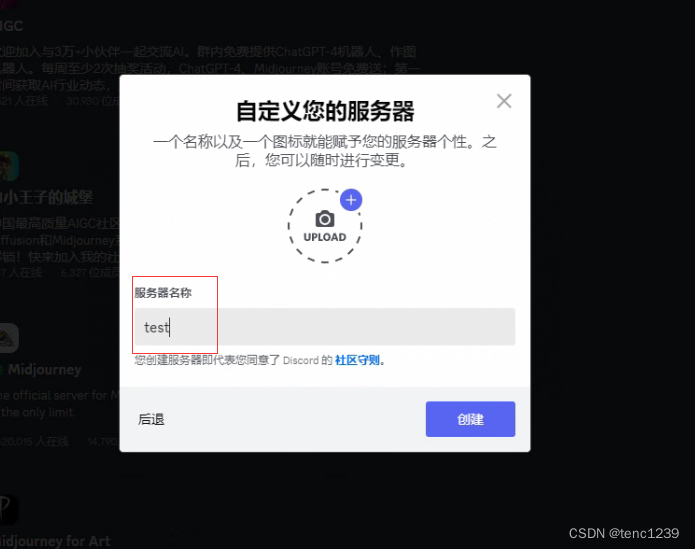
5 起个 服务器名字
6 加bot 由于midjourney 服务器忙加不进去, 我进入Midjourney for art
6.1 然后 右上角 搜索bot 找到 midjourney bot 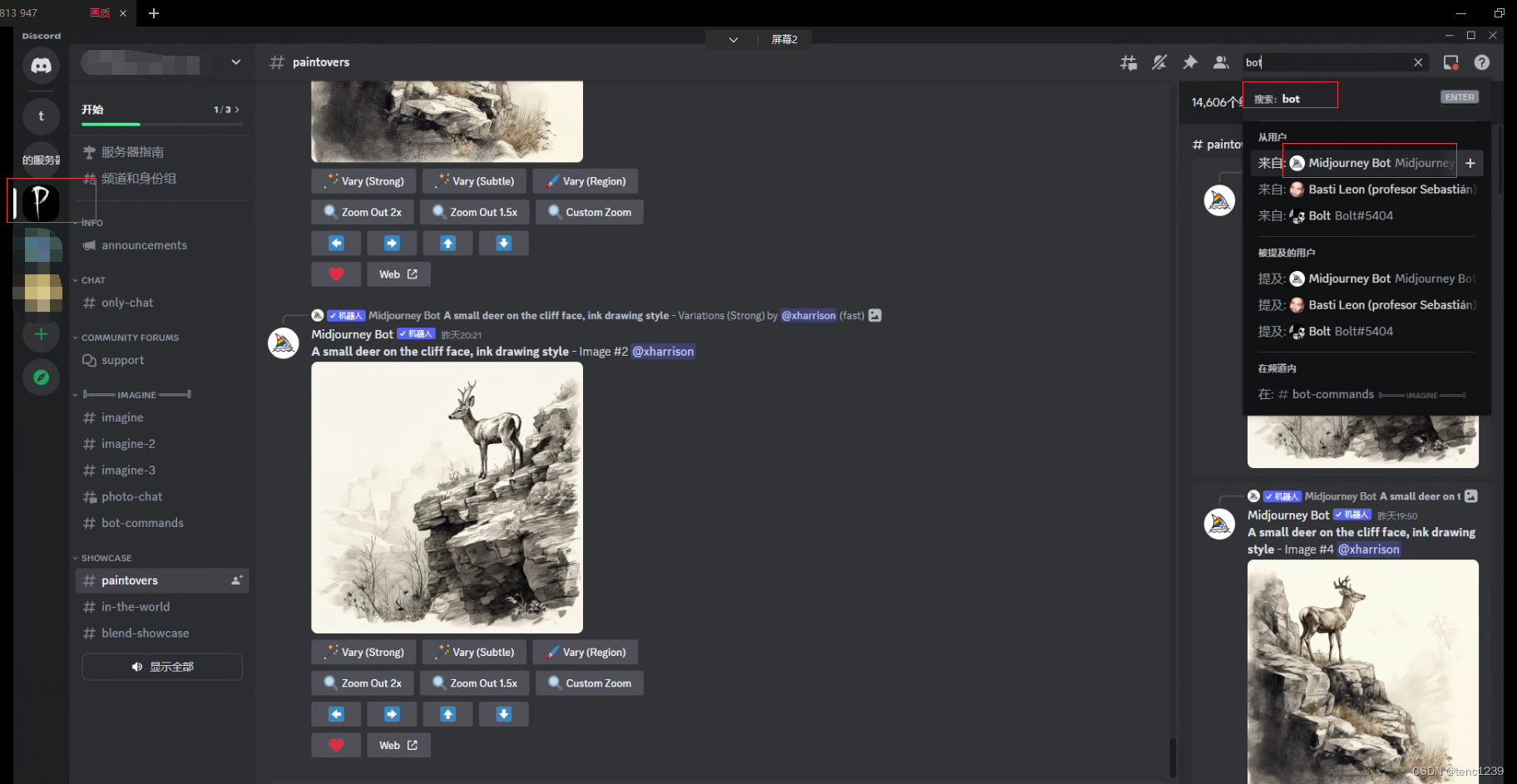
7 然后把这个 添加到 刚创建的服务器
