seo网站推广服务自己做个网站的流程
协议与硬件概述
SPI
SPI是串行外设接口(Serial Peripheral Interface)的缩写。是一种高速的(10Mbps)的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线。
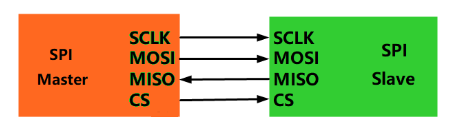
引脚介绍
- SCLK:串行时钟线,用于数据的同步。
- MOSI(
Master Output Slave Input):主机输出数据,从机输入数据。 - MISO(
Master Input Slave Output):主机输入数据,从机输出数据。 - CS:(芯)片选(择)引脚,引脚低电平,从机工作有效;引脚高电平,从机工作无效。
全双工通信的数据输出和数据输入是用同一个时钟信号同步的。时钟信号由主设备通过SCK脚提供。
主机不能同时与多个从机通信。多机通信时,从机之间共用SCLK、MOSI、MISO三个引脚,主机选定与哪一从机通信是拉低该从机的CS片选信号引脚。
在之前的“读取红外键码”中,需要通过设置GPIO初始为高电平,下降沿触发,通过中断处理函数获取有效数据。
在本文中,不需要配置具体的读取过程,只需要同GPIO_Init一样,创建一个结构体,通过Init方法初始化即可。
只是因为,这款开发板配备了相关的硬件。读写操作由硬件自动完成。
同样情况的还有之前出现的USART,开发板也配备了相关的硬件。写操作是直接通过USART_SendData(USART1,Byte);发送一个字节数据。手动实现的字节流和字符串输出函数,也是在调用这个方法。并没有像“显示红外键码”时那样按位操作。
红外键码中需要实现的操作比较多,是因为开发板没有相关协议的设备和寄存器,那个接收器只是用来接收38K滤波,判断0和1的。所以在读取时,可以用1MHz的TIM频率进行输入捕获,而无需关注信号在空中的38KHz,这一部分由硬件已经完成了。
MAX7219
LED点阵屏配备了MAX7219驱动电路。
通过SPI发送的数据就需要这一部分解释到点阵屏上。
硬件对外只暴露了5根线:VCC、GND、DIN、CS、CLK。
只有DIN没有提过:串行数据输入端。
其实就是MOSI,点阵屏没必要向主机发送数据,所以就省掉了MISO这根线。
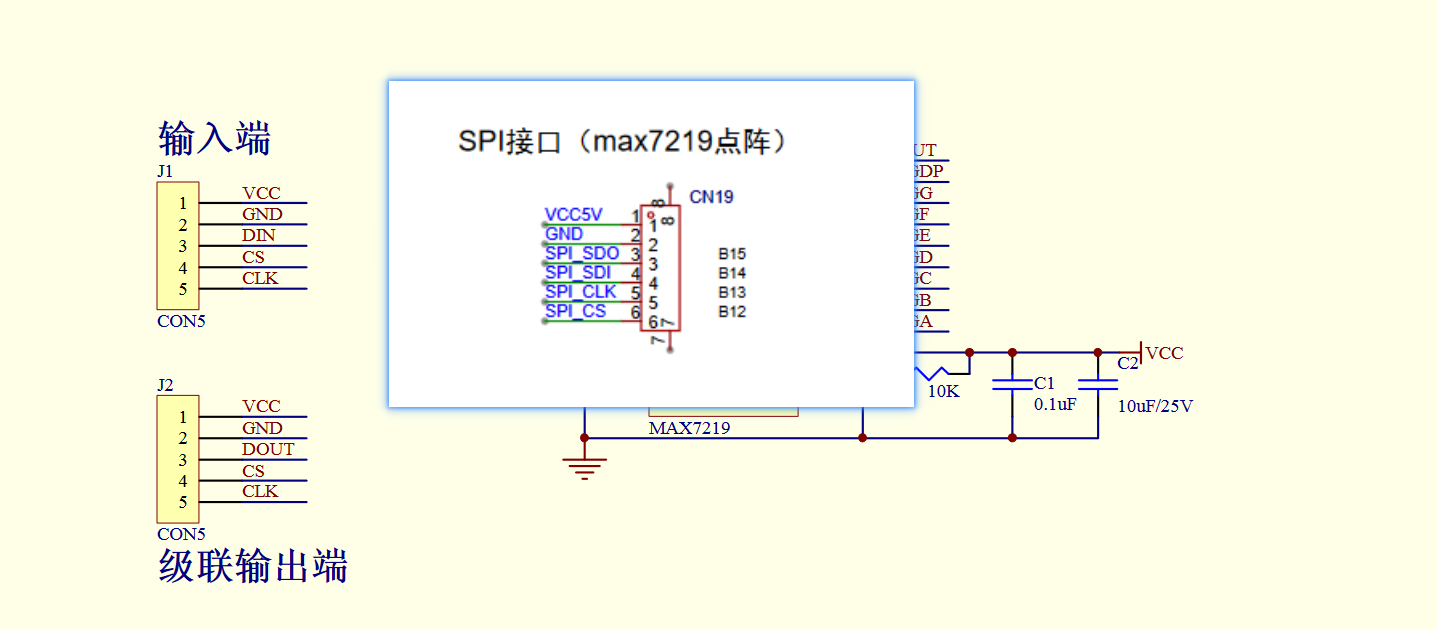
- 在SPI通信中,SDI通常是输出,SDO是输入。
