企业宣传网站建设内容wordpress如何导入文章
//
编者按:随着视频直播不断向着超高清、低延时、高码率的方向发展, Apple Vision的出现又进一步拓展了对3D, 8K 120FPS的视频编码需求,视频的编码优化也变得越来越具有挑战性。LiveVideoStackCon 2023上海站邀请到腾讯云的姜骜杰老师分享腾讯云V265/TXAV1直播场景下的编码优化和应用,带领我们探索音视频技术的无限可能性。
文/姜骜杰
编辑/LiveVideoStack
大家好,我是姜骜杰,来自腾讯云,主要负责编解码开发和优化。今天分享的主题是腾讯云V265/TXAV1直播场景下的编码优化和应用。

共有三个部分:1、V265/TXAV1直播能力介绍;2、V265/TXAV1典型直播业务实践;3、腾讯云在直播场景下的编码优化技术要点。
-Part 1-
V265/TXAV1直播能力介绍
当今互联网时代,视频直播由于可以更直接的连接服务商和消费者,已经成为了一种受欢迎且广泛应用的传媒形式。人们可以通过直播平台实时观看各种内容,第一时间表达或获得最真实的见解和体验。从在线教育到体育赛事直播,从游戏直播到带货直播,直播应用正不断扩大其影响力,直播行业的发展呈现出多样化和快速增长的趋势。随着用户对高质量视频的需求不断增加,视频编码技术在直播领域的应用变得尤为重要。
当前,AV1/265编码器以其高效的压缩性能和健全的生态,已经在直播领域得到广泛应用。首先,它们能够以更高的压缩效率传输高质量的视频内容。这意味着在相同的带宽下,直播平台可以提供更清晰、更细腻的图像,让观众享受更逼真的观看体验。其次,AV1/265编码器具有较低的码率需求,可以减少网络传输的负担,提高直播的稳定性和可靠性。
