外贸人最常用的网站北京网站优化托管
文章目录
- 前言
- 一、仿真前的配置
- 二、实现步骤
- 1.检查PC和台式机是否通讯成功
- 2.编队中对单个机器人进行独立的控制
- 3、对机器人进行编队控制
前言
实现在gazebo仿真环境中添加多个机器人后,接下来进行编队控制,对具体的实现过程进行记录。
一、仿真前的配置
本文的多机器人编队,在turtlebot3单个机器人的建图、导航等功能的基础上进行,需要在自己的远程PC和台式机中安装配置以下功能包
(1)turtlebot3单个机器人的配置:可以看之前的文章双系统ubuntu20.04(neotic版本)从0实现Gazebo仿真slam建图
(2)进行多机器人编队仿真前需要将已经写好的FourTB3s功能包配置在自己的工作空间src文件夹下,且成功编译,如果不知道怎么编译可以看这篇ROS如何将拷贝的功能包成功运行在自己的工作空间中
(3)需要在自己的src文件夹中打开终端输入:
git clone https://gitee.com/kay2022/turbot3.git
下载一个turbot3的包,如果git clone遇到问题可以参考双系统 + Ubuntu20.04 + ros2 (foxy) git clone -b连接不成功的解决记得下载完成后要重新编译。
二、实现步骤
1.检查PC和台式机是否通讯成功
