免费做网站推荐找做废薄膜网站

图片来自谷歌 — 封面由我制作
一、说明
构建一个微服务的电影网站,需要Docker、NodeJS、MongoDB,这样的案例您见过吗?如果对此有兴趣,您就继续往下看吧。
在本系列中,我们将构建一个 NodeJS 微服务,并使用 Docker Swarm 集群进行部署。
以下是我们将要使用的工具:
- NodeJS 版本 7.2.0
- MongoDB 3.4.1
- Docker for Mac 1.12.6
在尝试本指南之前,您应该具备:
- NodeJS基础知识
- Docker的基本知识(以及已安装的Docker)
- MongoDB的基本知识(以及正在运行的数据库服务。如果你不这样做,我建议你按照我之前的文章如何使用Docker部署MongoDB副本集。
二、首先,什么是微服务?
微服务是一个独立的单元,它与许多其他单元一起构成了一个大型应用程序。通过将应用拆分为小单元,应用的每个部分都可以独立部署和扩展,可以由不同的团队使用不同的编程语言编写,并且可以单独测试。—马克斯·斯托伯
微服务体系结构意味着你的应用由许多较小的独立应用程序组成,这些应用程序能够在自己的内存空间中运行,并在可能许多单独的计算机上彼此独立缩放。 — 埃里克·艾略特
2.1 微服务的优势
- 应用程序启动速度更快,从而提高开发人员的工作效率,并加快部署速度。
- 每个服务都可以独立于其他服务进行部署 — 更容易频繁地部署新版本的服务
- 更易于扩展开发,还可以具有性能优势。
- 消除对技术堆栈的任何长期承诺。在开发新服务时,您可以选择新的技术堆栈。
- 微服务通常组织得更好,因为每个微服务都有一个非常具体的作业,并且不关心其他组件的作业。
- 解耦服务也更容易重组和重新配置,以满足不同应用的目的(例如,同时为 Web 客户端和公共 API 提供服务)。
2.2 微服务的缺点
- 开发人员必须处理创建分布式系统的额外复杂性。
- 部署复杂性。在生产中,部署和管理由许多不同服务类型组成的系统也存在操作复杂性。
- 在构建新的微服务体系结构时,您可能会发现许多在设计时没有预料到的横切问题。
三、微服务的体系结构
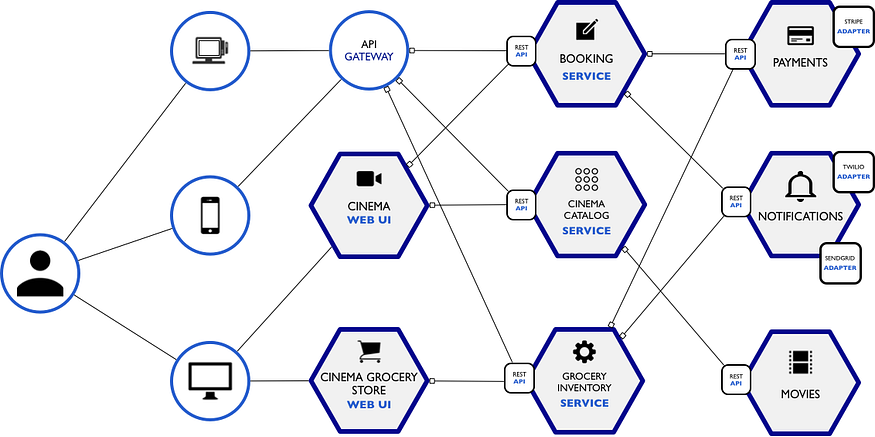
让我们想象一下,我们正在 Cinépolis(一家墨西哥电影院)的 IT 部门醒来,他们给我们的任务是将他们的票务和杂货店从单片系统重组为微服务。
因此,对于“构建 NodeJS 影院微服务”系列的第一部分,我们将只关注电影目录服务。
在这个架构中,我们看到我们有 3 种不同的设备使用微服务、POS(销售点)、手机/平板电脑和计算机,其中 POS 和手机/平板电脑有自己的应用程序开发(电子)并直接消费微服务,计算机通过 Web 应用程序访问微服务(大师认为 Web 应用程序也像微服务🤓一样)。
四、构建微服务
好的,让我们模拟一下,我们将要求在我们最喜欢的电影院预订电影首映式。
首先,我们想看看电影院目前有哪些电影。下图向我们展示了如何通过 REST 与微服务进行内部通信。
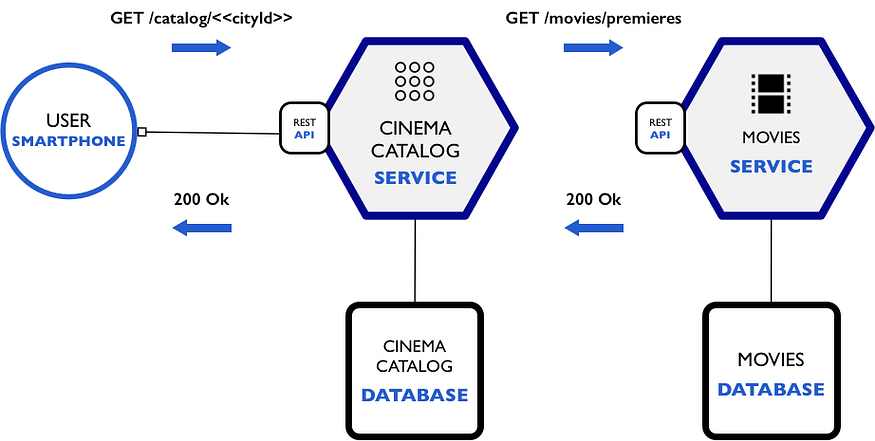
