芜湖网站建设工作室资料员报名入口官网
在数字化时代,我们每天都在与各种文件打交道。无论是工作文档、个人照片还是多媒体资料,管理这些文件的效率直接关系到我们的工作效率和生活体验。今天,我要向大家推荐一款功能强大、操作简便的文件管理软件 —— XYplorer。
XYplorer:您的智能文件管家
XYplorer 是一款专为 Windows 系统设计的文件管理工具,它以其快速、强大、美观和易用性而著称。自 1993 年首次发布以来,XYplorer 已经在全球 140 多个国家和地区被广泛使用,服务了超过 25 年的用户。

一、便携性:随时随地的文件管理
XYplorer 是一款便携式软件,无需安装,所有设置都存储在应用程序数据文件夹中,运行时不会更改您的系统或注册表。这意味着您可以将它存储在 USB 闪存驱动器上,随身携带,实现真正的“文件管理随行”。
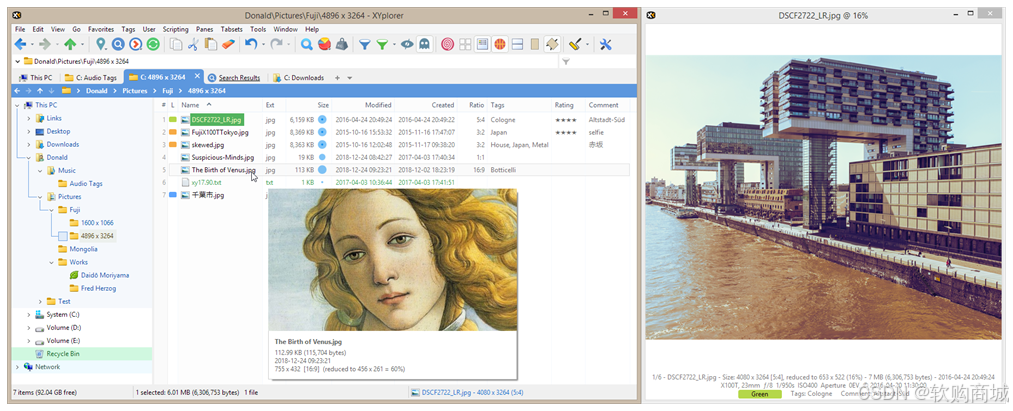
二、标签式浏览:高效管理文件夹
XYplorer 的标签式浏览功能,让您可以轻松地在不同文件夹之间切换。您可以拖动标签、隐藏标签、锁定标签、命名标签,甚至可以直接将文件拖放到标签上。标签会记住它们的配置,无论是在当前会话还是跨会话,都能保持一致。
三、功能丰富:提升工作效率
XYplorer 的设计宗旨是提高您的工作效率。它拥有众多的可用性增强功能,如文件搜索、预览、自定义界面、双窗格视图等,这些都有助于简化您的工作流程,提高效率。
四、脚本化:自定义您的工作流程
XYplorer 支持脚本化,这意味着您可以为特定的任务编写自定义解决方案。无需插件,脚本即可直接运行,即使是初学者也能从中受益,因为论坛中有许多现成的脚本可供使用。
五、速度与可靠性:性能与稳定性的保证
XYplorer 始终将速度作为主要设计目标。代码不断优化以提高性能,对慢速零容忍。此外,该应用程序占用的 RAM 非常少,可执行文件体积小(仅 10MB),几乎可以瞬间加载。
六、高度可定制:打造个性化体验
您可以根据自己的喜好调整 XYplorer 的外观和行为。从字体和颜色到自定义工具栏按钮、文件图标和程序快捷方式,一切都可以完全便携。
七、响应迅速:用户反馈的快速响应
XYplorer 的开发团队非常重视用户的声音,您的意见和反馈通常会得到快速的响应,并且您的建议很可能会被迅速实施。
八、免费试用:30 天的全面体验
XYplorer 提供免费的 30 天试用版,您可以在这段时间内全面体验这款软件的强大功能。试用版功能全面,限制极少。
如果您正在寻找一款能够提高文件管理效率、提升工作流程的软件,XYplorer 无疑是您的理想选择。它不仅功能全面,而且操作简便,是您日常工作和生活中的得力助手。立即下载 XYplorer,开启您的智能文件管理之旅吧!
新手快速入门指南 – XYplorer 双栏多标签文件资源管理器软件丨中文网站