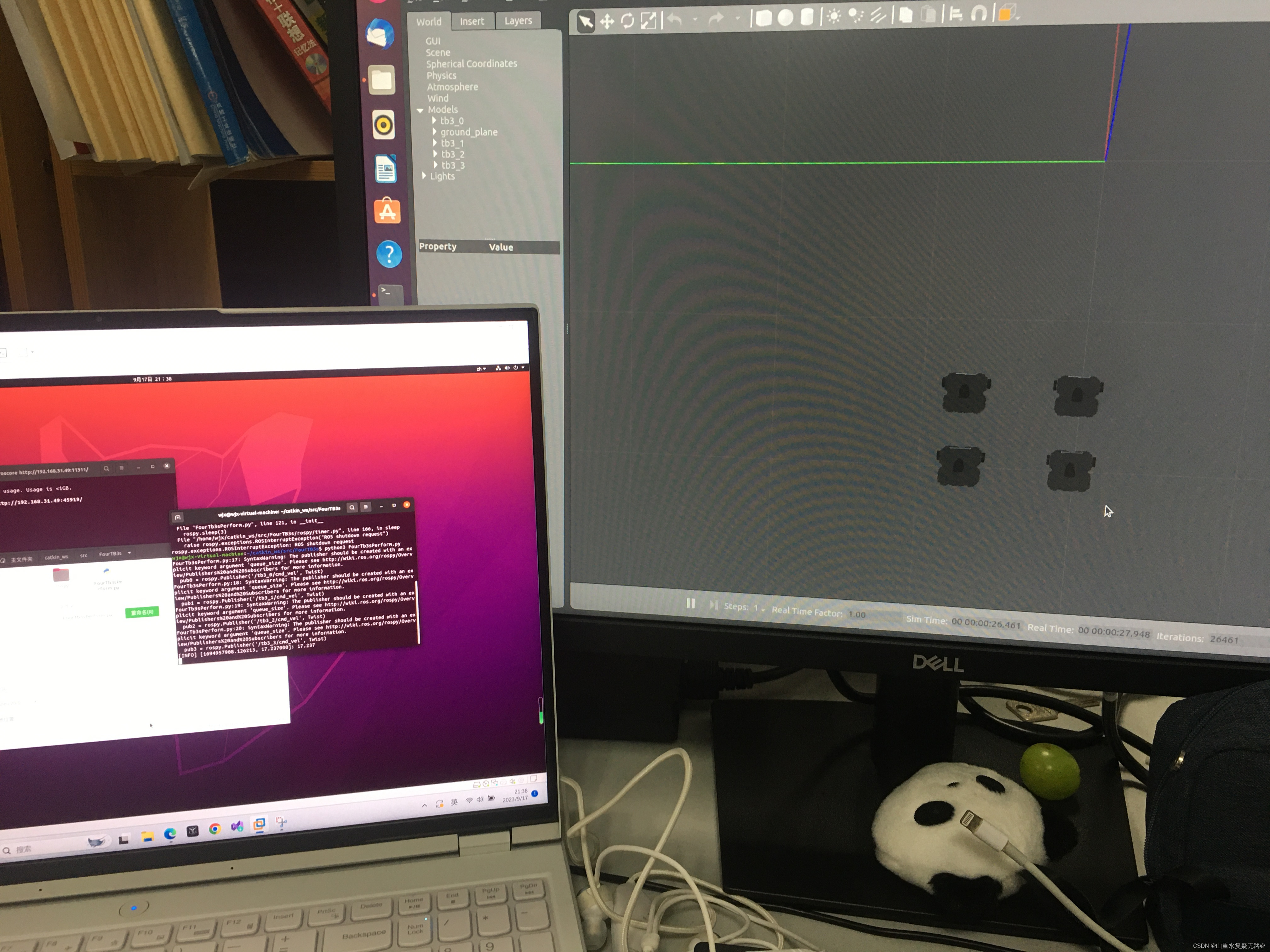
【PC端】 终端输入:roscore
【台式机】终端输入:rostopic list
通讯成功如下图(具体通信配置过程可参考:虚拟机作为master远程控制台式机中的机器人在仿真环境中进行slam地图构建与自主导航)
【PC显示】
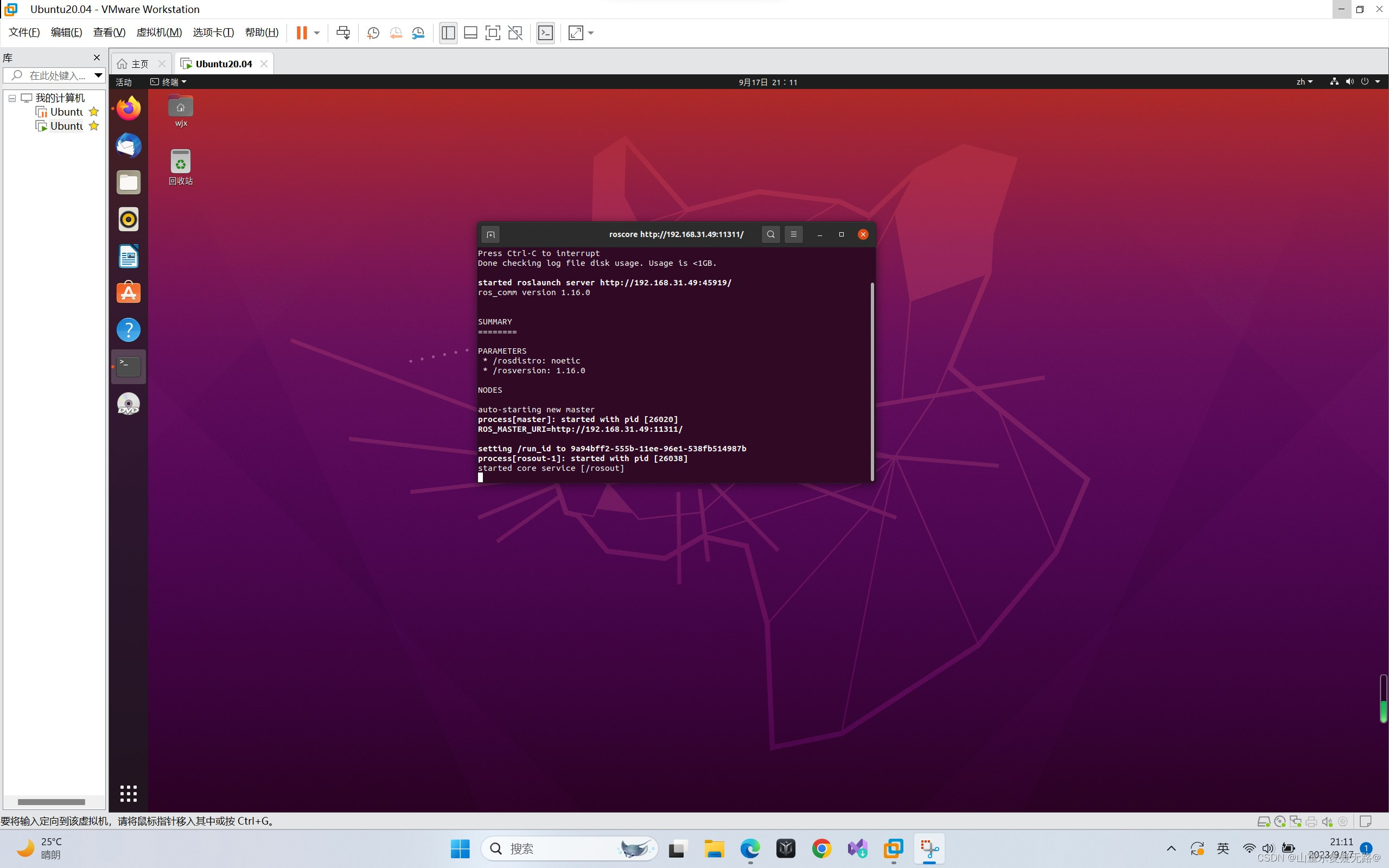
【台式机显示】

2.编队中对单个机器人进行独立的控制
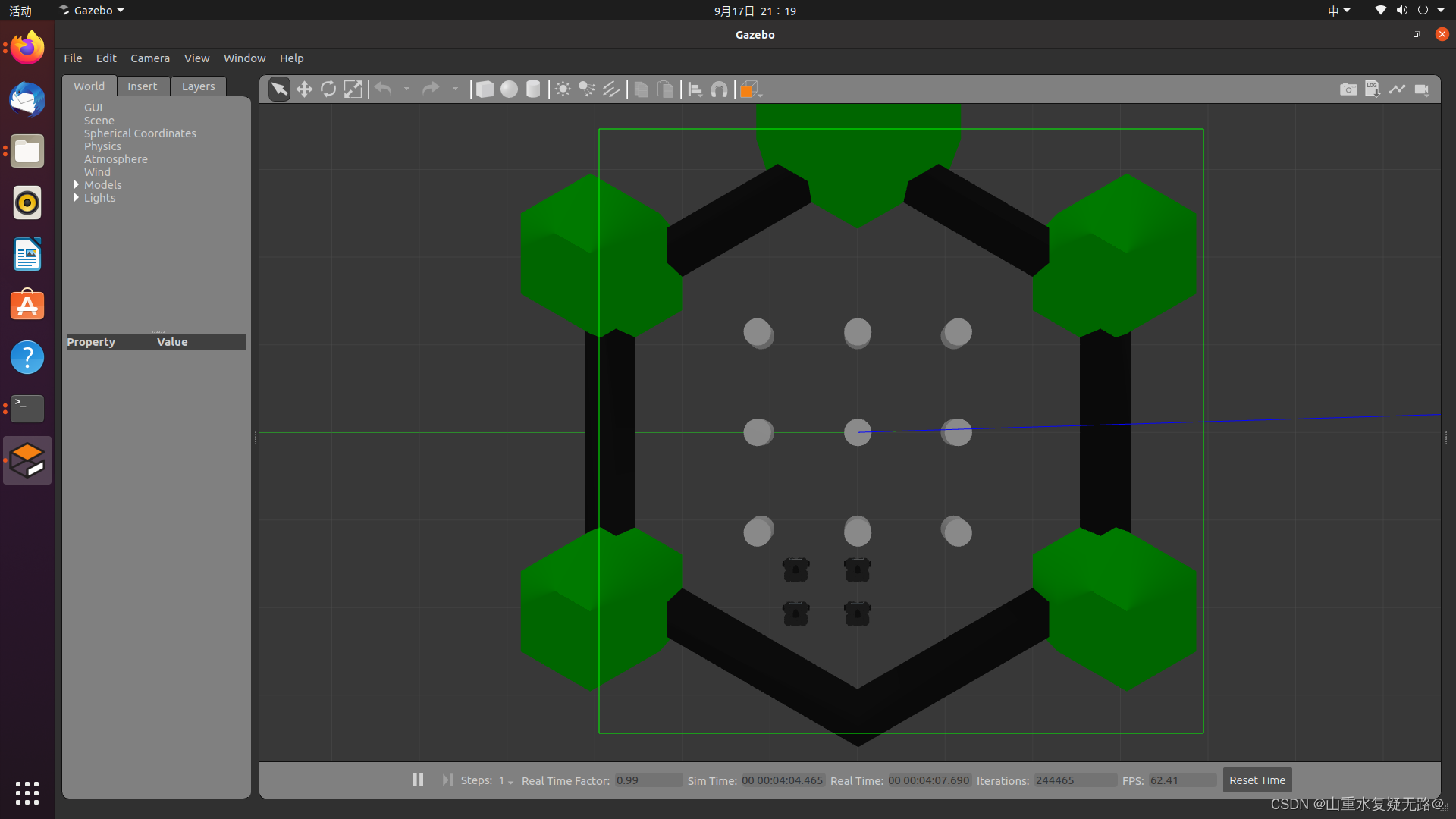
【台式机】终端输入:roslaunch turtlebot3_gazebo test.launch 启动gazebo仿真环境(四个机器人,可以增添或减少可参考文章:在gazebo仿真环境中加载多个机器人)
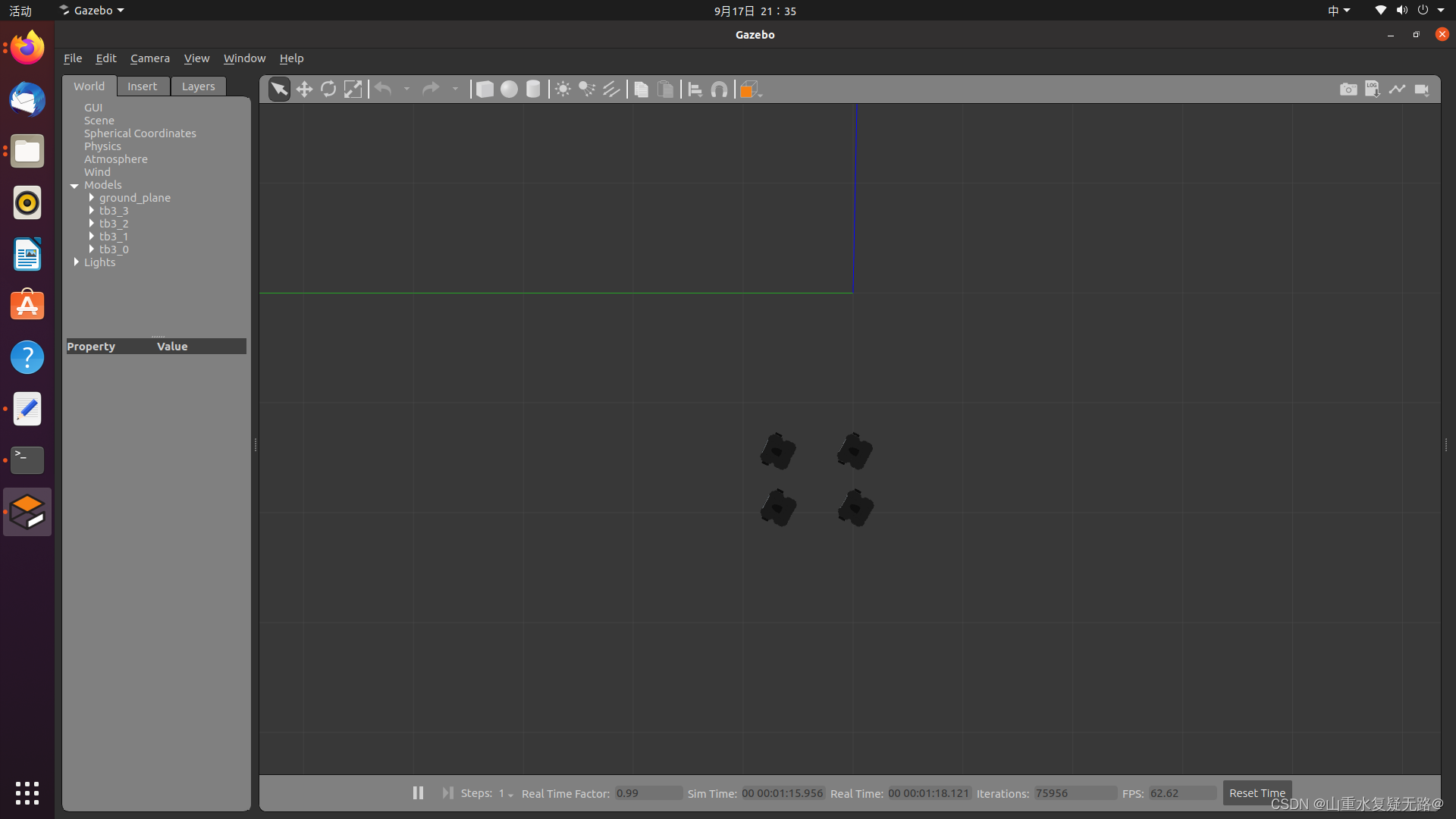
加载成功界面:
【PC】终端输入:ROS_NAMESPACE=tb3_0 roslaunch turtlebot3_teleop turtlebot3_teleop_key.launch
注意:ROS_NAMESPACE=“后面接想要控制的机器人的名字”,这个名字要与写的加载gazebo的launch中起的机器人名字一致,启动后可通过键盘控制单个机器人移动。
可以在台式机gazebo的仿真环境中,指明某个机器人控制其独立的移动,如图控制tb3_0单个机器人的移动,若控制其他机器人同理。
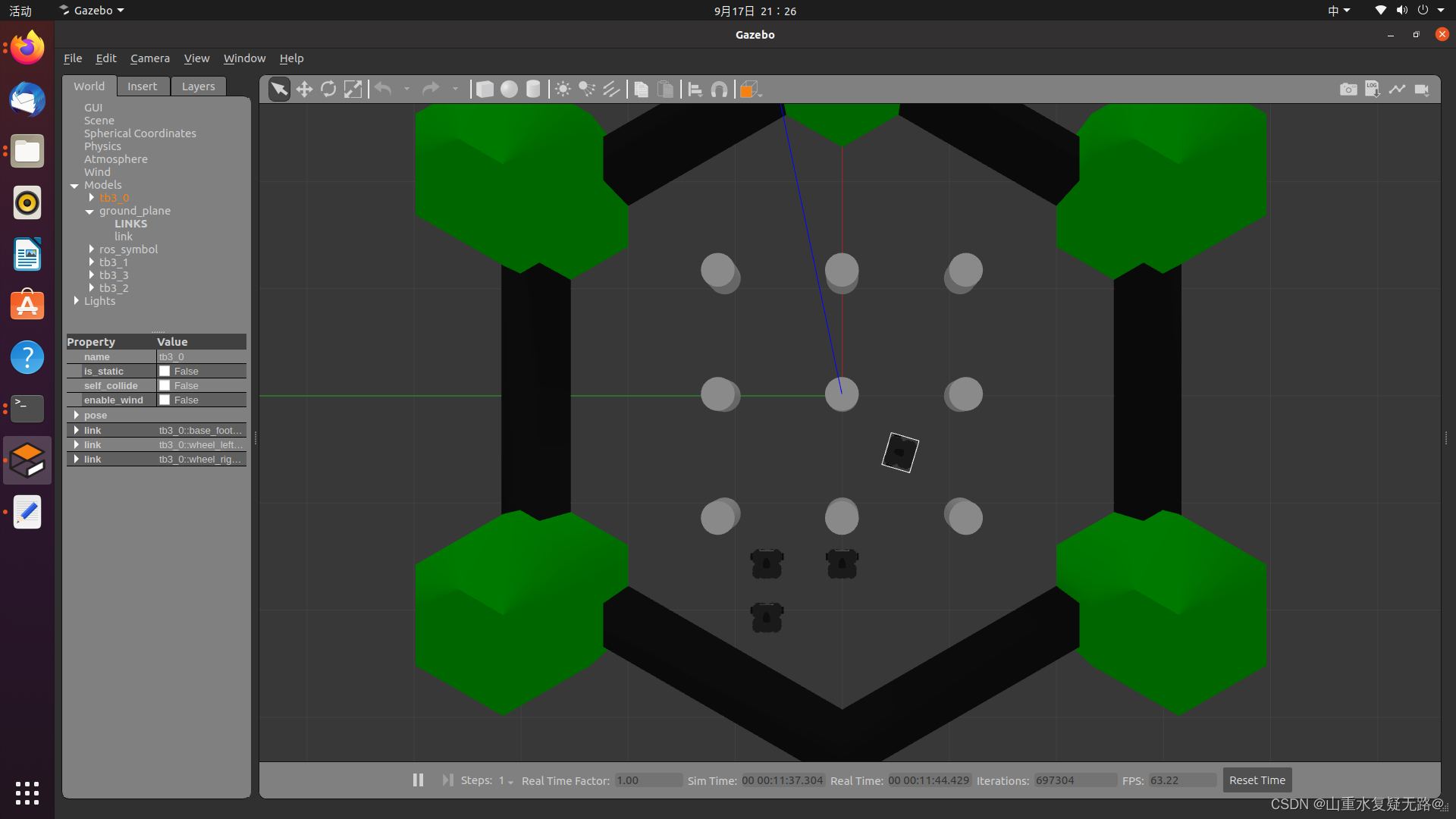
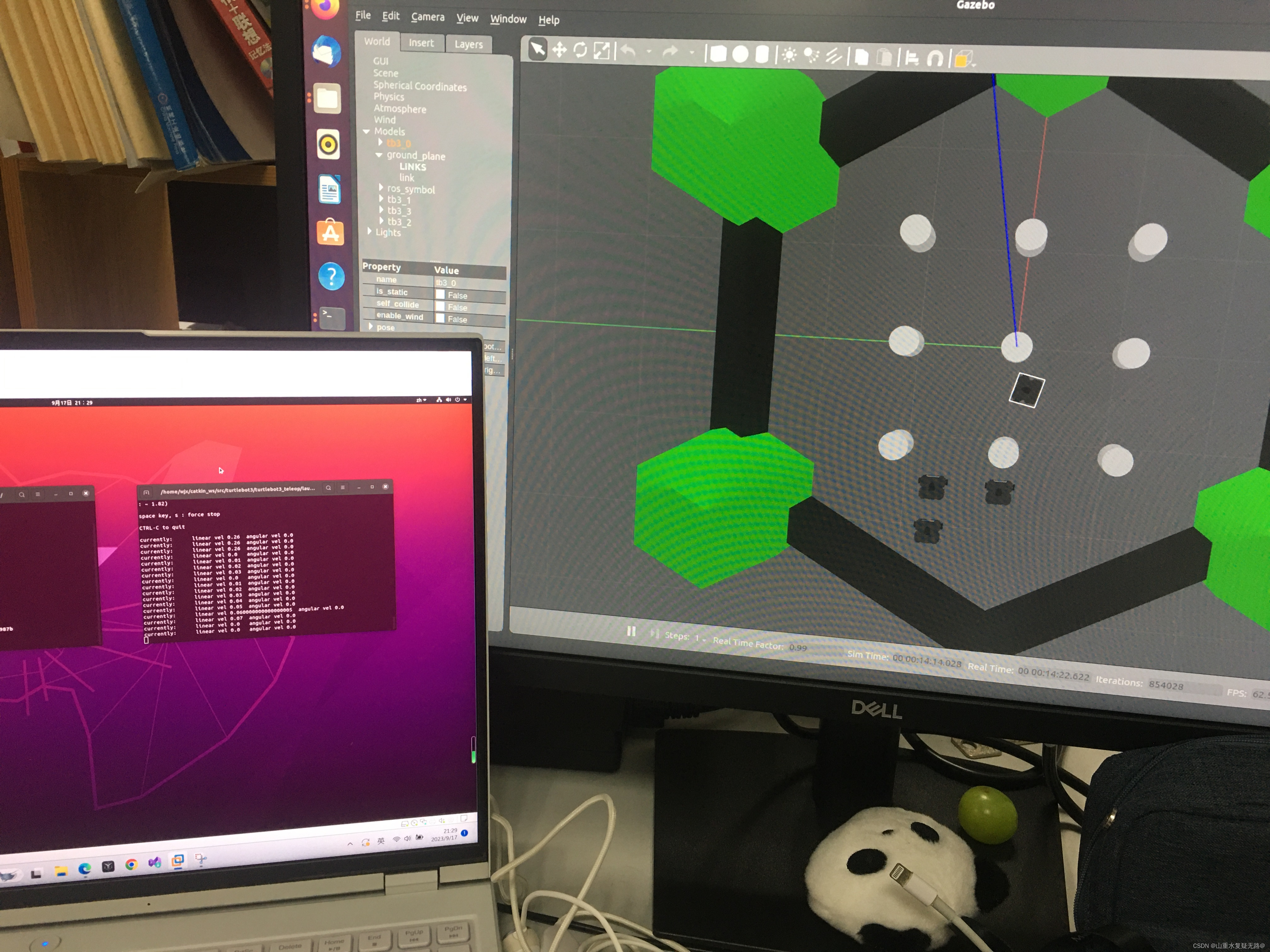
3、对机器人进行编队控制
【PC】打开FourTB3文件夹,并在该文件夹下打开终端,输入:python3 