我们的电影服务 API 将具有以下 raml 规范:
如果您不知道RAML是什么,可以查看这个很棒的教程
API 项目的结构如下所示:
- api/ # our apis
- config/ # config for the app
- mock/ # not necessary just for data examples
- repository/ # abstraction over our db
- server/ # server setup code
- package.json # dependencies
- index.js # main entrypoint of the app 好的,让我们开始吧。要看的第一部分是 这里是我们对数据库进行查询的地方。repository.
您可能已经注意到,我们为存储库连接(连接)的唯一公开方法提供了一个对象,您可以在这里看到javascript具有“闭包”的最大功能之一存储库对象返回一个闭包,其中每个函数都可以访问对象和对象,对象保持数据库连接。在这里,我们正在抽象我们正在连接的数据库类型,存储库对象不知道数据库是哪种类型,在我们的例子中是MongoDB连接,即使它不必知道它是单个数据库还是副本集连接,尽管我们使用mongodb语法,但我们可以通过从固体原则中应用依赖反转原则来进一步抽象存储库功能, 从将 mongo 语法带到另一个文件,只需调用数据库操作的接口(例如使用 Mongoose 模型)。connectiondbcollectiondb
有一个用于测试此模块的文件,我将在本文后面讨论测试,但如果您想检查它,可以在 github 存储库分支 step-1 中找到它。repository/repository.spec.js
我们要看的下一个文件是 .server.js
在这里,我们要做的是,实例化一个新的快速应用程序,验证我们是否提供了存储库和服务器端口对象,然后将一些中间件应用于我们的快速应用程序,例如日志记录,安全性和功能,最后我们导出一个启动函数以便能够启动服务器😎。morganhelmeterror handling
Helmet 包括多达 11 个软件包,所有这些软件包都可以阻止恶意方破坏或使用应用程序伤害其用户。
如果你想强化微服务,你可以查看这篇很棒的文章。
好的,既然我们的服务器正在使用我们的movieAPI,让我们继续检查文件movies.js
我们在这里做的是为我们的 API 创建路由,并根据侦听的路由调用我们的 repo 函数,如果你可以看到,我们这里的 repo 使用的是接口技术方法,这里我们使用著名的“为接口而不是实现编码”,因为快速路由不知道是否有数据库对象, 数据库查询逻辑等,它只调用处理所有数据库问题的 repo 函数。
好的,我们所有的文件都有与源代码相邻的单元测试,让我们看看我们对movies.js
您可以将测试视为正在构建的应用程序的保护措施。它们不仅在本地计算机上运行,还将在 CI 服务上运行,以便失败的生成不会推送到生产系统。—
Racing by RisingStack
要编写单元测试,必须存根所有依赖项,这意味着我们为模块提供假依赖项。让我们看看我们的spec files.
