网站开发全栈工程师技能图南昌知名的网站建设公司
个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【MySQL学习专栏】🎈
本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌

目录
- 一、数据库约束类型
- not null
- unique
- default
- 主键约束
- 外键约束
- 二、表的设计
- 一对一
- 一对多
- 多对多
- 三、新增
- 四、查询(进阶)
- 聚合函数
- 分组查询(group by)
一、数据库约束类型
约束:对数据库中的数据进行检查和校验,保证数据是有效、合法的。
约束是mysql提供的一个机制,辅助我们自动的依赖程序来对数据进行检查,检查我们想要修改的数据到底又不有效、合不合法,一旦检查出不合法或者无效数据,mysql就会进行报错。
以下是mysql的约束类型:
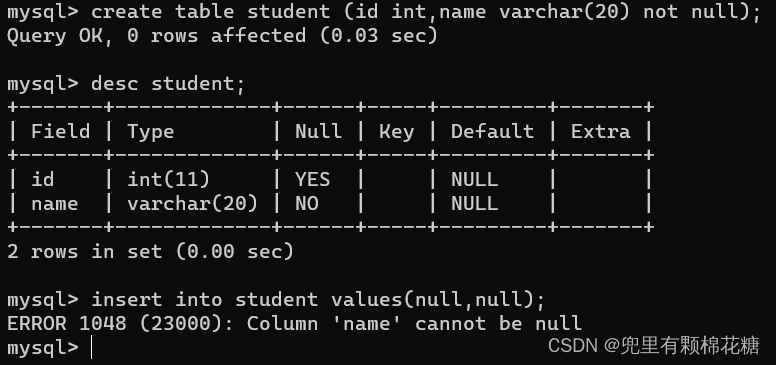
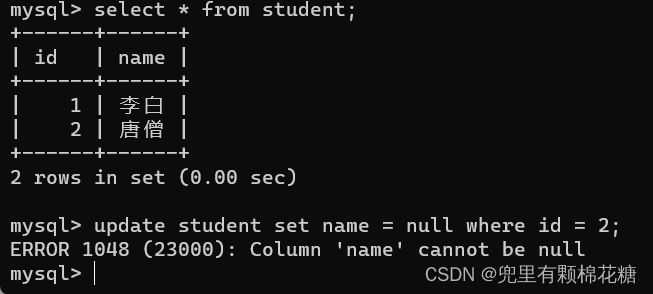
- not null:指定某一列不能存储null值。
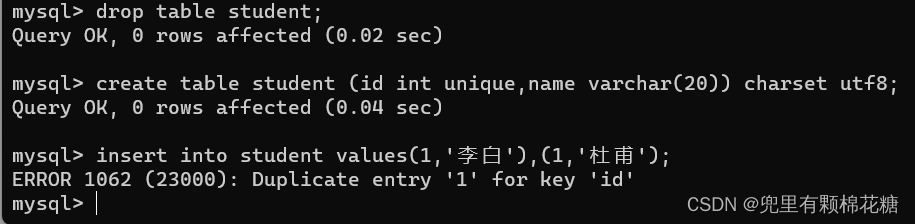
- unique:保证某列的每一行必须是唯一的值(简单来说就是不同行的相同列不能重复)。
- default:规定没有给列赋值时的默认值。
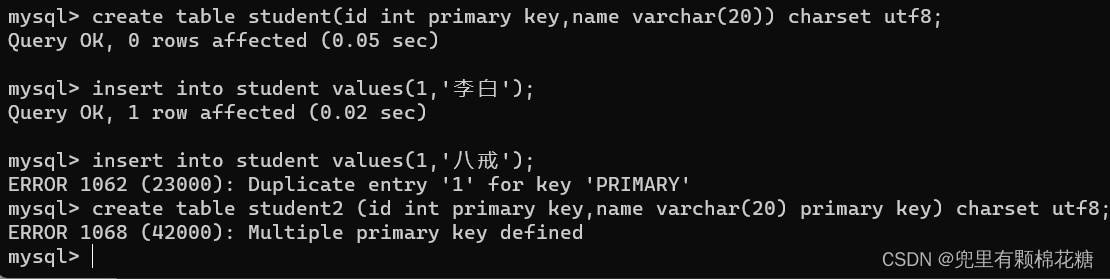
