如何创建网站和域名广东东莞公司有哪些
在前后端分离开发架构下,经常遇到调用后端数据API接口进行测试、集成、联调等需求,比如:
(1)前端开发人员很快开发完成了UI界面,但后端开发人员的API接口还没有完成,不能进行前后端数据接口对接和联调,很容易影响开发进度。前端开发人员用的比较多的开源组件有mock.js,但该组件缺乏界面管理,因为这样做很容易造成代码耦合,甚至一不小心就会把Mock代码打包到生产环境。
(2)在一些数据大屏可视化、报表开发、调用远程服务等业务场景中,常常需要远程http接口数据的支撑,往往把JSON数据写死到代码里,或者通过spring mvc开发数据接口,这些工作都比较耗时,且日后不好更改和维护。当然,也可以使用开源软件json-server用于模拟服务端接口数据,根据json数据建立一个完整的web服务。JSON-Server 是一个 Node 模块,运行 Express 服务器,你可以指定一个 json 文件作为 api 的数据源。
以下介绍两种快速调用数据mock接口的方式,一种是使用在线免费的http接口,另一种是基于数据mock工具动态生成接口。
一、 免费在线HTTP服务接口,模拟假数据
JSONPlaceholder 是一个提供免费的在线 REST API 的网站,我们在开发时可以使用它提供的 url 地址测试下网络请求以及请求参数。当我们程序需要获取一些假数据、假图片或者mock数据接口时可以使用它。其返回的数据为 JSON 格式,且同时支持 HTTP 和 HTTPS 这两种请求类型,支持跨域,如 CORS 和 JSONP,支持GET、POST、PUT、PATCH、DELETE 几个请求方法。网站地址:JSONPlaceholder - Free Fake REST API
以下示例均通过了Postman测试,模拟了GET请求多条数据接口、单条数据接口、大量数据接口、图片资源接口、restful风格参数接口、url带?参数接口、返回复杂JSON数据格式接口等,方便前端开发人员开始测试或者mock数据时使用。
1、获取100篇文章数据(GET无参数请求)
返回100条数据,每条内容都有帖子 ID、发贴人 ID、标题、以及简介。
http://jsonplaceholder.typicode.com/posts
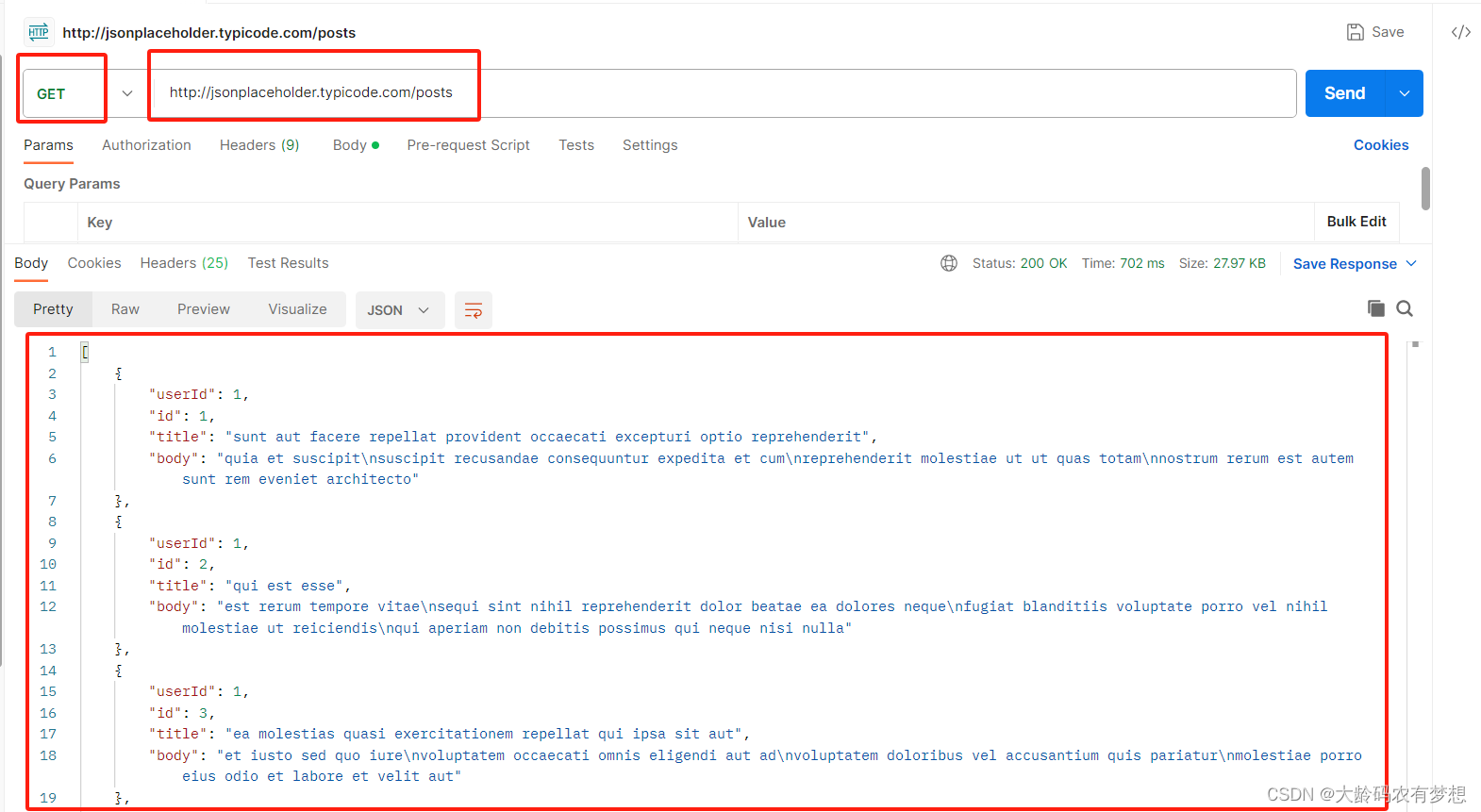