如您所见,我们正在存根 的依赖项,对于服务器,我们正在验证是否需要提供服务器端口和存储库对象。movies API
可以在本文的 github 存储库中检查所有测试文件。
让我们继续如何创建我们传递给存储库模块的,现在定义说每个微服务都有自己的数据库,但对于我们的示例,我们将使用 mongoDB 副本集服务器,但每个微服务都有自己的数据库,如果你现在不如何配置 mongoDB replset 服务器, 您可以查看本文以获取更深入的解释。db connection object
如何使用Docker部署MongoDB副本集
本文将介绍如何使用 docker 设置具有身份验证的 MongoDB 副本集。
medium.com
以下是我们需要从 NodeJS 连接到 MongoDB 数据库的配置。
可能有很多更好的方法可以做到这一点,但基本上我们可以创建一个与 mongoDB 的连接,其中包含这样的副本集。
如您所见,我们正在传递一个对象,该对象具有 mongo 连接所需的所有参数,并且我们正在传递一个对象,该对象将在我们通过身份验证过程时发出该对象。optionsevent — mediatordb
注意*这里我使用的是事件发射器对象,因为出于某种原因,使用promise方法,一旦通过身份验证,它就不会返回db对象,序列将变为空闲状态。— 所以这可能是一个很好的挑战,看看发生了什么并尝试使用承诺方法。
现在,由于我们正在为参数传递一个对象,让我们看看它来自哪里,所以下一个要查看的文件是optionsconfig.js
这是我们的配置文件,大多数配置代码都是硬编码的,但正如你所看到的,一些属性使用环境变量作为一个选项。环境变量被视为最佳实践,因为这可以隐藏数据库凭据、服务器参数等。
最后,为我们的 API 编码的最后一步是将所有内容与movies-serviceindex.js.
在这里,我们编写了所有电影 API 服务,我们有一些错误处理,然后我们加载配置,启动存储库,最后启动服务器。
因此,到目前为止,我们已经完成了与 API 开发有关的所有内容,您可以在 step-1 分支中检查存储库。
如果你转到本文的 github 存储库,你会看到有一些命令用于:
npm install # setup node dependencies
npm test # unit test with mocha
npm start # starts the service
npm run node-debug # run the server in debug mode
npm run chrome-debug # debug the node with chrome
npm run lint # lint the code with standard 最后,我们启动了第一个微服务并在本地运行执行命令,但这不是文章标题所说的🤔。npm start
现在是时候把它放在 Docker 容器中了,正如我们在文章😁标题中提到的那样。
但首先我们需要的是,拥有“使用 docker 创建 mongoDB 副本集”一文中的 Docker 环境,如果您没有它,则必须执行一些额外的修改步骤来为我们的微服务设置数据库,这里有一些命令是最新的,仅用于测试我们的电影服务。
因此,首先让我们创建我们的 Dockerfile 来对我们的 NodeJS 微服务进行 docker化。
# Node v7 as the base image to support ES6
FROM node:7.2.0# Create a new user to our new container and avoid the root user
RUN useradd --user-group --create-home --shell /bin/false nupp && \apt-get cleanENV HOME=/home/nuppCOPY package.json npm-shrinkwrap.json $HOME/app/COPY src/ $HOME/app/srcRUN chown -R nupp:nupp $HOME/* /usr/local/WORKDIR $HOME/app
RUN npm cache clean && \npm install --silent --progress=false --productionRUN chown -R nupp:nupp $HOME/*
USER nuppEXPOSE 3000CMD ["npm", "start"] 我们将 NodeJS 镜像作为 docker 镜像的基础,然后我们创建一个用户以避免非 root 用户,然后将 src 复制到我们的镜像,然后我们安装依赖项,我们公开一个数字端口,最后我们实例化我们的电影服务。
接下来,我们必须使用以下命令构建我们的 docker 映像:
$ docker build -t movies-service . 让我们先看一下构建命令。
docker build告诉引擎我们要创建一个新映像。-t movies-service使用标记标记此图像。从现在开始,我们可以通过标签引用此图像。movies-service.使用当前目录查找 .Dockerfile
在一些控制台输出之后,我们在 NodeJS 应用程序中有了我们的新映像,所以现在我们需要做的是使用以下命令运行我们的映像:
$ docker run --name movie-service -p 3000:3000 -e DB_SERVERS="192.168.99.100:27017 192.168.99.101:27017 192.168.99.100:27017" -d movies-service 在上面的命令中,我们传递了一个 env 变量,它是一个需要连接到 mongoDB replset 的服务器数组,这只是为了说明,有更好的方法可以做到这一点,例如读取 env 文件。
现在我们已经启动并运行了我们的容器,让我们检索我们的微服务的 ip,并且我们准备对微服务进行集成测试,另一个测试选项可能是 JMeter,它是模拟 http 请求的好工具,这里有一个很棒的 JMeter 教程。docker-machine ip machine-name
这是我们将检查 API 调用:D。integration-test
五、这时候回顾一下子
5.1 我们做了什么...
