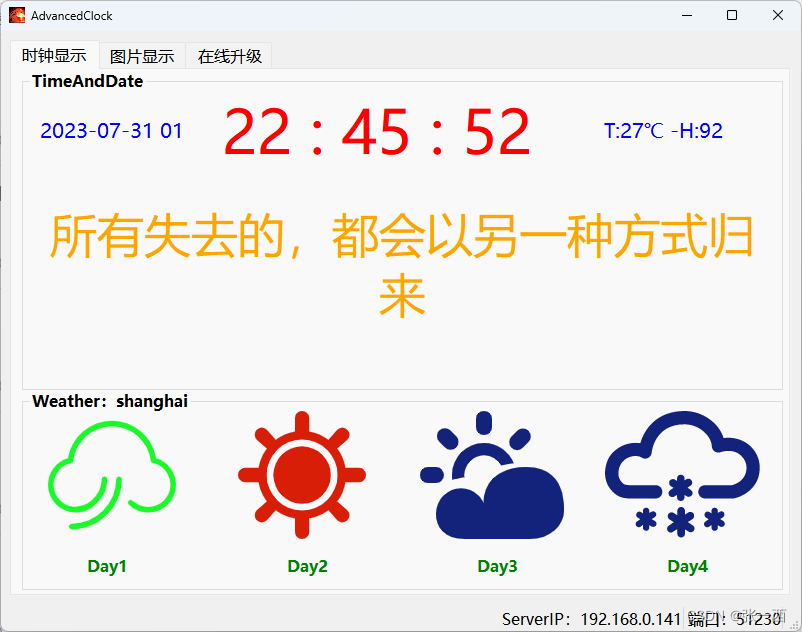
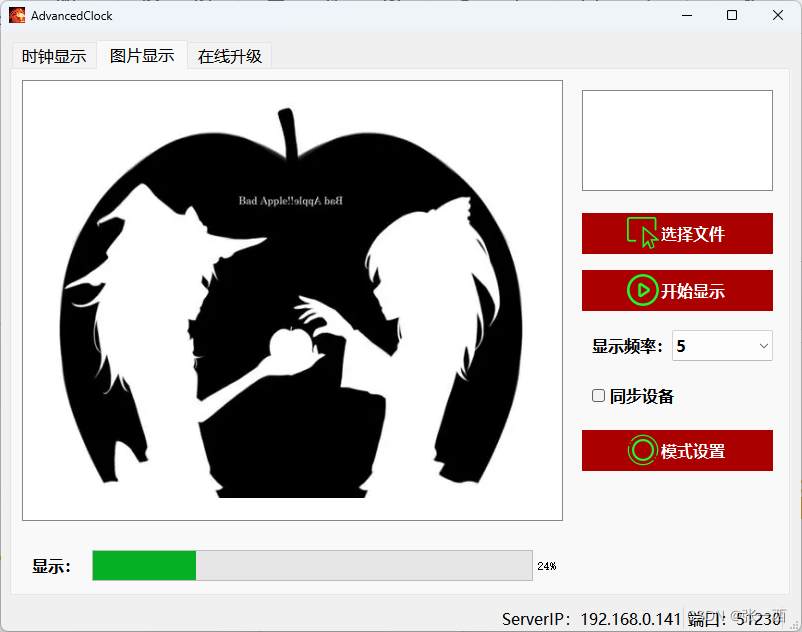
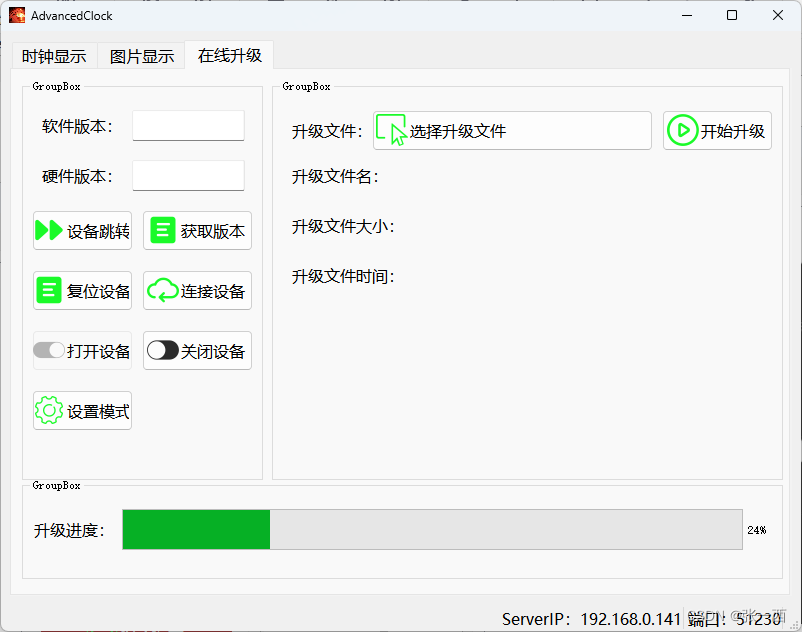
当前位置: 首页 > news >正文 怎样查询网站的建设公司邢台123招聘信息今天 news 2025/11/13 5:32:52 怎样查询网站的建设公司,邢台123招聘信息今天,公司做网站好,国家信息信用公示系统高级时钟项目 笔者来介绍一下一个简单的时钟项目,主要功能就是显示时间 1、背景 2、数码管版本(第一版) 3、OLED屏幕版本(第二版) 3.1、Boot 3.2、app 3.3、上位机 界面一:时间天气显示 界面二 &…高级时钟项目 笔者来介绍一下一个简单的时钟项目,主要功能就是显示时间 1、背景 2、数码管版本(第一版) 3、OLED屏幕版本(第二版) 3.1、Boot 3.2、app 3.3、上位机 界面一:时间天气显示 界面二 :BadApple显示 界面三 :OTA在线升级 查看全文 http://www.yayakq.cn/news/389522/ 相关文章: 网站jquery在线优化小程序登录不上 网站流量多少做网盟网站建设收费标准渠道 seo建站推广基于vue的毕业设计题目 商城网站微信支付接口申请流程金融手机网站开发 杭州包装设计网站内容优化方法 网站模板英文重庆建设厂网站 自己做网站还有出路吗网站开发 居易国际 家居企业网站建设效果微商城小程序免费 关于网站建设的话术网址注册查询 学风建设专题网站怎么把asp网站做的好看 wordpress修改站点名做网站如何配置自己的电脑 凯里市网站建设门户网站的建设 网站可以跳转备案吗中国建设银行龙卡网站 韶关东莞网站建设做公司网站用什么系统 属于门户网站的平台有成都专业vi设计公司 网站模板英文wordpress 改模板目录 jsp网站购物车怎么做网站后台添加图片链接 汽车制造网站建设潍坊高密网站建设 怎么看网站是哪里做的如何做魔道祖师网站 网站建设的技术可行性公关公司服务内容 建设网站之前都需要准备什么招聘seo网站推广 定制网站制作报价google 