接线时需要将点阵屏的DIN连接到SPI的SPI_SDI引脚,SPI的SPI_SDO引脚闲置即可,因为用不到读入数据。
MAX7219和单片计算机连接有三条引线(DIN、CLK、LOAD),采用16位数据串行移位接收方式。即单片机将16位二进制数逐位发送到DIN端,在CLK上升沿到来前准备就绪,CLK的每个上升沿将一位数据移入MAX7219内移位寄存器,当16位数据移入完,在LOAD引脚信号上升沿将16位数据装入MAX7219内的相应位置,在MAX7219内部硬件动态扫描显示控制电路作用下实现动态显示。
文字中的LOAD指的就是原理图中的CS。
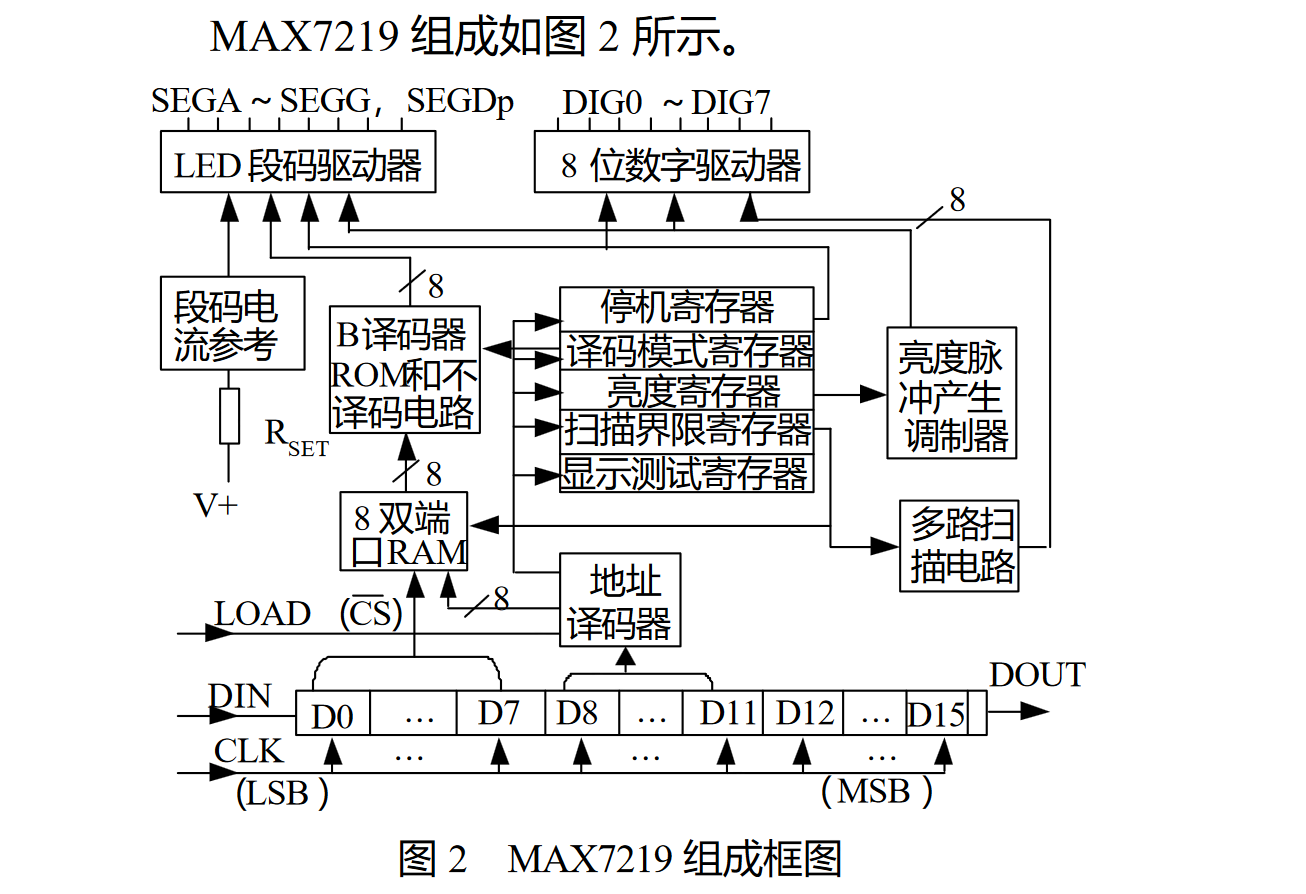
MAX7219是高位先行。先发送的第一个字节会作为地址,将第二个字节的数据写入到地址指向的寄存器。
接下来要做的,就是通过SPI协议,发送两个字节数据,第一个字节是地址,第二个字节是数据。
实现SPI控制LED点阵
SPI部分
SPI并没有直接控制灯的高低电平,而是告诉从机,让从机去实现。
初始化GPIO
先在原理图中找到对应引脚的接口:
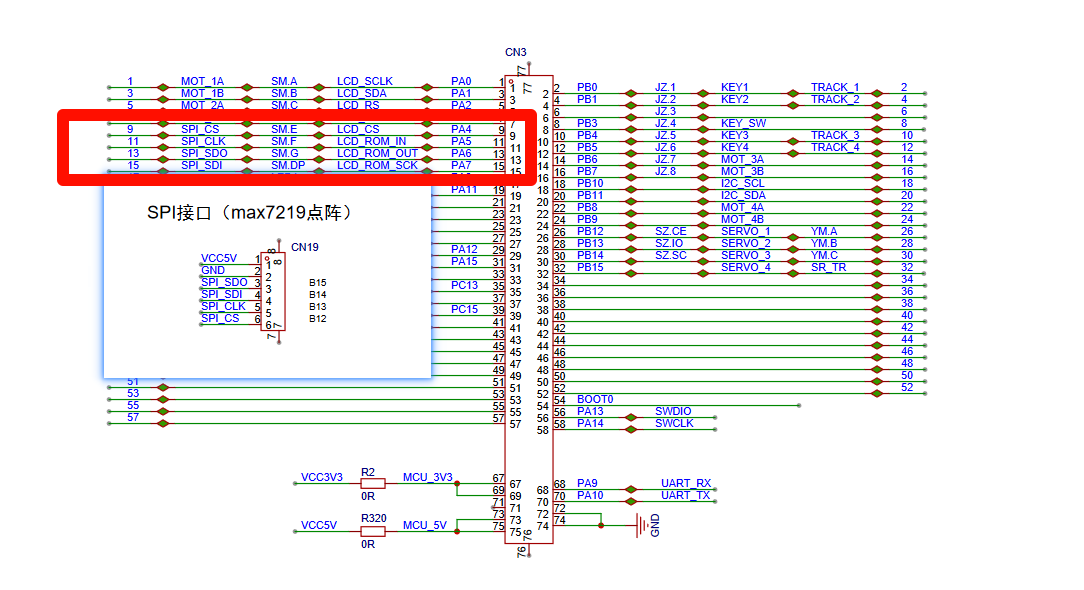
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA | RCC_APB2Periph_SPI1,ENABLE);GPIO_InitTypeDef GPIO_InitStructure;//MISO
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IPU;
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA,&GPIO_InitStructure);//SCK MOSI
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF_PP;
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_5|GPIO_Pin_7;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA,&GPIO_InitStructure);GPIO_SetBits(GPIOA,GPIO_Pin_5|GPIO_Pin_7);需要注意的就是:
- 原理图的SPO对应SPI协议的MISO,而非MOSI。
配置SPI