- primary key(主键):
- auto_increment:自增主键
not null
nut null演示:
unique
unique演示:
通过额外的查询操作来确保不会出现重复数据,当然这个查询操作肯定是要付出代价的(代价就是会消耗额外的时间)。
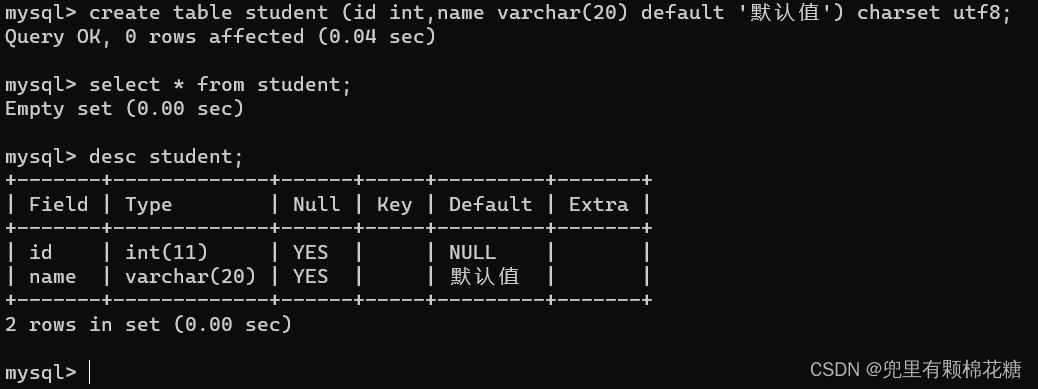
default
default演示:
primary key演示:
主键一般是整数类型的id,一个表中只能有一个主键。mysql允许客户端再插入数据的时候不手动指定主键的值,而是交给mysql指定分配指定的值,这样可以保证分配出来的主键的值是不会出现重复的(分配方式就是按照自增的方式来分配主键的值;注意自增主键必须搭配i整数类型的主键去进行使用)。
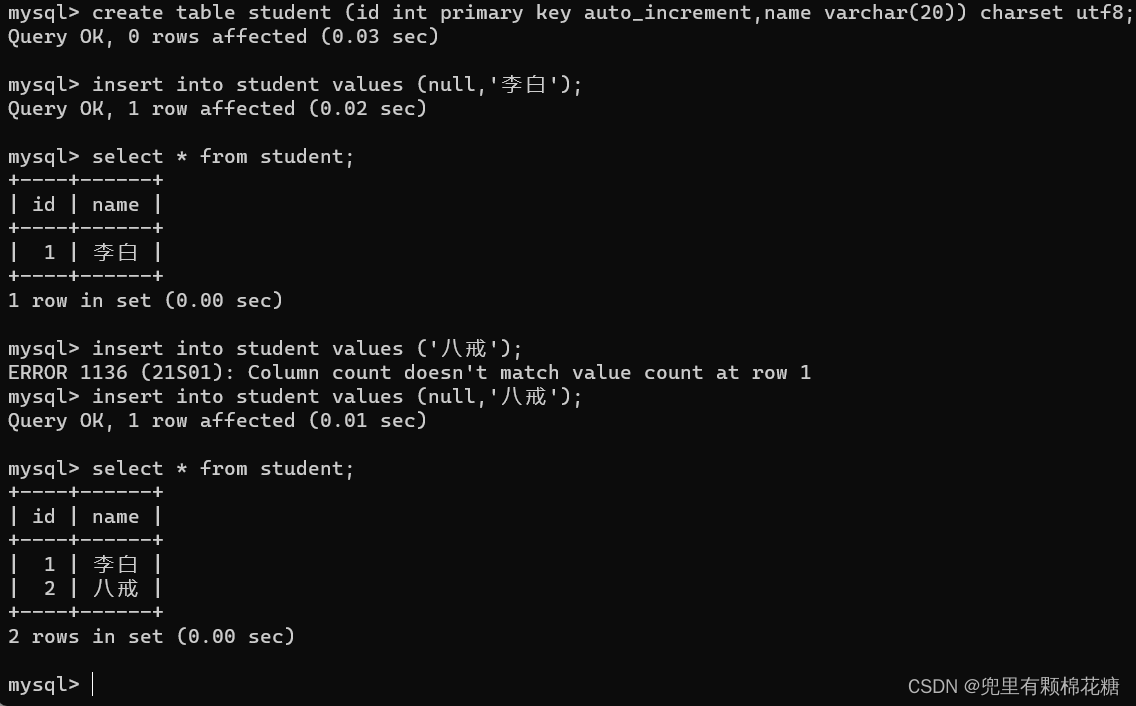
主键约束
primary key auto_increment(自增主键)演示:
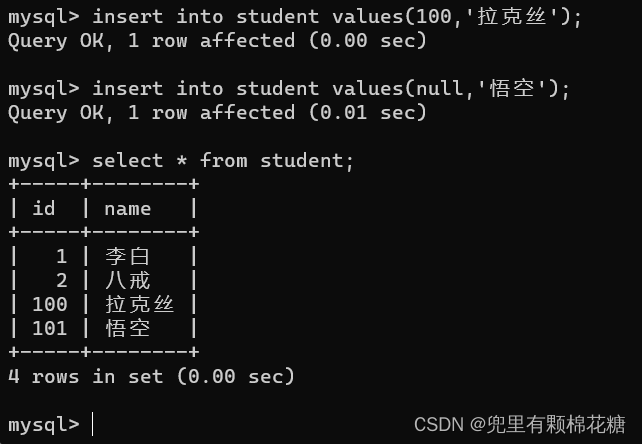
自增主键也可以自己手动设置,下次mysql分配的主键就会在之间最大值的基础上继续自增
自增主键可以设置为null值(因为自增主键是由mysql自行去分配给客户端的),但是主键不可以设置为null值。
mysql会维护自增主键的这样一个最大值:
如果mysql是一个单个节点的系统,mysql是可以正常维护自增主键;