为了进一步优化直播编码器的性能、提升腾讯云的直播服务能力,腾讯云架构平台部香农实验室近一年多专门针对AV1/265编码器进行了直播优化,致力于解决直播领域的挑战, 例如针对超高清视、高分辨率、高码率下视频编码的速度和质量的平衡,低延迟直播以及3D直播的压缩性能等,为腾讯云提供更高质量、更稳定、更具互动性的直播体验。
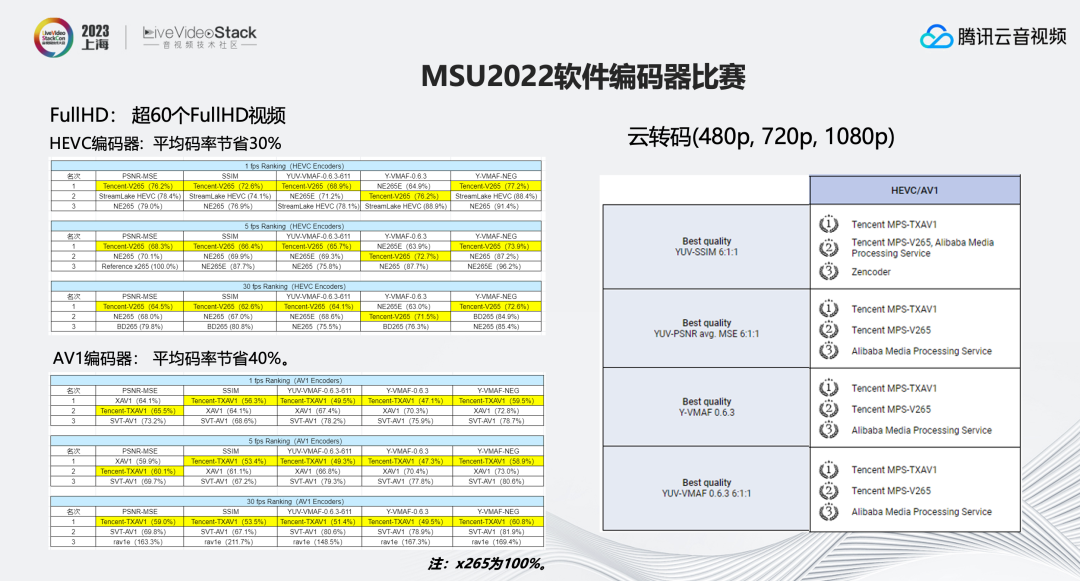
在刚刚结束的MSU2022比赛中, 我们的TXAV1/V265编码器,在相应的AV1/265赛道中,均取得了非常优秀的成绩,拿到了绝大部分指标的第一。尤其是在直播相关的30fp比赛项目中,V265平均比X265节省30%以上的码率,TXAV1平均码率能够节省40%。同时,在云转码(480p,720p,1080p)的比赛中V265/TXAV1也均包揽了比赛前两名。
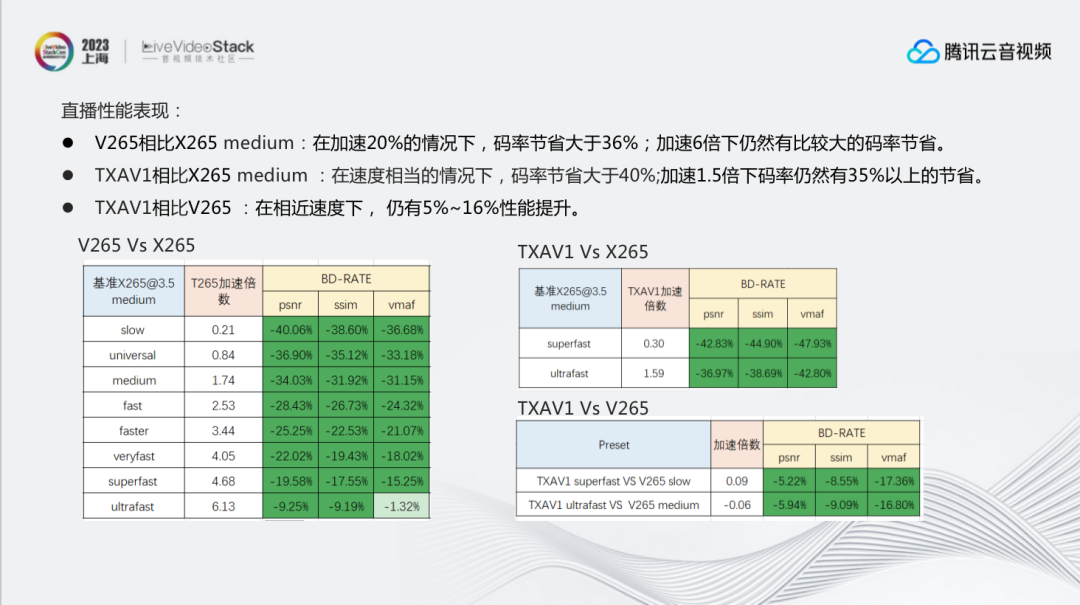
这是我们内部迭代测试,在直播场景下,V265/TXAV1的性能表现:
V265相比X265 medium:在加速20%的情况下,码率节省大于36%;加速6倍下仍然有比较大的码率节省。
TXAV1相比X265 medium:在速度相当的情况下,码率节省大于40%;加速1.5倍下码率仍然有35%以上的节省。
TXAV1相比V265:在相近速度下,仍有10%左右的压缩率提升。
-Part 2-
V265/TXAV1典型直播业务实践
2.1 8K直播

在8K直播方面,我们的业务能力总结为三点:全功能、低延时、高性能。
全功能:能够最大支持8K、60fps、10bit、150Mbps、422、HDR 、ABR直播,基本满足目前市面上所有的功能需求。
低延时:能够采用单一设备,最高支持到8K,60fps,无需分布式,将编码延时控制到最低。
高性能:即使在8K 60pfs下, 压缩性能仍然明显高于X265 medium档,并有近9倍的加速。
2.2 快直播
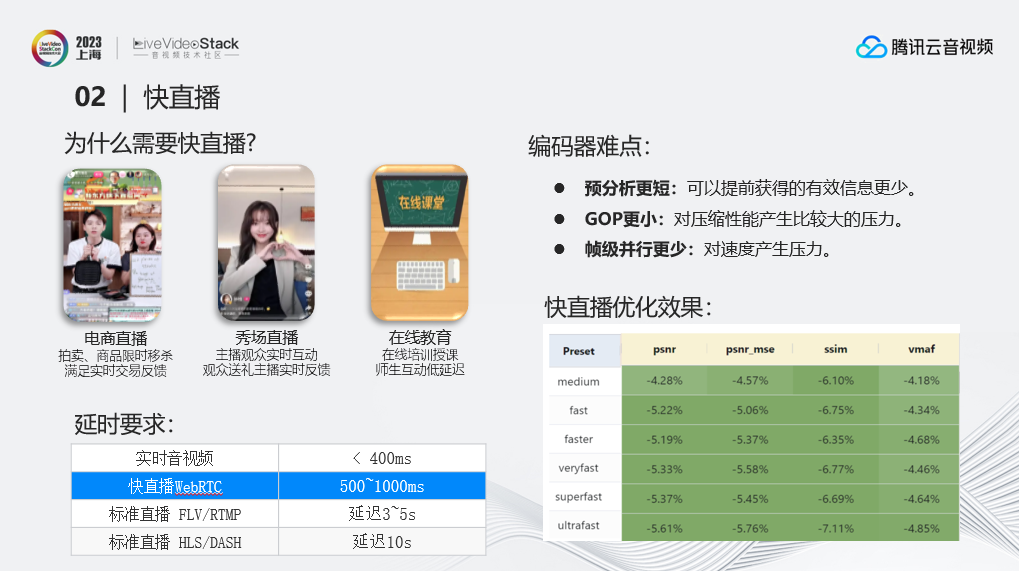
为什么需要快直播?