FourTB3sPerform.py为方便机器人进行编队运动,可以将gazebo环境中的障碍物去掉
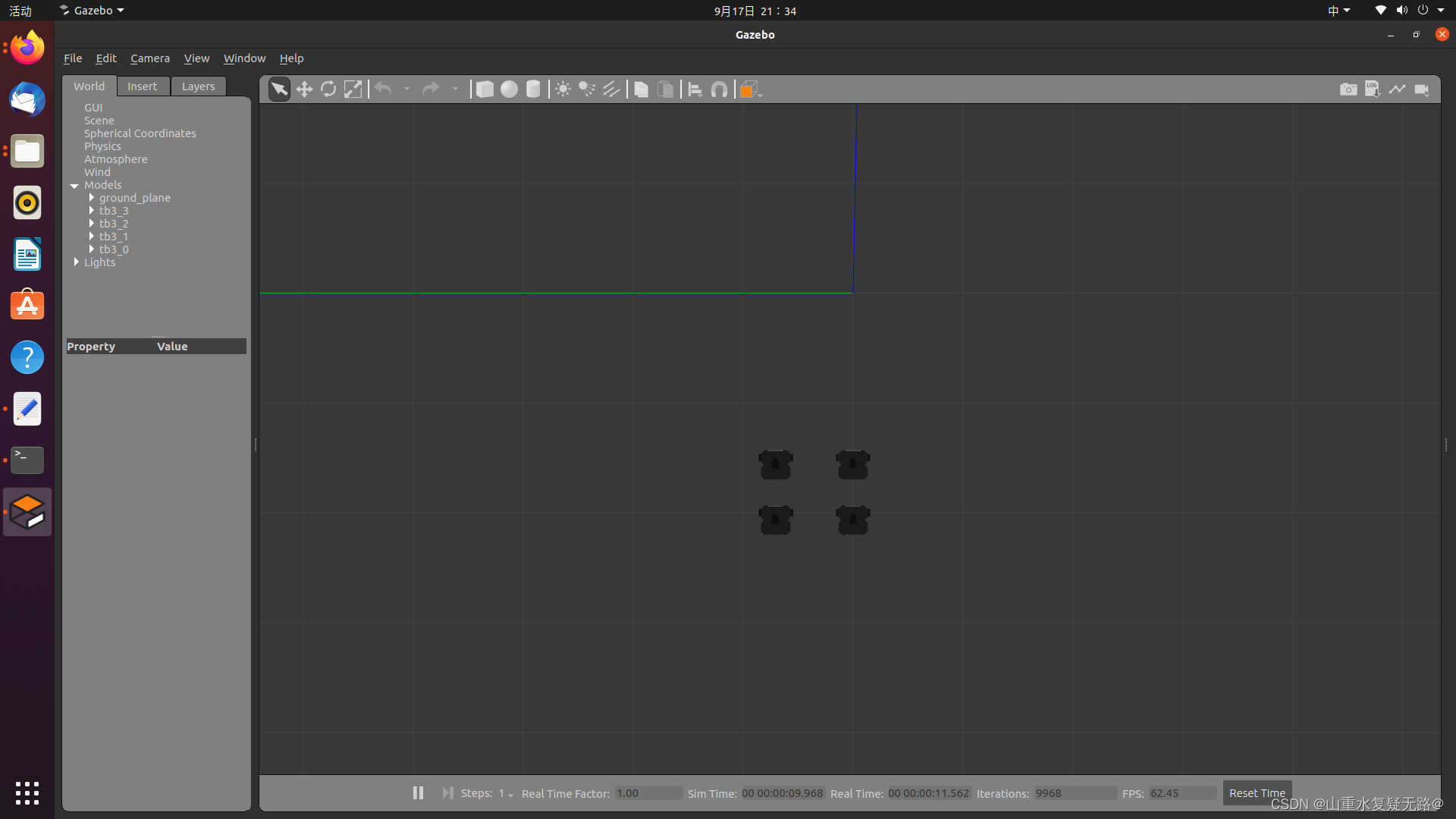 【PC端显示】
【PC端显示】
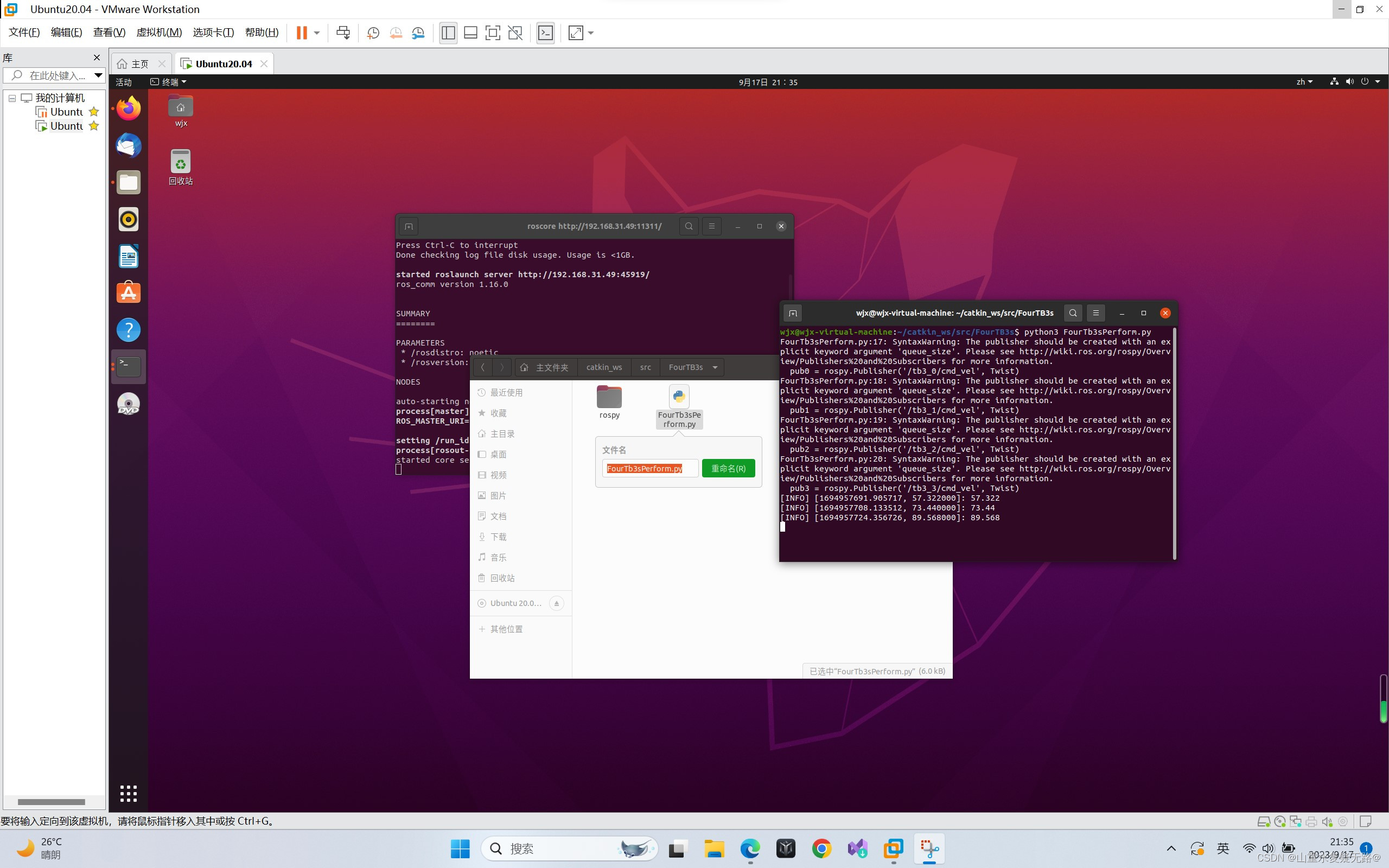
【台式机显示】
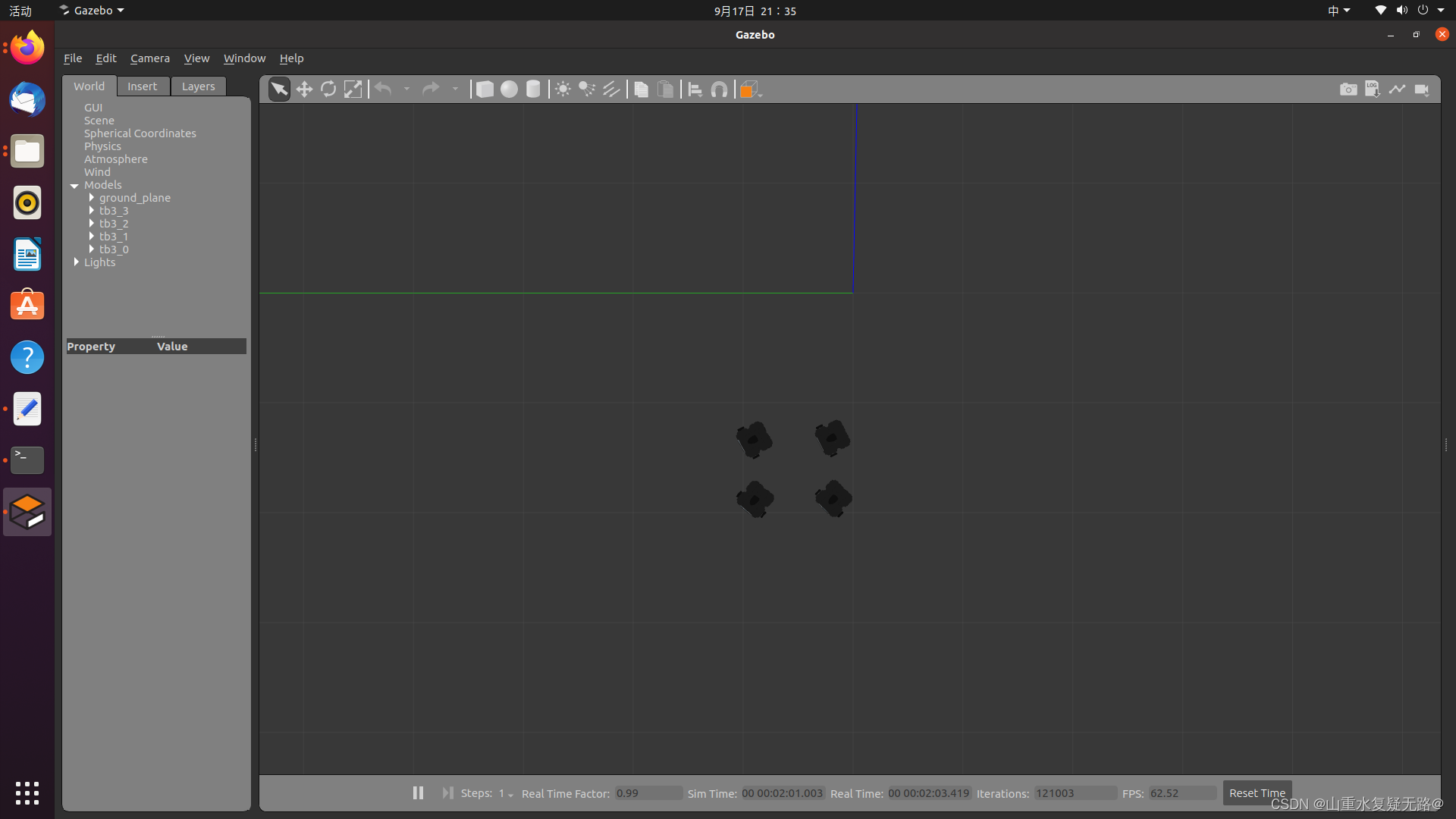
【总览】