但是如果mysql是一个分布式系统,此时自增主键不能保证id的唯一性(因为每个主机上的mysql只知道自己存储的自增主键的最大值而不知道其它节点的情况,此时就有可能出现id重复的情况),所以要想分为这种表示唯一性的id的话,就不能依赖自增主键了。
所以了解决上述无法保证生成的id唯一性的问题,就出现了分布式id的生成算法,目的就是为了保证系统中的每个节点生成的id是唯一的。算法核心公式如下:
把id作为一个字符串,这个字符串一般由三部分拼接成:①主机编号/机房编号;②时间戳;③随即因子(生成随机数)。此时生成的字符串格式的id就能够保证分布式系统下的唯一性了。
外键约束
foreign key(外键约束)演示:
创建外键约束的时候要明确谁(哪个表的哪一列)受到谁(哪个表的哪一列)的约束。

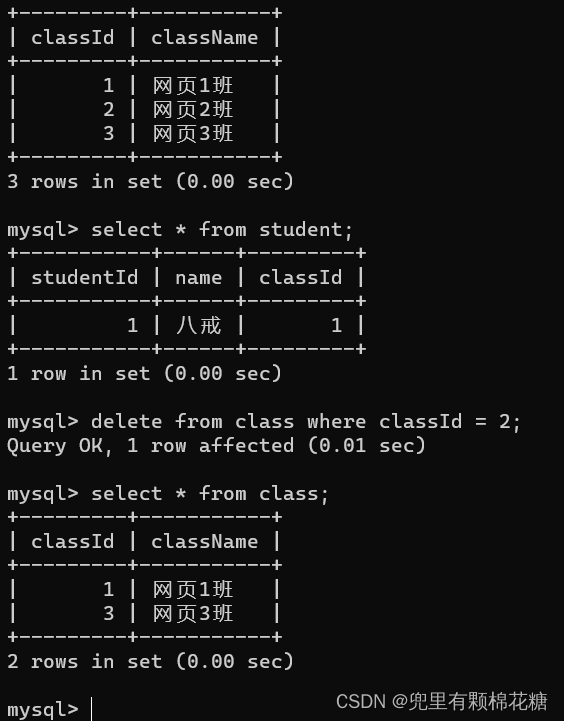


外键约束建表语句样例:
// 创建外键约束的时候,父表的代码不受到影响,受到影响的是子表的代码。create table class(classId int primary key,className varchar(20)) charset utf8;insert into class values(1,'网页1班');insert into class values(2,'网页2班');insert into class values(3,'网页3班');
create table student(studentId int primary key auto_increment,name varchar(20),classId int,foreign key(classId) references class(classId)) charset utf8;// 1.插入或者修改子表中受约束的这一列的数据就需要保证插入/修改后的结果得在父表中存在