快直播主要应用在电商直播、秀场直播及在线教育等场景,需要与观众进行实时互动和交流。实时互动对延时的要求非常高,快直播延时要求在500-1000ms以内,比标准直播的延时要求严格很多。
但是低延时会对编码器的性能造成很大挑战,主要体现在预分析更短(可以提前获得的有效信息更少)、GOP更小(对压缩性能产生比较大的压力)、帧级并行更少(会影响多线程下的编码速度)。因此优化的重点是在保证速度的前提下提升性能。经过针对性的优化,目前快直播场景相较于优化前有5%-7%的码率节省。
2.3 MV-HEVC
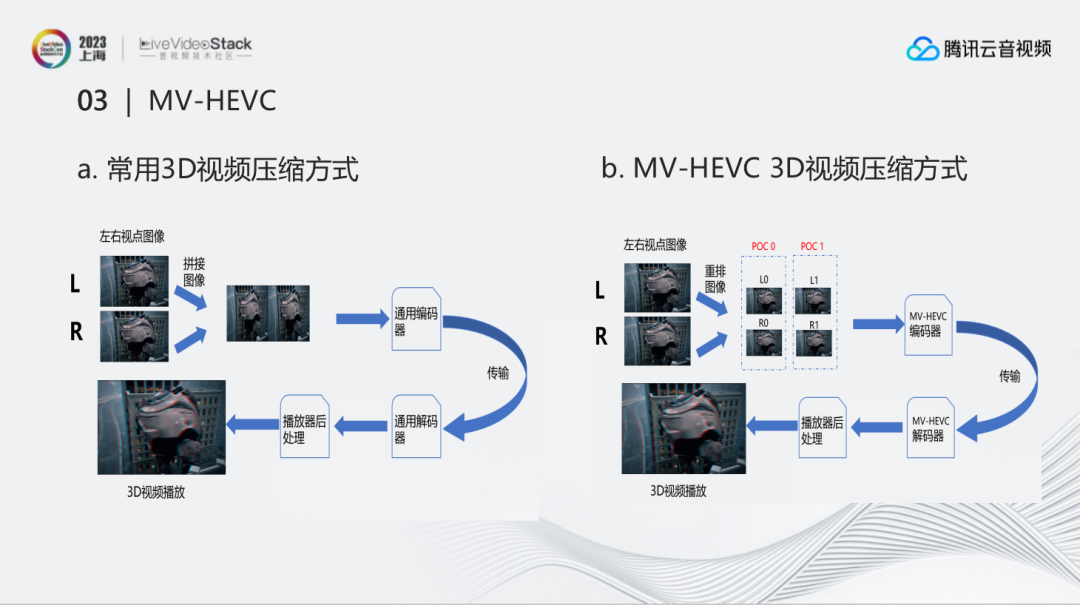
苹果全球开发者大会(WWDC)上正式发布Apple Vision Pro 时,提到它通过支持MV-HEVC 编码标准的硬件编解码显著提升了 3D 视频主客观体验。而在这之前,腾讯就已经完成了对MV-HEVC 编码的支持以帮助压缩3D视频,获得更好的3D视频主观质量。左边是常见的3D视频压缩方式:把左右视点图像进行拼接后用通用编码器进行压缩,解码后再重新拆分成左右2个视频。这也是为什么下载的3D视频如果不是用3D方式打开的时候,出现的图像是左右分开的。
右边是MV-HEVC 3D视频压缩方式,并没有把两个视点拼接,而是将多个视点组成一组相同时间下的图像组进行编码。这样的好处是视频的左右眼不再是相互独立的,而是具有参考关系,这样便 能很好的提升压缩效率。

MV-HEVC的原理:利用了左右视点图像间的冗余信息,进一步提高图像的压缩效率。例如,如果按照常用左右拼接的方式,第一帧的左右视点都是I帧,压缩性能比较差。但是如果按照多视点编码方式编码,那么左视点是I帧,而右视点是P帧, 因此右眼可以充分参考左眼的信息,压缩效果就能明显提升。当左右眼视差较小的时候,压缩效果提升会更加明显。
我们目前的测试结果包括8个JCT3V测试序列和5个3D电影,最后平均压缩收益能超20%。如结果所示,3D电影的收益更大些,因为3D电影中有很多的远景视频,故左右眼视差较小,而MV-HEVC对于图像运动越剧烈或左右眼视差越小,得到的压缩收益也会越大。
-Part 3-
腾讯云在直播场景下的编码优化技术要点

3.1.1 工程优化:数据结构