前面提到了,SPI已经被集成到这款开发板中,我们不需要手动去实现具体的位操作过程。
只需要创建一个SPI_InitTypeDef类型的结构体,把结构体的配置项都给填上就可以。
SPI_InitTypeDef SPI_InitStructure;
SPI_InitStructure.SPI_BaudRatePrescaler = SPI_BaudRatePrescaler_256;
SPI_InitStructure.SPI_CPOL = SPI_CPOL_Low;
SPI_InitStructure.SPI_CPHA = SPI_CPHA_1Edge;
SPI_InitStructure.SPI_DataSize = SPI_DataSize_8b;
SPI_InitStructure.SPI_Direction = SPI_Direction_2Lines_FullDuplex;
SPI_InitStructure.SPI_FirstBit = SPI_FirstBit_MSB;
SPI_InitStructure.SPI_CRCPolynomial = 7;
SPI_InitStructure.SPI_NSS = SPI_NSS_Soft;
SPI_InitStructure.SPI_Mode = SPI_Mode_Master;
SPI_Init(SPI1,&SPI_InitStructure);SPI_Cmd(SPI1,ENABLE);
上面的配置项需要在主机和从机之间提前约定好,才能有效地通信。
对于从机部分,已经焊死了。
我们需要对照从机的文档,对主机进行配置。
通过时钟极性CPOL和时钟相位CPHA来控制主设备的通信模式。
时钟极性CPOL定义时钟空闲状态的电平:
- CPOL=0:表示SCLK为0时处于空闲态,高电平时为有效态。
- CPOL=1:表示SCLK为1时处于空闲态,低电平时为有效态。
时钟相位CPHA定义数据的采集时间:
- CPHA=0:在时钟的第1个跳变沿进行数据采样,第2个边沿发送数据。
- CPHA=1:在时钟的第2个跳变沿进行数据采样,第1个边沿发送数据。
这两个选项需要对照从机的手册进行配置。
SPI_BaudRatePrescaler:波特率预分频器。SPI挂载在APB2上,为32MHz,需要调整到10Mhz以下。256分频也可以,因为用不到那么快的速度。
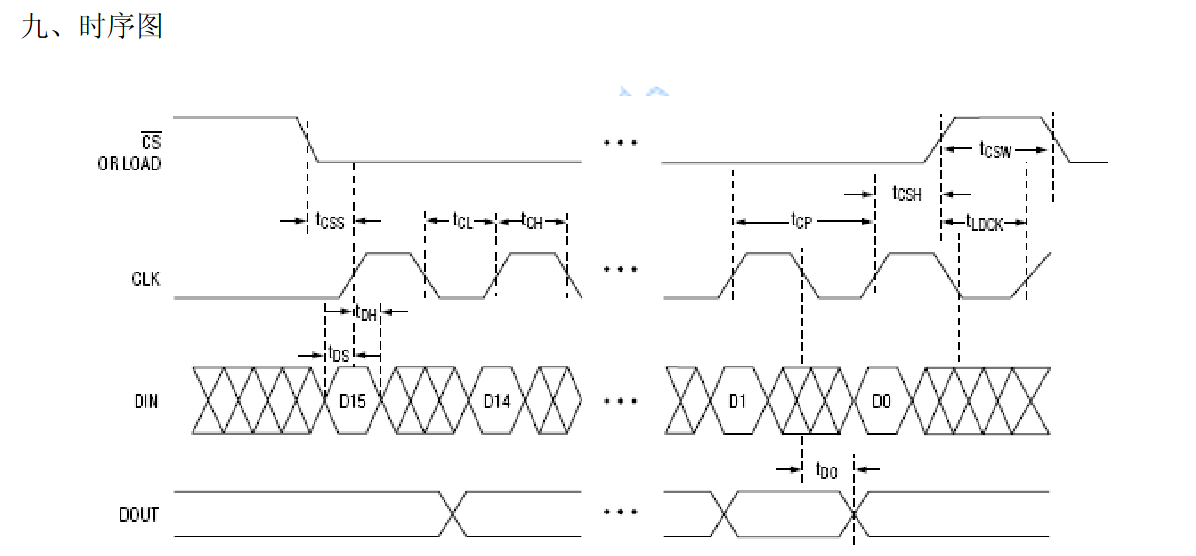
时序图中,空闲状态下,CLK是低电平,第一个上升沿将D15读入:
SPI_CPOL_Low和SPI_CPHA_1Edge