// 以上述外键约束为例:在子表student插入的记录,其中的classId必须要在父表即class表中存在
// 针对这种外键约束的插入或者修改会触发查找操作在父表进行查询// 2.删除或者修改父表中的数据需要看看这个记录是否在子表被使用了,如果被使用了则不能删除或者修改。
// 即约束通常是双向的// 3.设置外键的时候就会导致我们在操作子表的时候频繁的查询父表(非常的耗时),如果id这一列有
// 索引的话就会一定程度提高查询速度,而primary key和unique是自带索引的。
// 同时mysql规定如果没有索引就不能设置外键
二、表的设计
现在我们讨论比较基础的设计表的方法原则。我们要设计数据库的表就需要先把实体和关系梳理清楚。
关系就是实体与实体之间的关联关系。
关于数据库的关系有三种:一对一、一对多、多对多。
一对一
比如学校的教务系统,每个学生只能有一个教务系统账号,且这个教务系统账号只能归一个学生所有。
有三种建表方式来满足此场景的一对一的关系,请看:
// 方式一:
student(studentId,name,age,classId,......)
acount(accountId,username,password,studentId,......)// 方式二:
student(studentId,name,age,acountId,......)
acount(accountId,username,password,......)// 方式三:
student(studentId,name,username,password,......)
一对多
我们还是以学校的教务系统为例,比如一个同学只能存在于一个班级中,但是一个班级可以包含很多个同学。
满足此场景的建表方式如下:
class(classId,className)1 '网页一班'2 '网页二班'
student(studentId,name,classId)1 '李白' 12 '杜甫' 13 '杜牧' 2多对多
多对多中要想描述多对多的关系,一般都会引入一个关联表来进行描述。如下进行举例,请看:
student(studentId,name)1 '李白'2 '杜甫'3 '唐僧'
course(courseId,coursename)101 '语文'102 '数学'103 '英语'104 '科学'
student_course(studentId,courseId)1 1021 1011 1032 1022 1033 1013 1023 1033 104
如果两张表之间没有任何关联关系,即两张表之间完全独立,互不影响。
三、新增
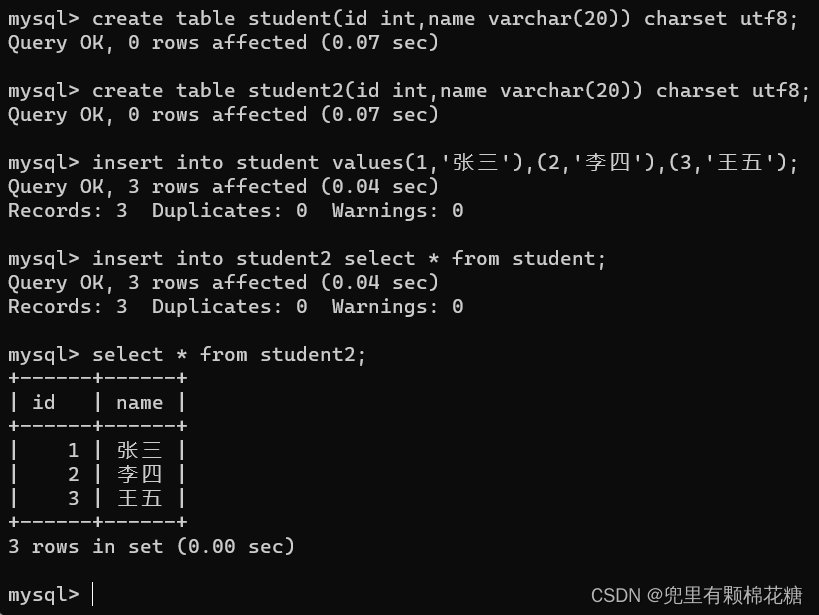
select into table_name [(column [,column,......])] select ......;
// select查询出来的结果需要和要插入的表能够匹配上(列的数目、类型、约束等)