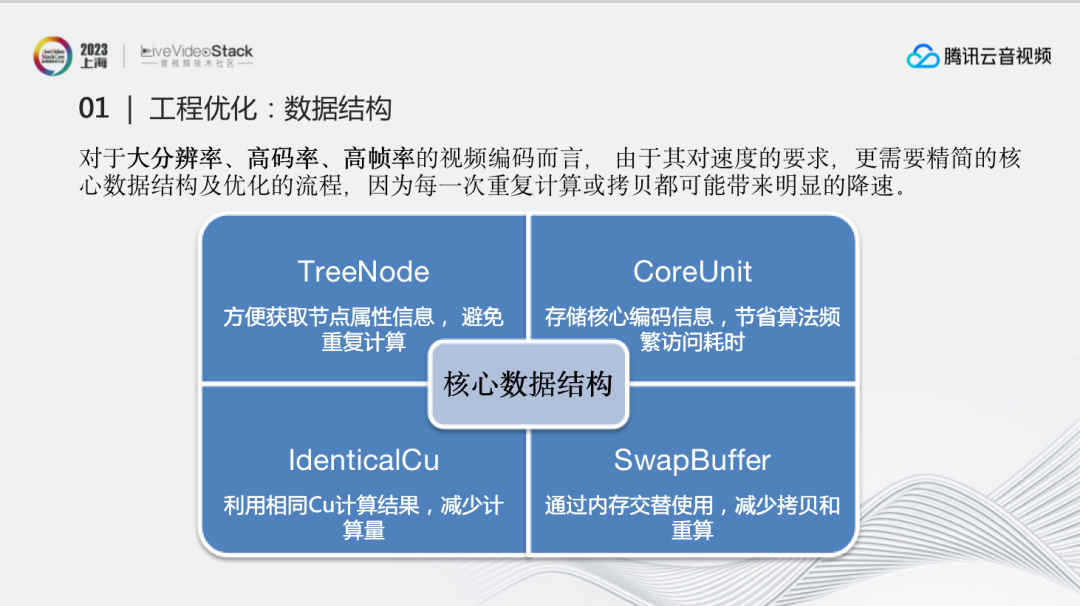
对于大分辨率、高码率、高帧率的视频编码而言,由于其对速度的要求更高,因此更需要精简的核心数据结构及优化的流程,因为每一次重复计算或拷贝都可能带来明显的降速。基于这种要求,对于从零开始做的V265以及TXAV1编码器,我们从设计伊始就明确了目标:将核心数据结构尽量设计高效、精简:
1、TreeNode:方便获取节点属性信息,避免重复计算。比如图像节点能否再划分,有哪些可用模式,宽高位置等基本属性都可以通过提前计算得到。
2、CoreUnit:核心储存结构,能够存储核心编码信息,既能节省算法频繁访问耗时,还能帮助高效获得周边块的信息。
3、IdenticalCu:利用相同Cu计算结果,减少计算量。鉴于有些块的划分方式在不同节点下其实是一样的,IdenticalCu能够避免继续划分,提前存储信息,实现重复使用。
4、SwapBuffer:通过内存交替使用,减少拷贝和重算。对比SwapBuffer使用前后的性能发现,使用后通测能够提升5%的速度,而在8K方面能有20%以上的提速。也就是说,对于8K,重复计算、拷贝和大内存的访问都可能会带来更大程度的降速。
3.1.2 工程优化:流程优化
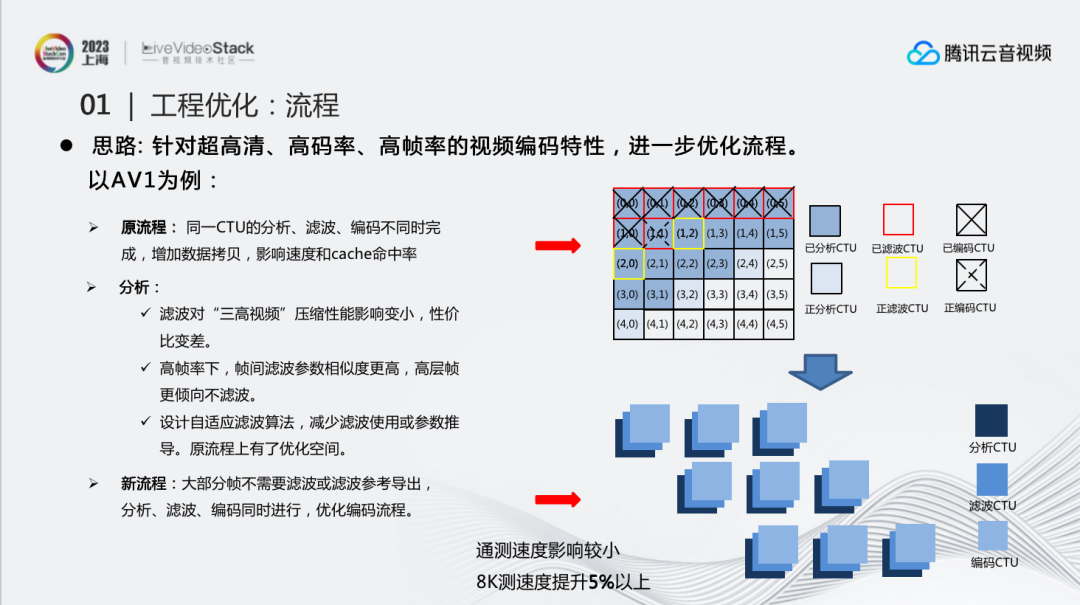
针对超高清、高码率、高帧率的视频编码特性,进一步优化流程。以AV1为例,原流程中,同一CTU的分析、滤波、编码不同时完成,这是由于滤波依赖帧级的参数,而我们无法在当前块操作结束之后就得到帧级参数,进行滤波,只能通过一些算法尽早获得整帧滤波参数,提高并行度。但这样的做法会增加数据拷贝,影响速度和cache命中率。
经过分析后发现,滤波对超高清、高码率、高帧率的视频压缩性能影响变小,但对整体速度影响较大,性价比变差,因此可以适当地减少一些滤波操作。此外,在高帧率下,帧间滤波参数相似度更高,高层帧更倾向不滤波。所以,是否有可能跳过或者复用其它帧滤波参数?因此我们设计了一套自适应滤波算法,减少滤波使用或参数推导。
这样整个流程就有了很大的优化空间:对于不需要做参数推导的帧,当前CTU做完了分析之后就可以立即进行滤波、编码,免去了拷贝和加载的操作,明显提升了编码速度。其实V265一直采用这个编码流程,但由于AV1滤波参数导出的原因在最开始的设计中没有办法实施。
