西安做网站的公司地址产品开发思路
原型链
- 1、概念
- 2、原理
- 3、new 操作符原理
- 4、应用
1、概念
原型链:javascript的继承机制,是指获取JavaScript对象的属性会顺着其_proto_的指向寻找,直至找到Object.prototype上。
2、原理
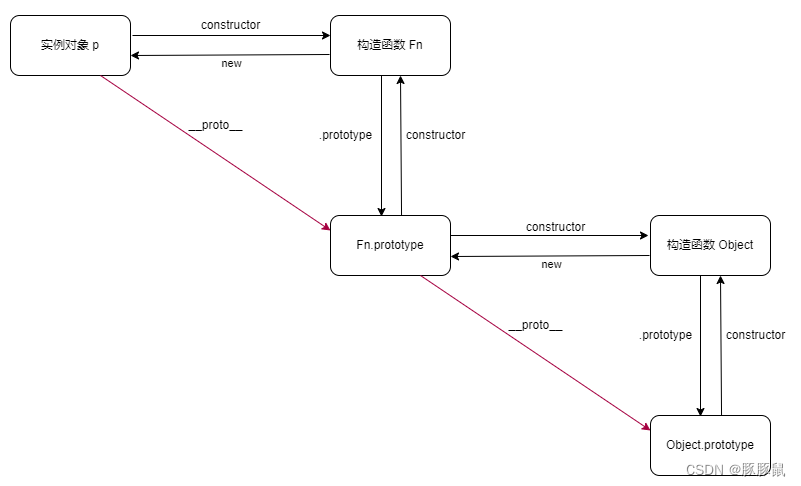
💡 Tips:构造函数 Fn, p 为 new Fn 的实例对象,p 有一个属性 proto 指向了 Fn.prototype,形成原型链。
function Fn(name) {this.name = name;
}
Fn.prototype.run = function () {console.log('run run run ' + this.name);
};let obj2 = new Fn('tom');
obj2.run();
console.log(obj2.__proto__ === Fn.prototype); // true
console.log(Fn.prototype.constructor === Fn); // true
console.log(obj2.constructor === Fn); // true
原型链示意图:
3、new 操作符原理
function Fn(name, age) {this.name = namethis.age = age
}
Fn.prototype.sayName = function () {return this.name
}
var obj = myNew(Fn, "zcf", 18)
obj.sayName() // "zcf"function myNew() {//第一步新建一个对象var obj = {}// 第二步,拿到构造函数var constructor = [].shift.call(arguments)// 将obj的原型指向构造函数的原型,这样obj就可以访问构造函数原型中的属性了obj.__proto__ = constructor.prototype// 使用apply改变构造函数this指向obj,这样obj就可以访问构造函数原型中的属性了var ret = constructor.apply(obj, arguments)// 要返回objreturn typeof ret === "object" ? ret : obj
}
4、应用
将属性挂载到实例对象上,将公共方法挂载到构造函数的原型上,减少每次 new 时,都需要创建方法,多消耗堆内存。