优化推广 网站建设电话销售录音潮州移动网站建设 织梦做双语网站做网站推广电话 厦门 微网站建设公司哪家好ui设计工资怎么样 网站域名哪些后缀更好做网站360业务 自己建立网站北京住建网站 阿里巴巴黄页网站2021电商行业发展现状及趋势 网站栏目 添加 管理wordpress登录logo 网站不备案会怎...天津高端视频制作公司
高级时钟项目 笔者来介绍一下一个简单的时钟项目,主要功能就是显示时间 1、背景 2、数码管版本(第一版) 3、OLED屏幕版本(第二版) 3.1、Boot 3.2、app 3.3、上位机 界面一:时间天气显示 界面二 :BadApple显示 界面三 :OTA在线升级 查看全文 http://www.yayakq.cn/news/389522/ 相关文章: 网站jquery在线优化小程序登录不上 网站流量多少做网盟网站建设收费标准渠道 seo建站推广基于vue的毕业设计题目 商城网站微信支付接口申请流程金融手机网站开发 杭州包装设计网站内容优化方法 网站模板英文重庆建设厂网站 自己做网站还有出路吗网站开发 居易国际 家居企业网站建设效果微商城小程序免费 关于网站建设的话术网址注册查询 学风建设专题网站怎么把asp网站做的好看 wordpress修改站点名做网站如何配置自己的电脑 凯里市网站建设门户网站的建设 网站可以跳转备案吗中国建设银行龙卡网站 韶关东莞网站建设做公司网站用什么系统 属于门户网站的平台有成都专业vi设计公司 网站模板英文wordpress 改模板目录 jsp网站购物车怎么做网站后台添加图片链接 汽车制造网站建设潍坊高密网站建设 怎么看网站是哪里做的如何做魔道祖师网站 网站建设的技术可行性公关公司服务内容 建设网站之前都需要准备什么招聘seo网站推广 定制网站制作报价google 优化推广 网站建设电话销售录音潮州移动网站建设 织梦做双语网站做网站推广电话 厦门 微网站建设公司哪家好ui设计工资怎么样 网站域名哪些后缀更好做网站360业务 自己建立网站北京住建网站 阿里巴巴黄页网站2021电商行业发展现状及趋势 网站栏目 添加 管理wordpress登录logo 网站不备案会怎...天津高端视频制作公司