最终修改之后在8K序列上的测试能够提升5%以上,在通测序列下由于滤波跳过得比较少,因此速度影响相对比较小。
3.1.3 工程优化:多线程
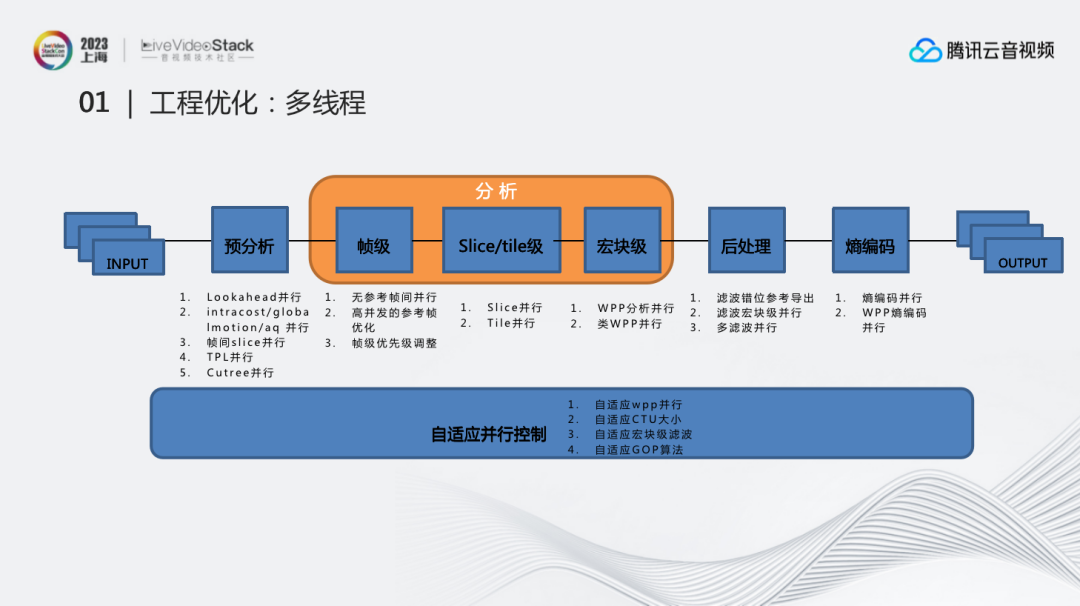
这是多线程总流程图。我们将多线程分了很多部分,包括预分析、帧级、SLICE/TILE级、宏块级、后处理等,针对每一部分都设计了可以提升并行度的算法。
比如帧级中无参考帧间并行、高并发的参考帧优化、帧级优先级调整;宏块级中WPP分析并行、类WPP并行;后处理中滤波错位参考导出、滤波宏块级并行、多滤波并行等。
同时我们也有一套自适应并行控制。很多时候并行并不是无损的,因此需要考虑怎么在提升速度的前提下,减少损失。比如当知道线程数、设备核数、图像宽高、图像复杂度的情况下,就可以去自适应调节WPP并行、CTU大小、GOP长度等等。

虽然我们已经有了很完整的一套并行方案,但是在8K场景下又会出现很多新的问题:
第一个问题,首帧延时高,CPU使用率低。正常帧内并行都是以WPP为主,但它会依赖它的左块和右上块,导致它们之间必须有错位关系才能并行。也就是说,在左图上最多并行的也只有4个块。为了更好的计算并行度,我们总结出一个公式:w,h代表宽高CTU的个数,但这只是最大并行度,因为WPP并度有个逐渐上升和逐渐下降的过程,所以这只是理想中最好的并行效果。
因此,为了减少首帧延时,就需要增加最大并行度,而TILE并行时,多个TILE间无依赖关系,因此TILE并行就是一个可行的方案。以4K为例,WPP最大并行度是16.2。因此只要TILE个数大于16个,理论上就会有速度收益。实际的计算结果验证了这一点,TILE划分4×4已经能够提速2.2%,4×8能够提速25.59%,运行效果比WPP更好。
但如何减少或者避免过程中的性能损失呢?如果目标是降低首帧延时的话,那么没有必要对所有图像进行多TILE编码,可以使用自适应的方法。这里自适应有2个方向,首先可以自适应计算加多少TILE合适;其次可以自适应只针对关键帧多TILE编码,其他帧仍旧使用原先的编码方式。这样的组合能够做到控制性能损失的前提下,有效地降低延迟。
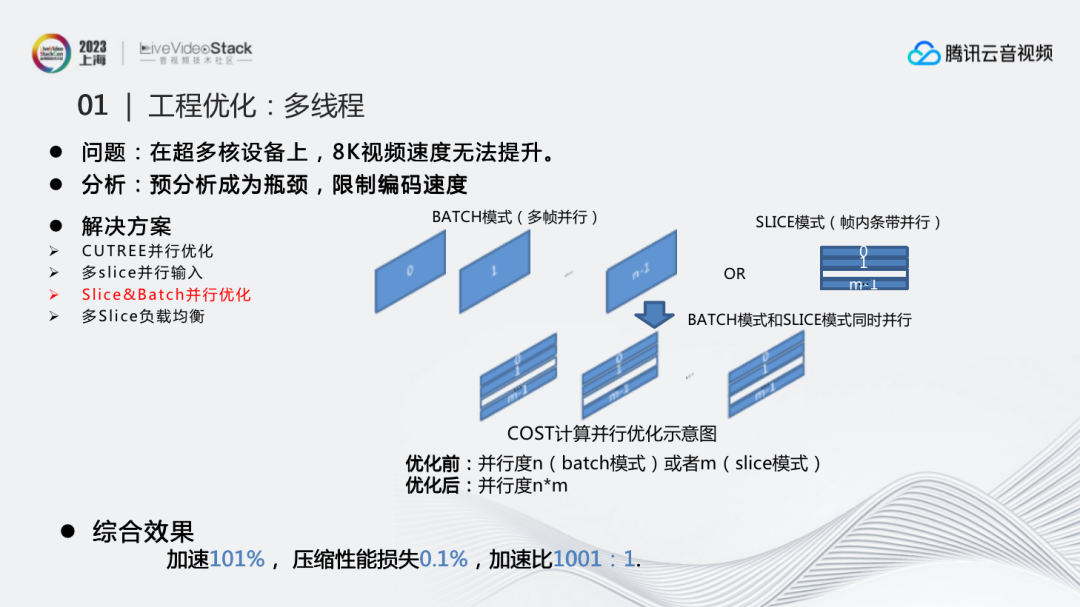