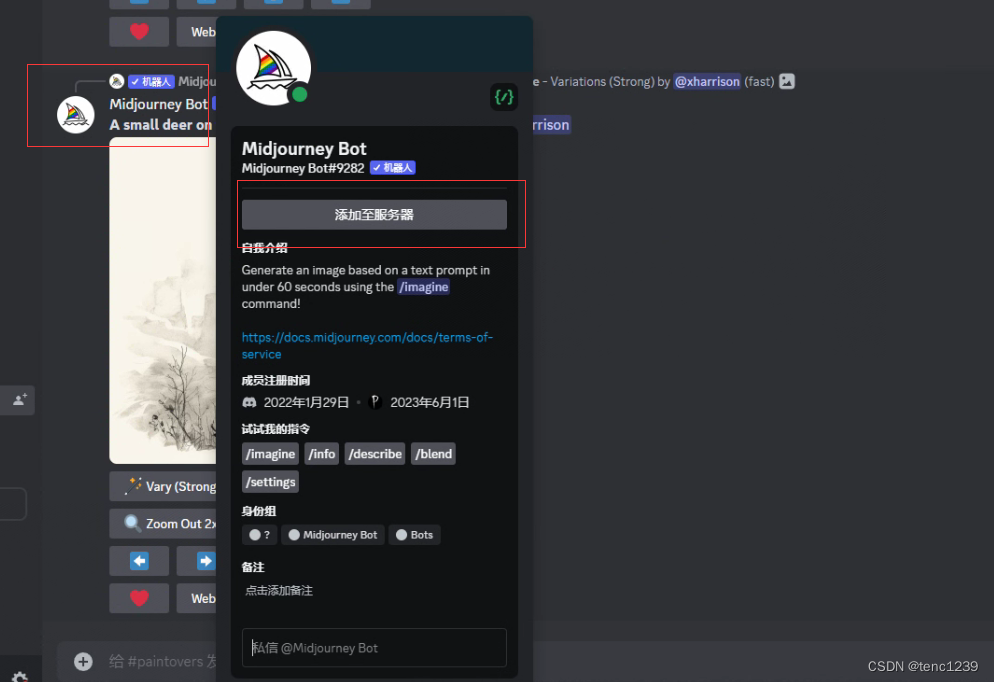
8 选择要添加的服务器

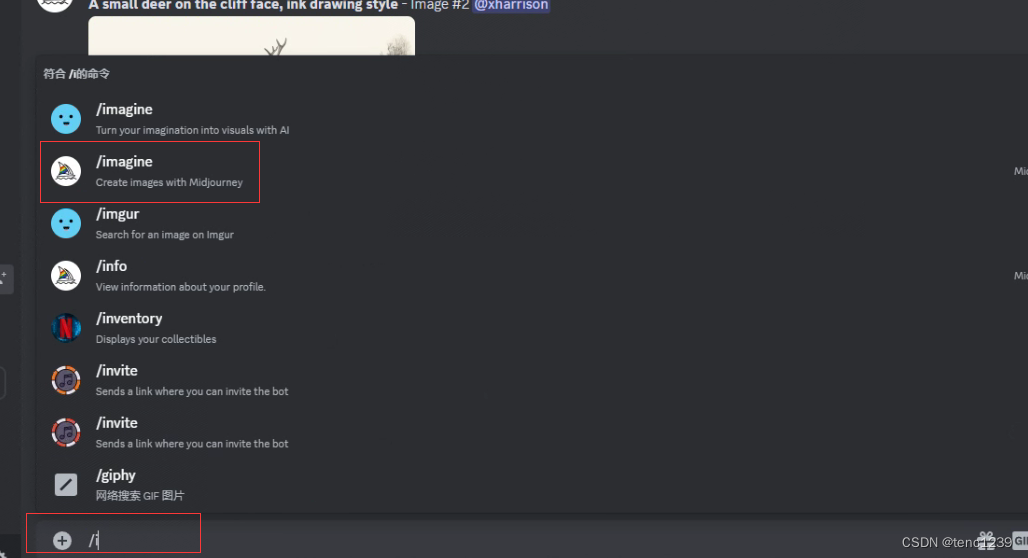
9 输入 / 选择 imagine 输入绘图内容
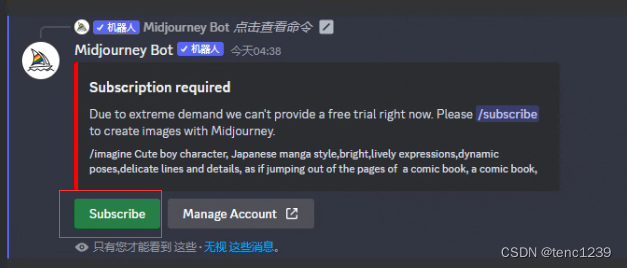
10 没有免费试用
11 点击后 进入了midjourney主页