2、根据文章ID获取文章数据(GET带restful风格参数)
根据文章 ID 获取指定文章的数据,传递的参数为restful风格参数。
返回:文章 ID、发贴人 ID、标题、以及内容。
http://jsonplaceholder.typicode.com/posts/3
本例传入的 ID 为3,返回 ID 为3的数据。
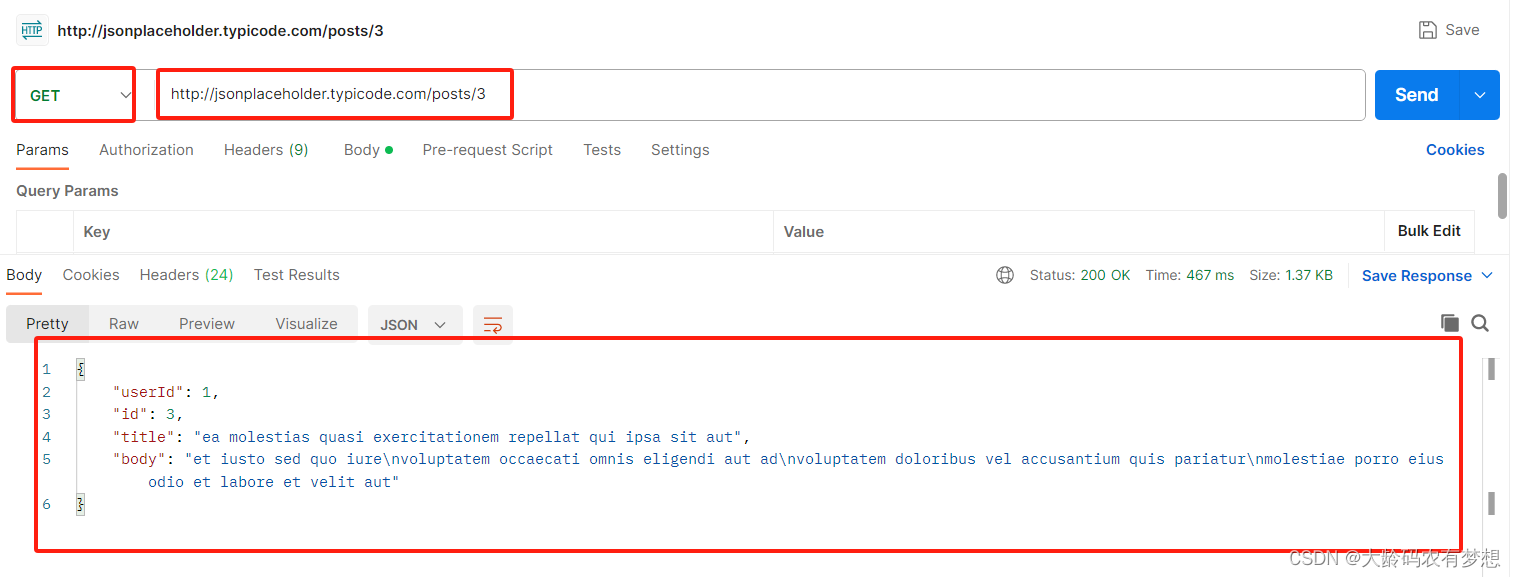
3、获取某个用户所有的帖子(GET带?风格参数)
根据用户 ID 获取指定用户的数据,传递的产生为url中带问号的风格
https://jsonplaceholder.typicode.com/posts?userId=2

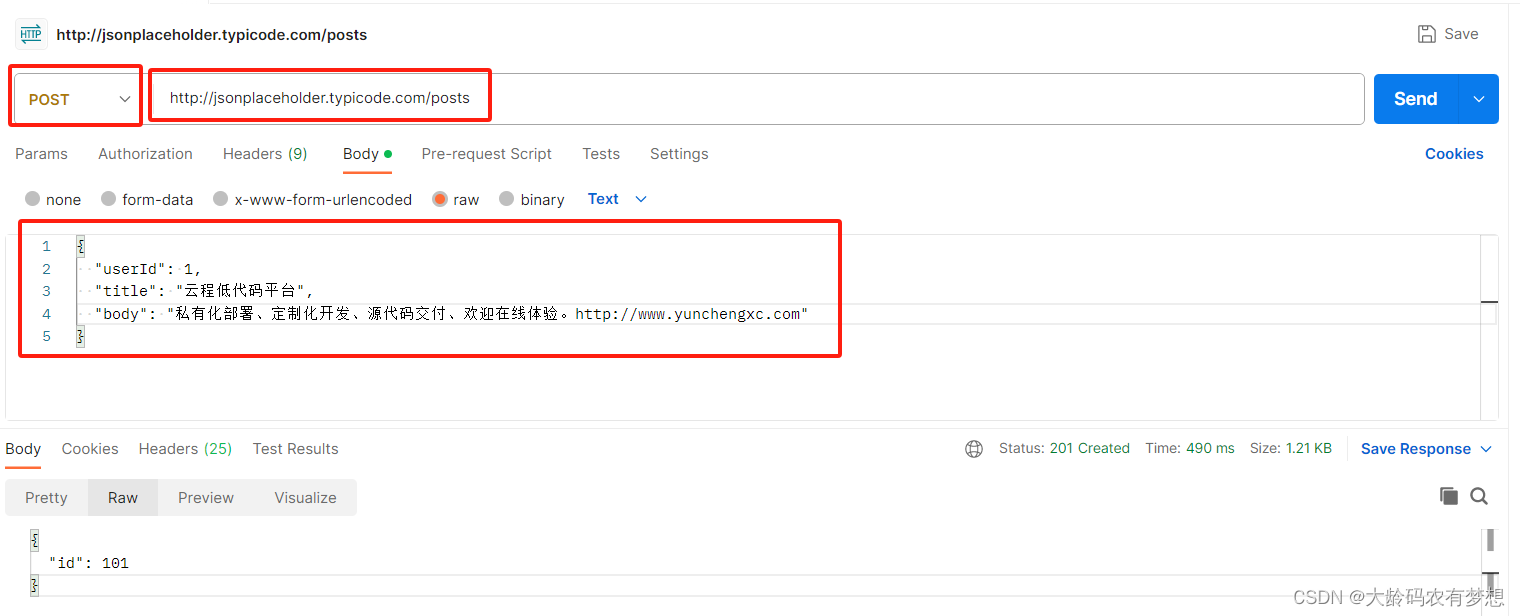
4、添加文章(POST请求,模拟提交JSON数据)
使用 POST 发送一篇文章,发送成功会返回一个文章 ID 回来。
http://jsonplaceholder.typicode.com/posts
提交的内容为JSON格式,比如:
{
"userId": 1,