第二个问题,在超多核设备上,8K视频速度无法提升。通过整体分析对比发现,预分析成为整个编码过程的瓶颈,限制了编码速度。这里有多种优化手段,从输入到预分析编码都进行了优化。比如CUTREE并行优化、多SLICE并行输入、SLICE&BATCH并行优化、多SLICE负载均衡,避免其由于负载不均衡导致延时过大的问题。多SLICE负载均衡是根据图像划分条带,避免有些条带比较大。但由于编码过程中涉及复杂的内容问题,我们会记录实际运用中每个条带的时间,通过不断调整最终达到比较优的效果。
右图是SLICE&BATCH并行。BATCH模式其实就是多帧并行,SLICE模式是帧内条带并行。我们发现在8K场景二者单独的效果都不够,二者结合才能达到比较好的效果,并行度提升得非常明显。
在一系列加速措施之后,综合效果能达到加速101%,压缩性能损失0.1%,加速比1001:1。
3.2 算法优化
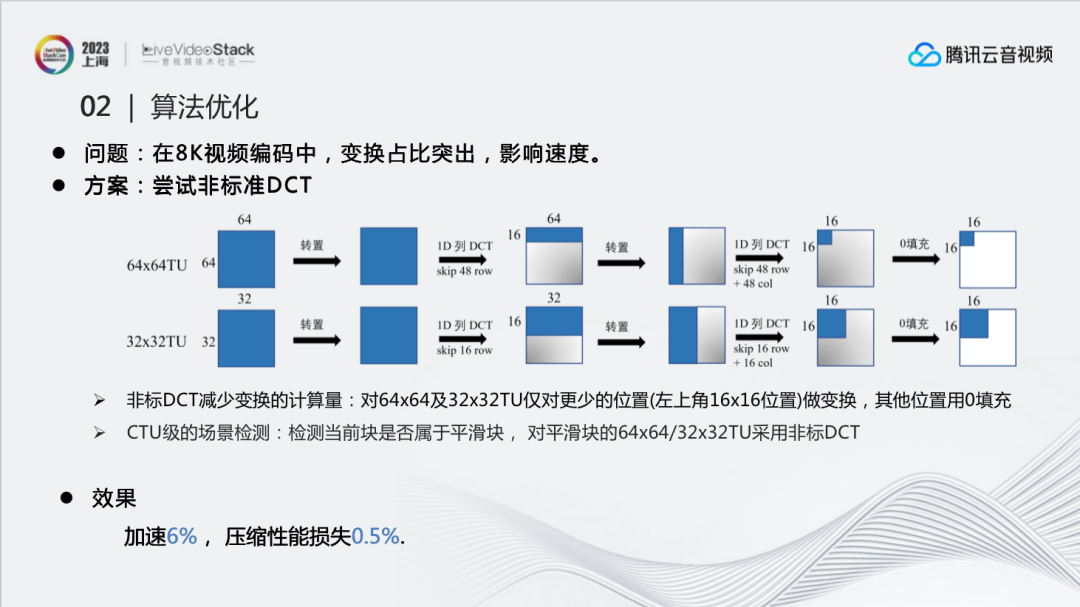
8K场景下一些加速算法的优化同样会出现的新问题。比如,在8K中,变换过程占比更加突出,影响编码速度。因此尝试了使用非标准DCT来简化DCT过程进行加速。比如针对64x64的块,只对前16行进行DCT的列变换,转置后,也仅针对16行再次进行列变换,这样就仅对较少的位置变换,其他位置用0填充。通过这样的处理,能够减少50%-60%DCT正变换的时间。由于DCT变换在8K场景中占比较大,所以这个节省的时间也是非常明显的。
但实现时发现,这个加速算法会对一些边界清晰的块造成比较大的性能损失,比如纹理比较复杂的图像、字的边缘、人的眼睛等。所以这里尝试进行了CTU级的场景检测,使用预分析得到的图像复杂度信息,检测当前块是否属于平滑块,同时避免了额外的计算量。通过这种方式,就完成了只针对平滑块的64x64/32x32TU采用非标准DCT变换。最终效果能够加速6%,压缩性能损失0.5%。
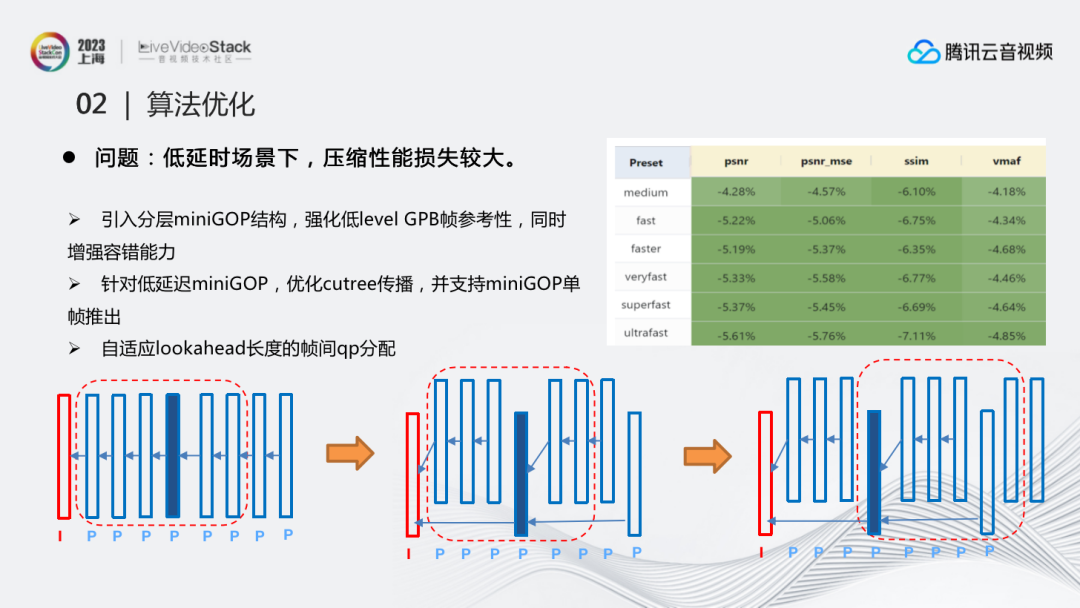
在低延时直播场景下,为了避免压缩性能损失较大,也需要进行优化。上图为低延时场景下常用的IPPP结构,分析这种结构的性能时发现,由于在低延时场景下单纯使用前一帧作为参考,导致每一帧得到的QP偏移量是相似的,也就是说每一帧的重要性是相同的,属于同一层,没有做到分层状态。所有帧都处在同一层很多时候对编码器来说是不好的,比如常用的分层结构,对于越低层的帧就会有越小的QP,这样能够更好地提高压缩性能。
