公司网站上传文章wap网站制作软件
目录
前言
什么是冯诺依曼体系结构?
冯诺依曼体系结构如何进行数据处理的?
存储器在冯诺依曼体系中有什么作用?
冯诺依曼体系结构为什么要这样设计?
冯诺依曼结构总结

前言
相信对于冯诺依曼这个人的名字大家一定不会感到陌生,他被称为“现代计算机之父”
而在他生平比较重要的一大贡献就是:创建了计算机的硬件结构为冯诺依曼体系结构
接下来,我会对这个体系结构进行详细的介绍,包括他为什么要这样设计,这样设计的好处是什么,为什么现在计算机大多都以冯诺依曼体系结构为主体。。。。也会娓娓道来!那就让我们接下去看吧!
什么是冯诺依曼体系结构?
冯诺依曼体系结构是冯诺依曼提出的一种计算机硬件结构,如图
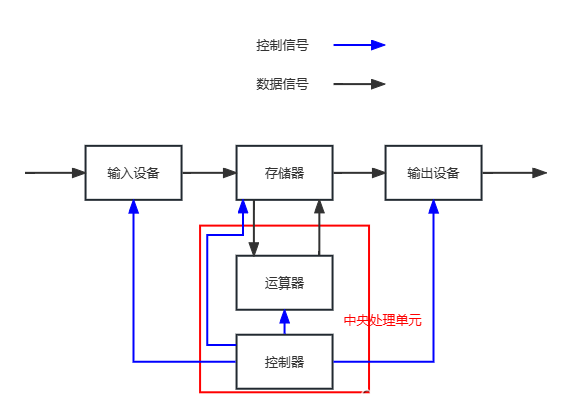
我们先看看他其中的组成是怎么样的
存储器:指的其实就是我们熟知的内存
输入设备:指的是帮助计算机产生数据的设备,例如:键盘、摄像头、话筒、磁盘、网卡。。。
输出设备:指的是帮助计算机处理数据的设备,例如:显示器、音响、磁盘、网卡。。。
注意:有些设备既可以是输入设备,也可以是输出设备
中央处理单元:指的就是电脑的CPU
运算器:是CPU中较为主要的设备之一,它的功能是进行各种运算,例如:算术运算/逻辑运算
控制器:给CPU进行响应外部事件,例如拷贝数据到内存中
现在,我们知道了什么是冯诺依曼体系结构,那么相信你也一定会有疑问,他到底是如何工作的呢?不要急,我们接下来看看!
冯诺依曼体系结构如何进行数据处理的?
第一步:首先是由输入设备读取完数据
第二步:把数据由输入设备移动到内存中
第三步:此时CPU拿到并进行处理内存中的数据
第四步:CPU再把处理好的数据交给内存
第五步:内存再把数据给输出设备,此时整个数据处理流程就完毕了
也就是如下图示意图的黑色箭头指向即为冯诺依曼体系结构的工作流程
存储器在冯诺依曼体系中有什么作用?
在看了上述内容后,相信你也有一些疑惑,为什么冯诺依曼体系结构中需要有存储器呢?
我们直接把数据从输入设备把数据给到CPU再由CPU给到输出设备不就好了吗?
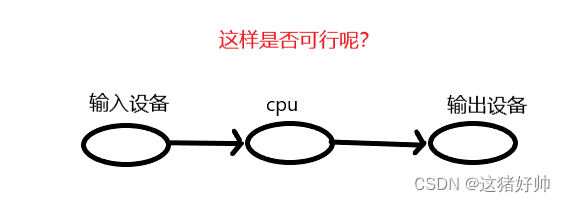
首先,我们先要了解一个概念,那就是在冯诺依曼体系结构中不同的设备,他们的处理数据的速度是远远不同的
其中,输入设备和输出设备是一个级别的速度(最慢的)
其次,存储器是一个级别的速度(中等的)
再然后,CPU是一个级别的速度(最快的)
如果我们说CPU是10纳秒级别的速度的话,那么存储器可能就是百纳秒为单位的,而输入设备和输出设备是微秒级别的
我们其实可以发现,在冯诺依曼体系结构中,CPU是不直接与输入输出设备直接进行交互的,原因也是因为他们的速度过慢会导致CPU长时间等待以至于运行效率变低
这里就好比木桶效应
木桶效应:决定一个桶能装多少水的不是取决于最高的那块木板,而是最低的那块木板
同样的,因为CPU的速度已经很快很快了,此时决定CPU的速度的就不是它自身的速度,而是其他较慢设备的速度。所以存储器这个设备在体系结构中也是必不可少的!
冯诺依曼体系结构为什么要这样设计?
在上述内容中,我们了解了,体系结构中为什么需要存储器,但我接下来又得要提出一个问题了。
为什么体系结构中需要有输入设备中的磁盘呢?同样是读取数据,它的效率还比内存要低,我不能全部换成内存吗?
从技术角度来说,这显然是可行的。因为上述,同样是读取数据,内存一定比磁盘要好
但是我们除了要考虑技术问题,最重要的一个问题是成本
我们都知道,凡是被广泛传播的产品,一定是物美价廉的!
如果我们把磁盘中的512G全部换成内存,显然这个造价就会导致计算机无法广泛传播,并且性价比极低(全部换成内存不一定就会比磁盘+内存速度快)
如果真按照这样子设计,冯诺依曼体系结构也或许并不会成为现代计算机的主流硬件结构
这也从侧面应证了,冯诺依曼体系结构之所以会成为现代计算机的主流硬件结构就是因为成本低,东西好。
冯诺依曼结构总结
在学习了上述内容后,我们也可以仔细想想
我们在学习编程语言的时候,时常听到的一句话是:程序要运行,必须先加载到内存!
我们可能学的时候是会很想当然的!我们也不考虑!但我现在就可以告诉你为什么了
因为是冯诺依曼体系结构的特点决定的,因为体系结构不让CPU与外设直接交互!
这篇文章就到这啦~我们下期再见!