"title": "云程低代码平台",
"body": "私有化部署、定制化开发、源代码交付、欢迎在线体验。http://www.yunchengxc.com"
}
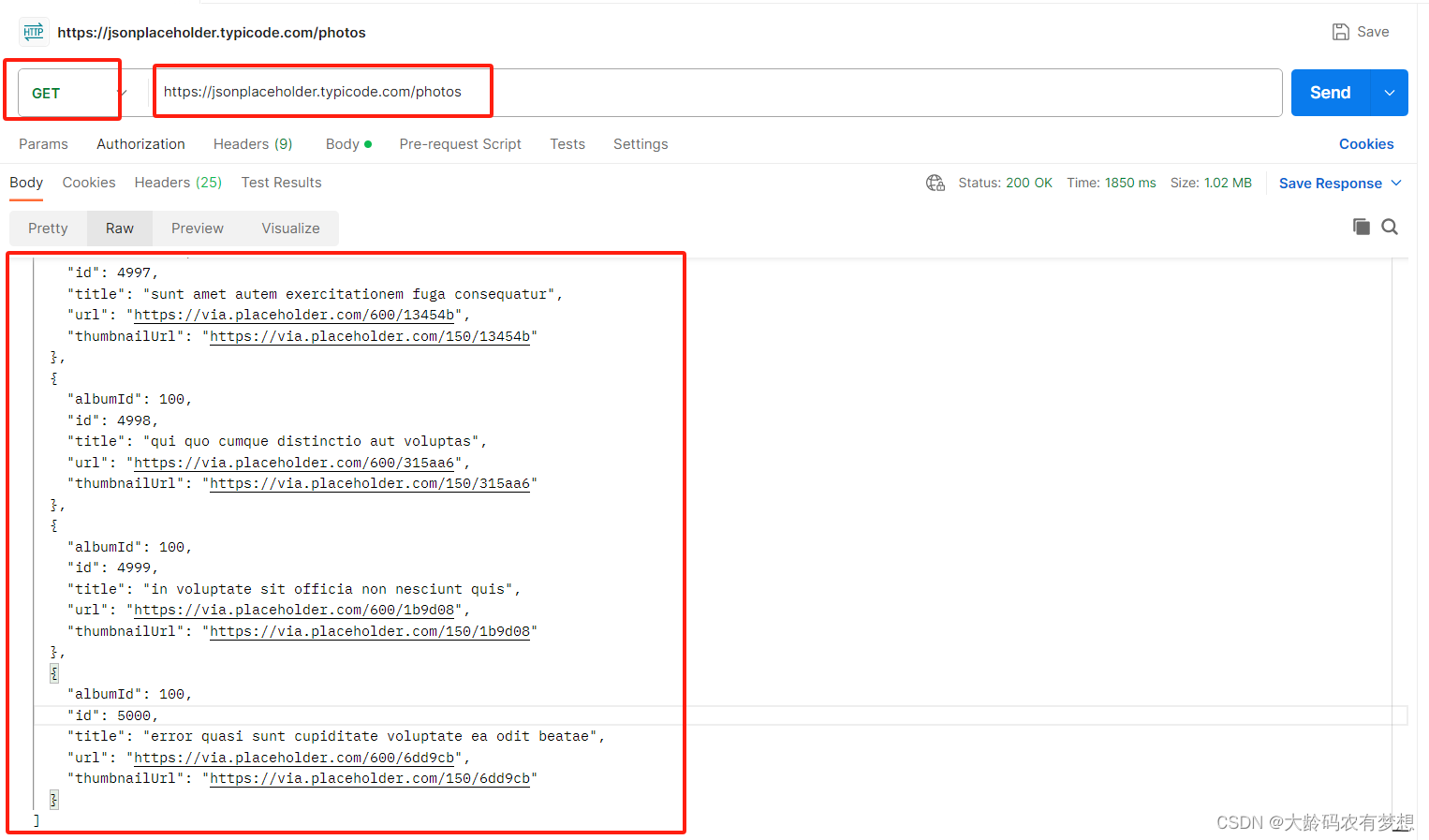
5、获取5000条人员数据(GET请求模拟大数据量一次性返回)
返回5000条数据,每条内容都有标题、图片URL、缩略图URL,用于测试图片显示的场景。
https://jsonplaceholder.typicode.com/photos
6、获取单条人员数据带图片URL(GET请求,返回图片URL)
返回单条数据,内容都有标题、图片URL、缩略图URL,用于测试图片显示的场景。
https://jsonplaceholder.typicode.com/photos/5

7、随机返回一张照片资源(GET请求,直接返回图片资源)
『Lorem Picsum』 可以随机返回一张照片资源,还可以指定照片的尺寸,可以直接放在 <img> 标签的 src 属性内使用。
https://picsum.photos/400/300
返回宽400,高300的一张图片