因此提出的优化方案是,引入以4帧为一组的miniGOP结构,调整参考关系,针对这种低延迟miniGOP,优化cutree传播, 强化低level帧参考性,这样便自然而然地进行了分层,同时增强了整体的容错能力。进一步的,为了保证在lookahead长度较短时的,低层帧的性能, 通过调整输出为单帧推入推出的结构,保证了低层帧推出时能最大限度利用后向的时域依赖性完成帧间的QP计算。利用结构和算法的改动,让QP在不同层进行更好地分布,达到最终的优化效果,在低延时直播场景下,性能提升十分明显。
3.3 主观优化
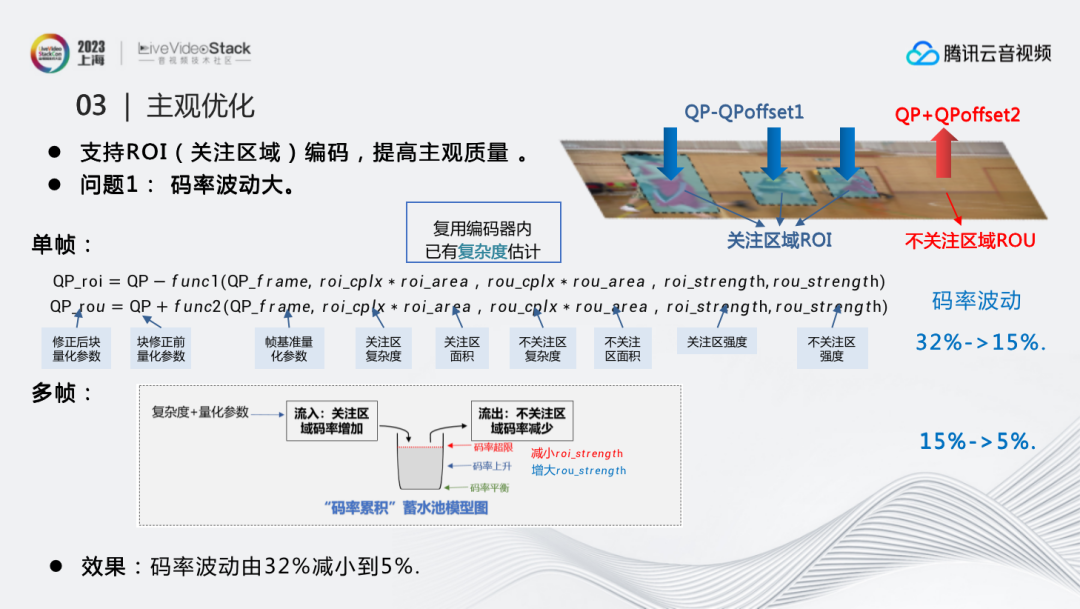
为了进一步提升在直播场景下的主观质量,我们加入了对ROI(关注区域)编码的支持,以提高人眼关注区域的质量。但同时ROI功能的添加也产生了2个问题:
问题1:码率波动大。因为ROI调整了图像的QP分布,使得实际码率和目标码率相比产生了比较大的码率波动。为了解决这个问题, 我们从帧内和帧间两方面进行了优化:首先,对于帧内,为了更好地找到ROI和ROU区域的QP偏移,通过对ROI和ROU区域的强度、面积及复杂度进行函数拟合,调整了QP的计算公式:
QP_roi=QP−func1(QP_frame, roi_cplx∗roi_area,rou_cplx∗rou_area,roi_strengtℎ,rou_strengtℎ);
QP_rou=QP+func2(QP_frame, roi_cplx∗roi_area,rou_cplx∗rou_area,roi_strengtℎ,rou_strengtℎ)。
这里的复杂度延伸了编码器本身对块的复杂度评估,所以没有额外的计算量。这时码率波动由32%减小到15%。
其次,对于帧间,为了进一步减少帧间图像间的码率波动,我们调整了码率的蓄水池模型,使其能够通过调整ROI强度,进一步优化码率波动。当码率上升的时候,就增大ROU的强度,降低码率;但当码率持续上升到一定阈值,就要减少ROI的强度,进一步降低码率, 反之亦然。通过这一系列手段,将码率从15%降低到了5%,达到了我们码率控制的预期。
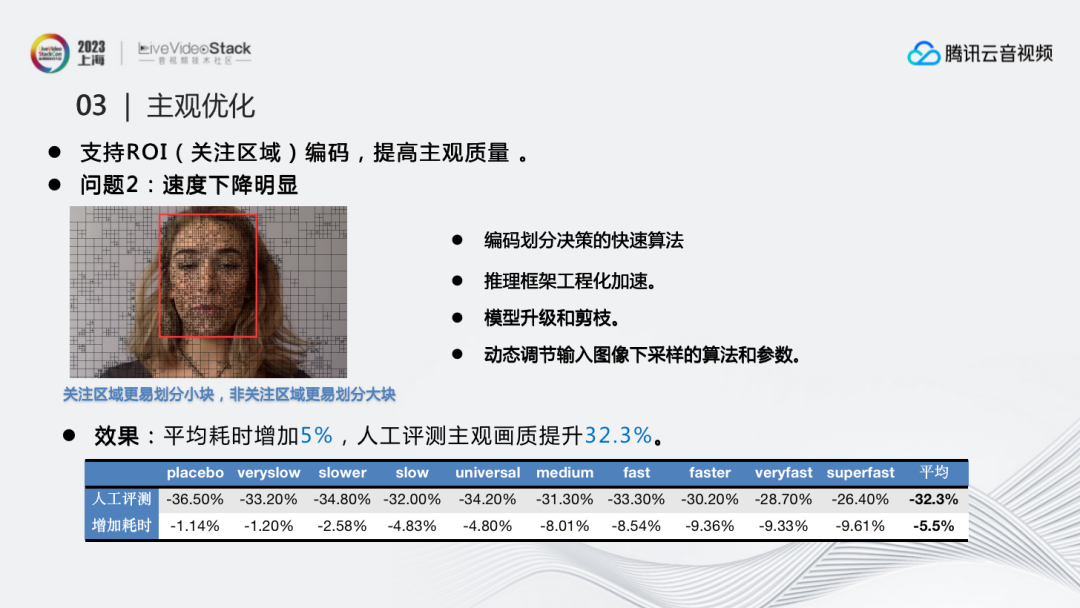
问题2:速度下降明显。我们同样从两方面进行了优化:首先是编码划分决策的快速算法优化,因为关注区域更容易划分小块,而非关注区域更容易划分大块。既然已经划分出ROI和ROU,我们就可以根据不同区域,调整它的划分决策算法。通过这样的方式能够在编码方面提升速度。
同时我们也进行了相应的工程优化,比如推理框架工程化加速、模型升级和剪枝、动态调节输入图像下采样的算法和参数等等。
最终效果达到平均耗时仅增加5%,人工评测主观画质提升32.3%,比较显著地提升了主观效果。
3.4 其它

前面仅是其中的一部分优化,除此之外还有很多。
算法上:例如自适应Intra跳过算法、预分析MVP跳过算法、预分析分像素ME跳过算法、预分析Intra 模式搜索优化、Inter search模式跳过算法优化、Intra 色度模式RD搜索优化、Inter compound 模式跳过算法、参考帧选择算法优化、滤波分层跳过算法、基于参考块信息的滤波快速算法等。
工程上:例如CTU编码优化、CTU参考模式信息拷贝优化、Intra 参考像素拷贝优化、Tile syntax 更新优化、CTU残差信息拷贝优化、编码信息统计优化、Cost表计算优化、扩边优化、重建拷贝优化等。
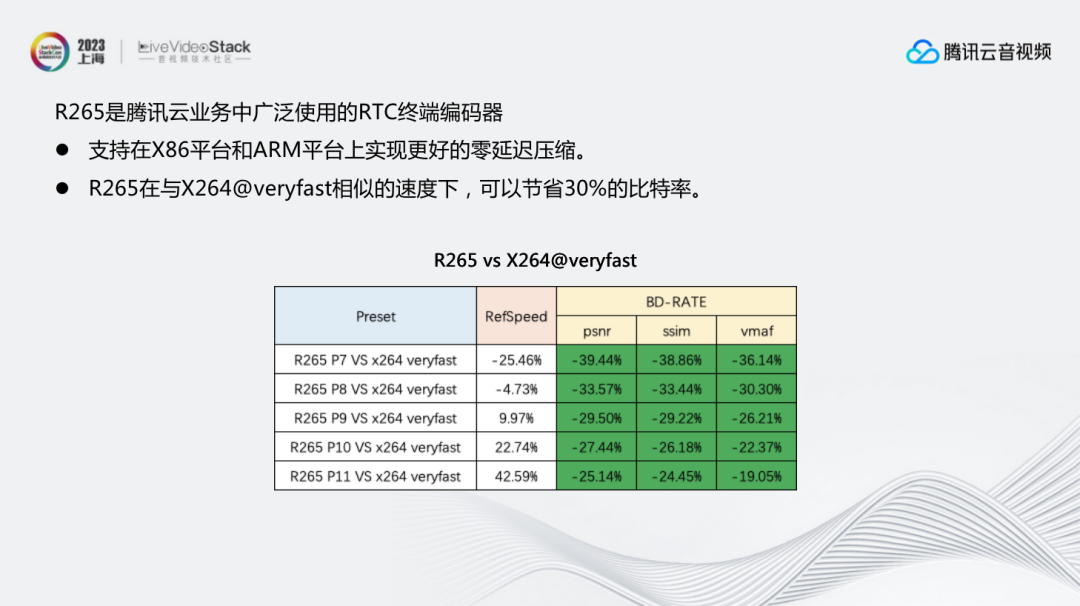
最后补充一点,我们团队不仅有服务器端编码能力,还通过腾讯云对外输出R265终端直播的实时编码能力,目前已经在腾讯云终端上广泛使用。其能够支持在X86平台和ARM平台上实现更好的零延迟压缩。R265在与X264@veryfast相似的速度下,可以节省30%的比特率。
我的分享到此结束。

LiveVideoStackCon是每个多媒体技术人的舞台,如果您在团队、公司中独当一面,在某一领域或技术拥有多年实践,并热衷于技术交流,欢迎申请成为LiveVideoStackCon的出品人/讲师。
扫描下方二维码,可查看讲师申请条件、讲师福利等信息。提交页面中的表单完成讲师申请。大会组委会将尽快对您的信息进行审核,并与符合条件的优秀候选人进行沟通。

扫描上方二维码
填写讲师申请表单