举例如下:
四、查询(进阶)
聚合函数
聚合查询简单来说就是把行和行之间的数据进行运算(针对的是所有行进行运算)。
| 函数 | 说明 |
|---|---|
| count()[distinct] expr | 返回查询到的数据的数量 |
| sum([distinct] expr) | 返回查询到的数据的总和(只针对数字) |
| avg([distinct] expr) | 返回查询到的数据的平均值(只针对数字) |
| max([distinct expr]) | 返回查询到的数据的最大值(只针对数字) |
| min([distinct] expr) | 返回查询到的数据的最小值(只针对数字) |
在sql中,聚合函数和空格是紧紧挨在一起的。
下面我们来进行举例,请看:
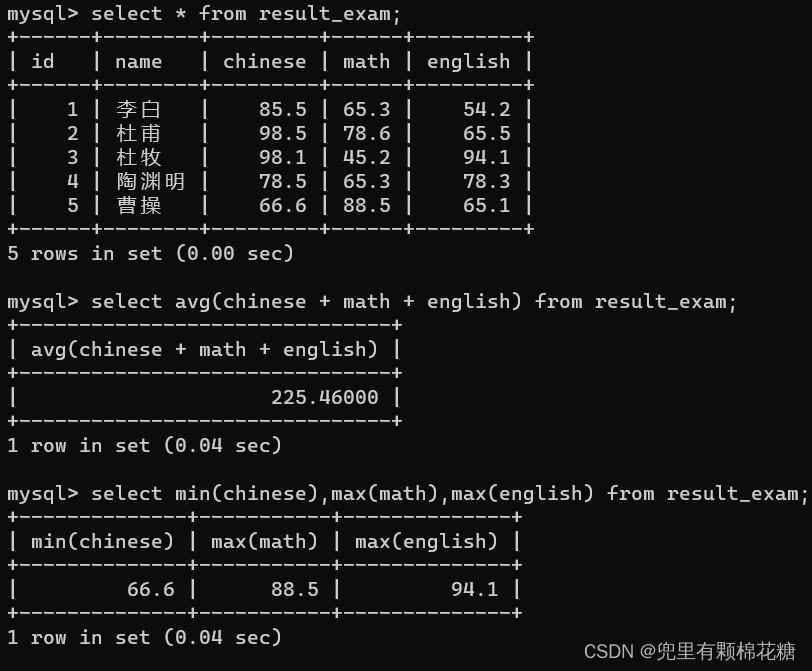
// 统计学生表中有多少个学上
select count(*) from student; // 方式一
select count(0) from student; // 方式二// 统计学生表中的若干行。
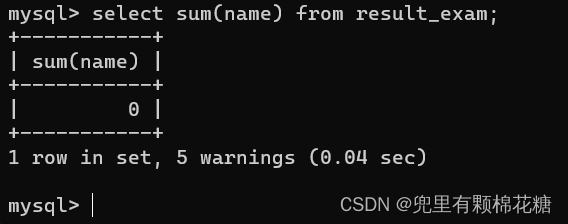
select sum(chinese) from student; // 求和会把这一列的若干行按照double的方式进行累加
当我们把字符串类型的值进行相加的时候,就会出现下面这种情况,请看:
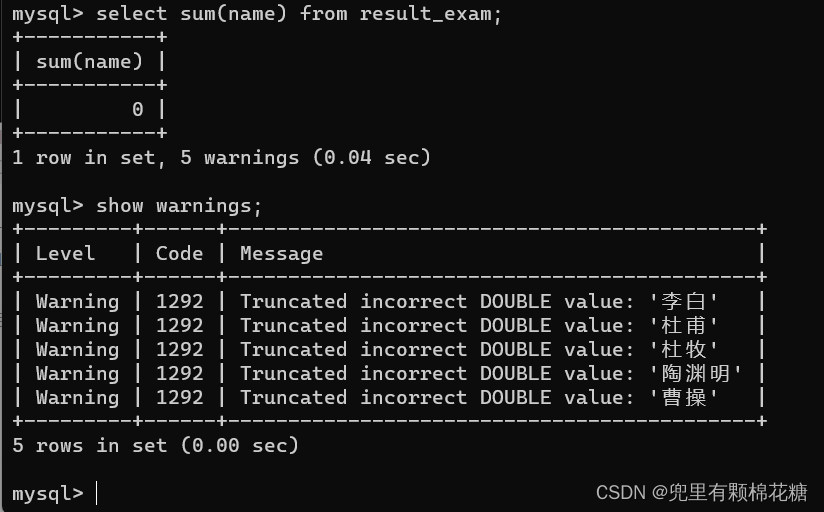