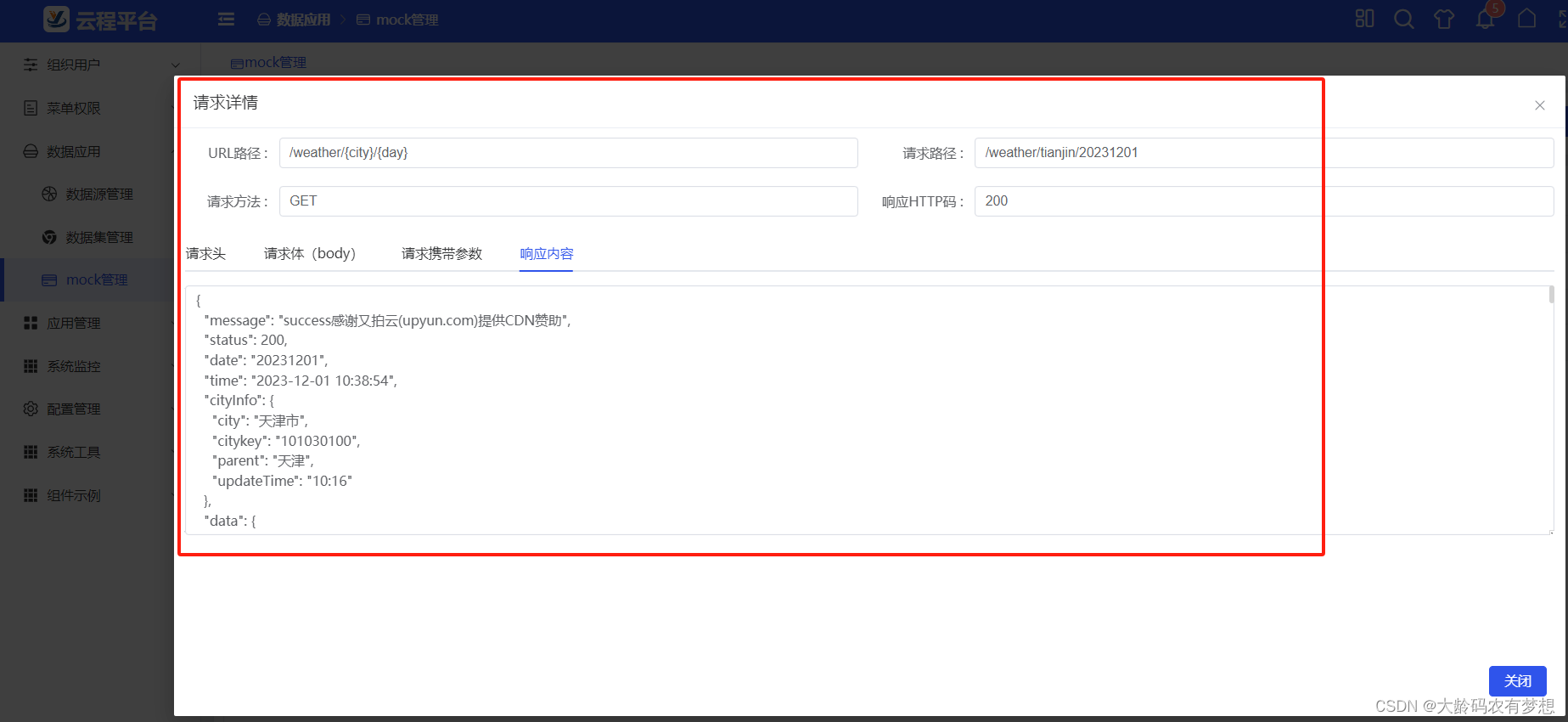
8、获取某个城市的天气预报(GET请求,返回复杂JSON格式数据)
天气API 数据(以天津为例),链接为:http://t.weather.sojson.com/api/weather/city/101030100
返回成功状态(status)为:200 ,失败为非200,返回的JSON数据格式包括多个嵌套,用于测试比较复杂JSON格式的前端处理。注意,该接口不支持跨域。

二、数据MOCK接口管理工具
以上免费在线http数据接口返回值是固定格式的,仅能满足mock假数据的场景,在实际的开发场景中常常需要动态构建业务规定的数据格式,而且需要有管理界面维护数据mock接口。
云程低代码平台提供了API接口mock管理功能,可在线配置HTTP数据接口,灵活构建业务需要的数据格式,基于HTTP方式一键发布出去,用于前后端接口数据联调,以及给大屏、报表快速提供数据接口等应用需求。
mock接口在线管理:

通过postman测试http接口:

查看接口调用日志:
在线免费测试体验:http://www.yunchengxc.com