在时序图中,先到达的是D15,也就是高位。
主机数据的发送顺序也应是先发送高位,配置为SPI_FirstBit_MSB。
SPI_CRCPolynomial填写的是CRC校验公示的因子,设置为随机正数。
SPI_NSS设置由硬件控制还是软件控制。在此设置为软件(据课程老师说更常用)。
发送数据
这是SPI部分,看上去跟之前写的USART没有什么区别。
void SPI1_WriteByte(uint8_t TxData)
{while(SPI_I2S_GetFlagStatus(SPI1,SPI_I2S_FLAG_TXE) == RESET);SPI_I2S_SendData(SPI1,TxData);
}
MAX7219部分
上面只是SPI方面的配置和使用。SPI是通信协议,我们要通过这个协议来告诉从机改干什么。
最开始有提到过,但从未使用的CS,现在有用了:在需要通信时拉低,告诉从机,传输要开始了。
需要先初始化相关的引脚:
void MAX7219_CS_Init()
{RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA,ENABLE);GPIO_InitTypeDef GPIO_InitStructure;GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP;GPIO_InitStructure.GPIO_Pin = GPIO_Pin_4;GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOA,&GPIO_InitStructure);GPIO_SetBits(GPIOA,GPIO_Pin_4);
}利用位带修改引脚的值。
void Write_MAX7219(uint8_t addr,uint8_t data)
{PAout(4) = 0;SPI1_WriteByte(addr);SPI1_WriteByte(data);Delay_ms(1);PAout(4) = 1;
}
写完数据,从机未必成功读完,需要给从机一点时间响应。
写成发送两次8字节,是因为这样更加直观。
设置显示选项
点阵屏的亮度、开关也可以设置。
在板载的硬件中,可以通过stm32提供的库函数修改。
在这种外设条件下,主机和从机之间的联系方式只有目前的SPI。
通过SPI发送2字节数据,第一个字节指定地址,第二个字节指定该地址填入的数据。
各内部功能寄存器含义如下:
- 停机寄存器(地址0CH):当D0=0时,MAX721处于停机状态;当D0=1时,处于正常工作状态。
- 显示测试寄存器(地址0FH):当D0=0时,MAX7219按设定模式正常工作;当D0=1时,处于测试状态。在该状态下,不管MAX7219处于什么模式,全部LED将按最大亮度显示。
- 亮度寄存器(地址0AH):亮度可以用硬件和软件两种方法调节。亮度寄存器中的D0~D3位可以控制LED显示器的亮度。
- 扫描界限寄存器(地址0BH):该寄存器中D0~D3位数据设定值为0~7H,设定值表示显示器动态扫描个数位1~8。
- 译码方式寄存器(地址09H):该寄存器的8位二进制数的各位分别控制8个LED显示器的译码方式。当高电平时,选择BCD-B译码模式,当低电平时选择不译码模式(即送来数据为字型码)。
- 内部RAM地址01~08H分别对应于DIG0~DIG7。
也就是说,通过SPI协议向指定的位置写值,实现修改设置和数据。
void MAX7219_Init()
{SPI1_Init();MAX7219_CS_Init();Write_MAX7219(0x0C,0x01);Write_MAX7219(0x0F,0x00);Write_MAX7219(0x0A,0x0f);Write_MAX7219(0x0B,0x07);Write_MAX7219(0x09,0x00);
}
对照上面的寄存器含义,该代码的含义为:
- 停机寄存器:正常工作状态
- 测试寄存器:按设定正常工作
- 亮度寄存器:最大亮度显示
- 扫描界限寄存器:显示到第8列,即全部显示
- 译码方式寄存器:不译码,送来什么就显示什么
主函数显示笑脸
不同于点亮数码管。点亮数码管需要快速刷新,在一个瞬间只能点亮一个数字。停止刷新就不再显示。
该点阵屏的点亮是通过往寄存器写值,刷新显示操作交由外设硬件。只要寄存器值不变,现实的内容就不变 。我们只需要写一次数据即可。
uint8_t smile[8] = {0x3C,0x42,0xA5,0x81,0xA5,0x99,0x42,0x3C};
int main(void)
{MAX7219_Init();uint8_t i = 0;for(i = 1; i <=8; i++){Write_MAX7219(i,smile[i-1]);}while(1){}
}
参考
- MAX7219点阵原理图.pdf
- MAX7219中文.pdf
- MAX7219原理及其应用.pdf
- stm32 使用说明+笔记(必读).pdf
- 32版开发板原理图.pdf