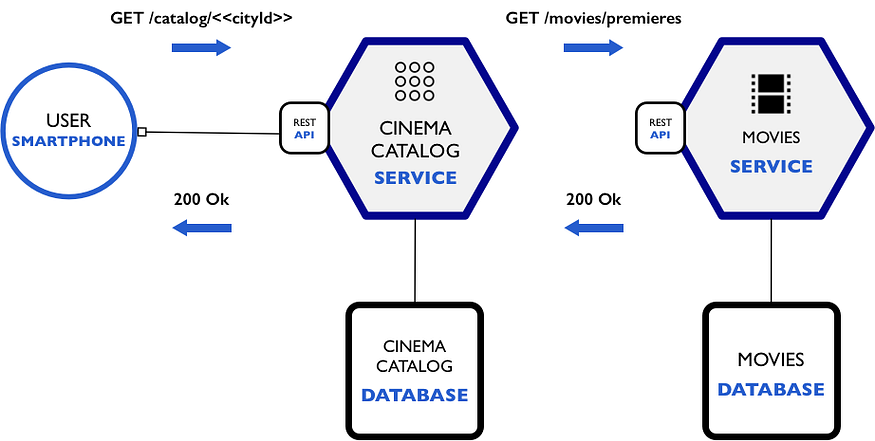
5.2 慢聊和沟通
我们只做了这个通信流程的第一部分,我们制作了电影服务来咨询电影院中可用的电影首映,我们在 NodeJS 中构建了电影服务 API,首先我们使用 RAML 规范设计 API,然后我们开始构建我们的 API,并进行相应的单元测试,最后我们编写所有内容以使我们的微服务完整, 并能够启动我们的电影服务服务器。
然后,我们将微服务放入Docker容器中,以便能够进行一些集成测试。
我们已经在 NodeJS 中看到了很多开发,但我们可以做和学习的还有很多,这只是一个先睹为快的高峰。我希望这已经展示了一些有趣和有用的东西,你可以在你的工作流程中用于Docker和NodeJS。
让我记住你,这篇文章是“构建 NodeJS 电影微服务并使用 docker 部署它”系列的一部分。
我将在本系列的第 2 部分的延续链接下方放置。
(未完,见下文)
六、参考信息
构建 NodeJS 影院微服务并使用 docker 部署它(第 2 部分)
这是✌️“构建 NodeJS 影院微服务”系列的第二篇文章。
6.1 完整的代码在Github上
您可以在以下链接中查看文章的完整代码。
Crizstian/cinema-microservice
影院微服务 - 影院微服务示例
github.com
6.2 延伸阅读
为了更好地使用NodeJS,您可以查看此站点
- 10年成为更好的节点开发人员的2017个技巧
- NodeJS 教程系列 — Node Hero(几乎涵盖了所有节点主题)
- 节点JS安全检查表
- NodeJS at Scale
6.3 # 参考资料
- MongoDB NodeJS 驱动程序
- MongoDB NodeJS Driver legacy Connection
- API 工作台 — 使用 RAML 创建 API 定义
- 模式:微服务架构
克里斯蒂安·拉米雷斯