这里mysql起初想把每一行的数据转换为double类型的数据结果没有成功,但是并没有直接终止求和的操作,而是给我们提出了警告并把这个警告记录下来。
如果想查看当前的警告都有什么内容,可以输入下面的命令:
show warnings;
结果如下:
其它聚合函数
分组查询(group by)
group by子句:指定一个列,按照这个列进行分组(该列中,数值相同的行会被放在一组),每个分组中都可以按照聚合函数进行运算。
现在我们来看如下场景进行举例,请看:
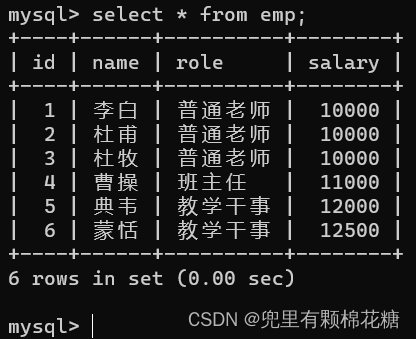
// 注意事项
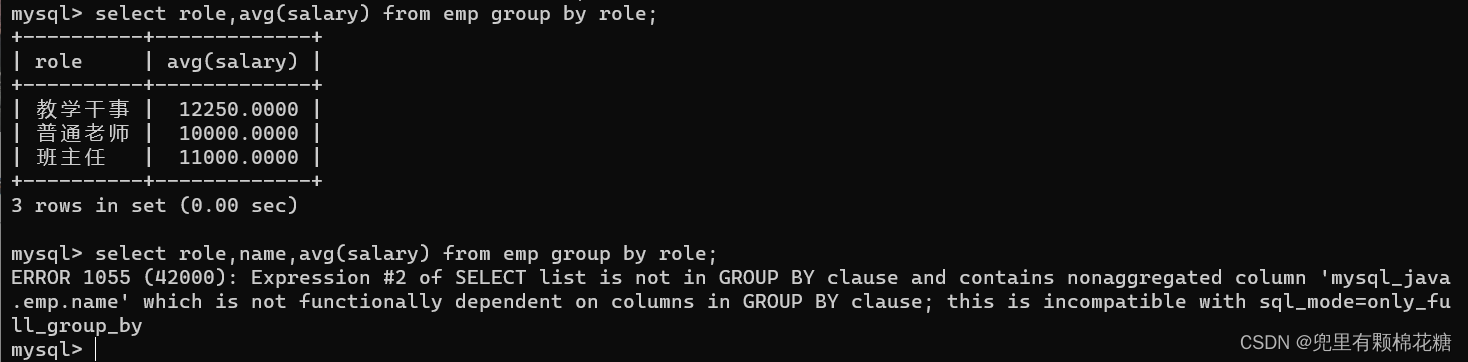
// 1.group by指定的列必须是select中指定的列
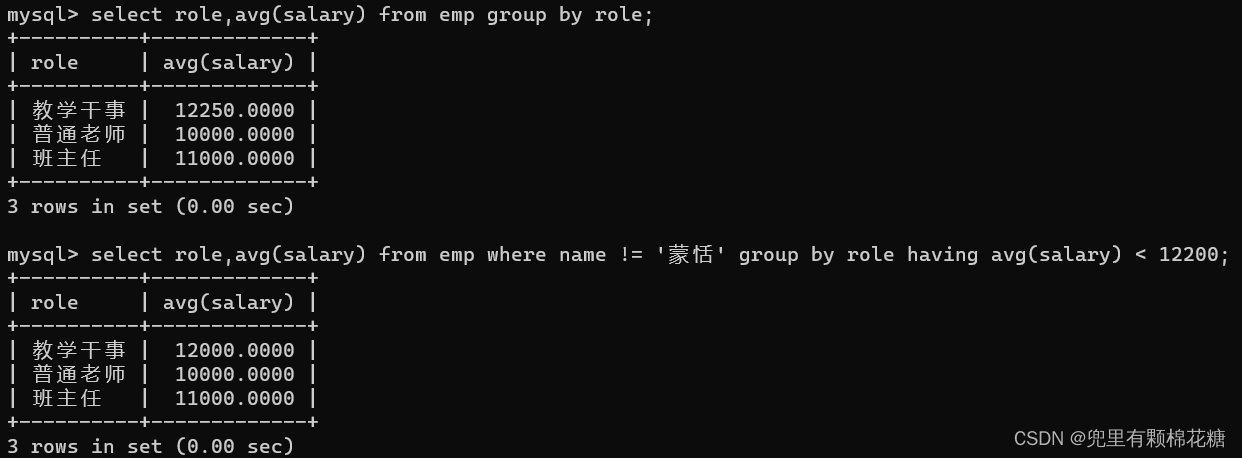
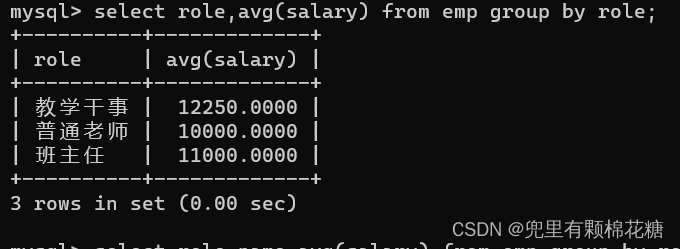
// 2.如果select中想要用到其它的列,那么其它的列必须搭配聚合函数来进行使用,否则直接查询出来的结果是没有意义的。请看举例2.select role,avg(salary) from emp group by role; // 查询每个岗位的平均薪资,请看举例1。// 分组查询当然也可以搭配条件来进行使用。比如分组之前的条件:where(请看举例3);分组之后的条件:having(请看举例4)。举例1:
举例2:
举例3:
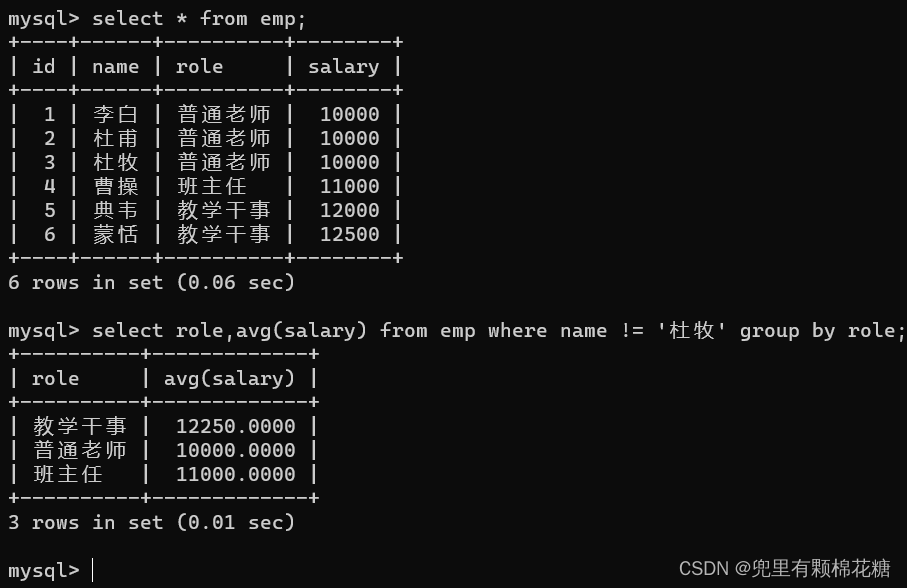
举例4: