怎么查看网站disallowwordpress wcps
0. 学习目标
- 能够说出什么是消息中间件
- 能够安装RabbitMQ
- 能够编写RabbitMQ的入门程序
- 能够说出RabbitMQ的5种模式特征
- 能够使用Spring整合RabbitMQ
1. 消息中间件概述
1.1. 什么是消息中间件
MQ全称为Message Queue,消息队列是应用程序和应用程序之间的通信方法。是在消息的传输过程中保存消息的容器,多用于多分布式系统之间进行通信
-
为什么使用MQ
在项目中,可将一些无需即时返回且耗时的操作提取出来,进行异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
-
开发中消息队列通常有如下应用场景:
1、任务异步处理
将不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理。提高了应用程序的响应时间。
提升用户体验和系统吞吐量2、应用程序解耦合
MQ相当于一个中介,生产方通过MQ与消费方交互,它将应用程序进行解耦合。
提高系统容错和可维护3、削峰填谷
提高系统稳定性如订单系统,在下单的时候就会往数据库写数据。但是数据库只能支撑每秒1000左右的并发写入,并发量再高就容易宕机。低峰期的时候并发也就100多个,但是在高峰期时候,并发量会突然激增到5000以上,这个时候数据库肯定卡死了。

消息被MQ保存起来了,然后系统就可以按照自己的消费能力来消费,比如每秒1000个数据,这样慢慢写入数据库,这样就不会卡死数据库了。

但是使用了MQ之后,限制消费消息的速度为1000,但是这样一来,高峰期产生的数据势必会被积压在MQ中,高峰就被“削”掉了。但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000QPS,直到消费完积压的消息,这就叫做“填谷”

MQ劣势
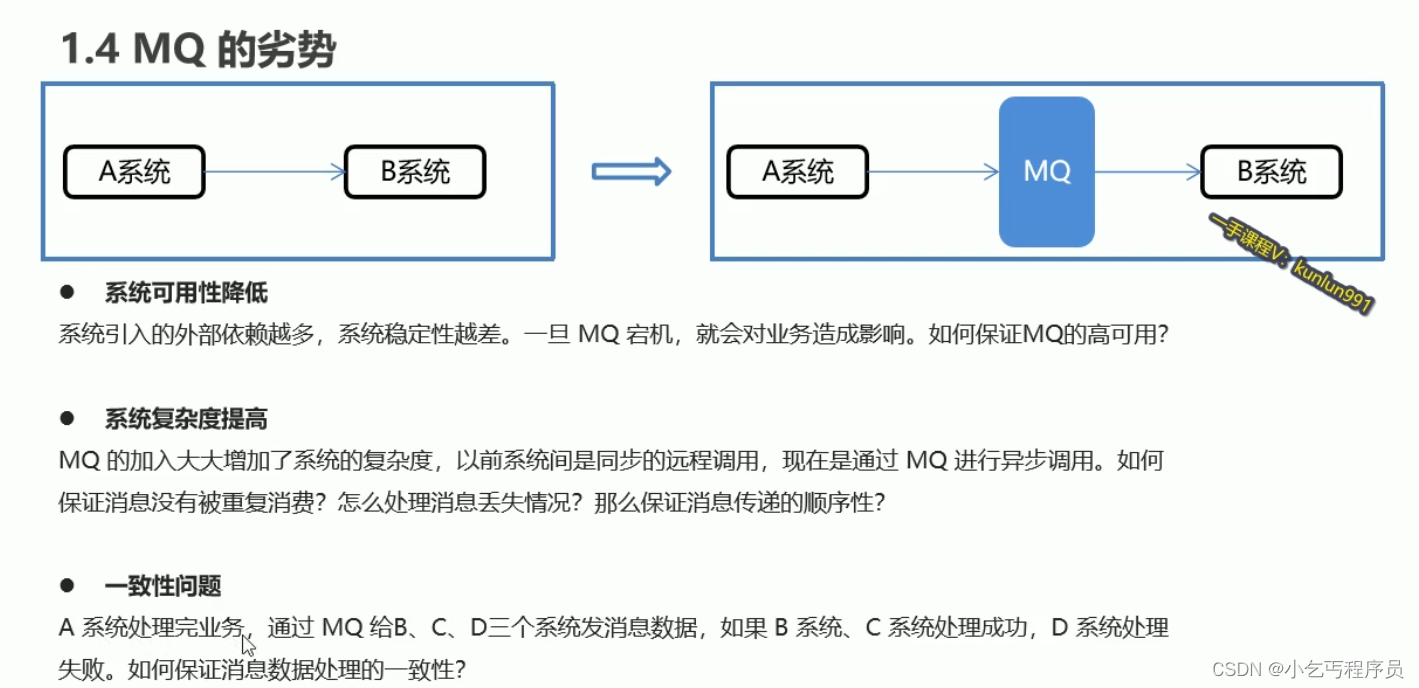

1.2. AMQP 和 JMS
MQ是消息通信的模型;实现MQ的大致有两种主流方式:AMQP、JMS。
1.2.1. AMQP
AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
1.2.2. JMS
JMS即Java消息服务(JavaMessage Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
1.2.3. AMQP 与 JMS 区别
- JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
- JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
- JMS规定了两种消息模式;而AMQP的消息模式更加丰富
1.3. 消息队列产品
市场上常见的消息队列有如下:
- ActiveMQ:基于JMS
- ZeroMQ:基于C语言开发
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品
- Kafka:类似MQ的产品;分布式消息系统,高吞吐量
RabbitMQ简介
AMQP,即 Advanced Message Queuing Protocol(高级消息队列协议),是一个网络协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。2006年,AMQP 规范发布。类比HTTP
2007年,Rabbit 技术公司基于 AMQP 标准开发的 RabbitMQ 1.0 发布。RabbitMQ 采用 Erlang 语言开发。Erlang 语言由 Ericson 设计,专门为开发高并发和分布式系统的一种语言,在电信领域使用广泛。
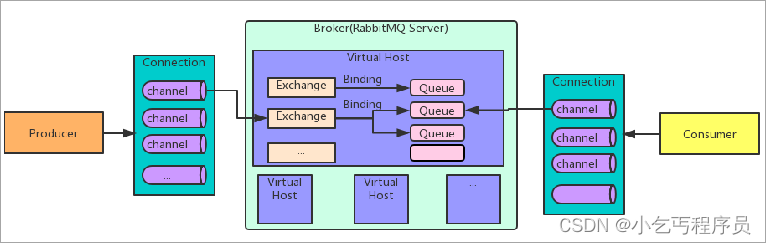
Broker:接收和分发消息的应用,RabbitMQ Server就是 Message Broker
Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当多个不同的用户使用同一个 RabbitMQ server 提供的服务时,可以划分出多个vhost,每个用户在自己的 vhost 创建 exchange/queue 等
Connection:publisher/consumer 和 broker 之间的 TCP 连接
Channel:如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的 channel 进行通讯,AMQP method 包含了channel id 帮助客户端和message broker 识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection 极大减少了操作系统建立 TCP connection 的开销
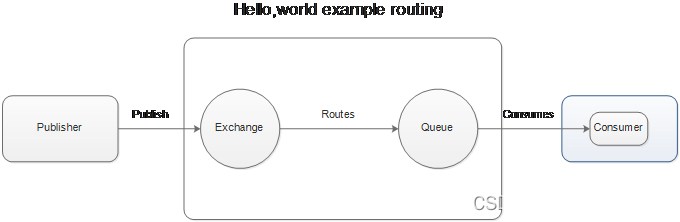
Exchange:message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有:direct (point-to-point), topic (publish-subscribe) and fanout (multicast)
Queue:消息最终被送到这里等待 consumer 取走
Binding:exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
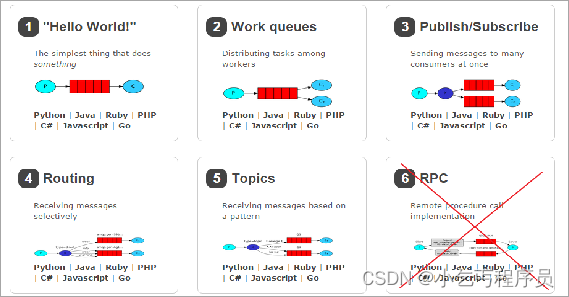
RabbitMQ 提供了 6 种工作模式:
简单模式、work queues、Publish/Subscribe 发布与订阅模式、Routing 路由模式、Topics 主题模式、RPC 远程调用模式(远程调用,不太算 MQ;暂不作介绍)。
官网对应模式介绍:https://www.rabbitmq.com/getstarted.html
JMS
JMS 即 Java 消息服务(JavaMessage Service)应用程序接口,是一个 Java 平台中关于面向消息中间件的API
JMS 是 JavaEE 规范中的一种,类比JDBC
很多消息中间件都实现了JMS规范,例如:ActiveMQ。RabbitMQ 官方没有提供 JMS 的实现包,但是开源社区有