宁波网站推广外包服务如何做网站需求表格清单
100. 相同的树 - 力扣(LeetCode100. 相同的树 - 力扣(
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
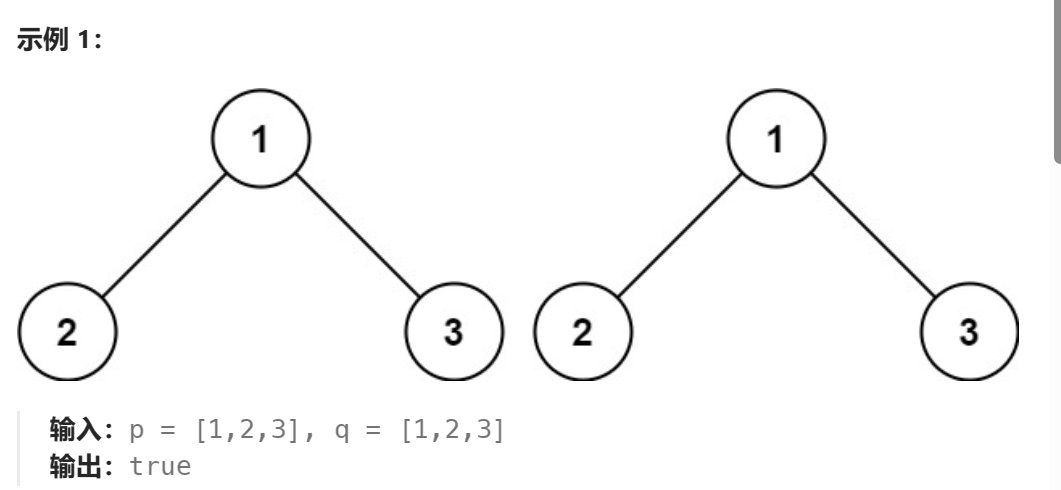
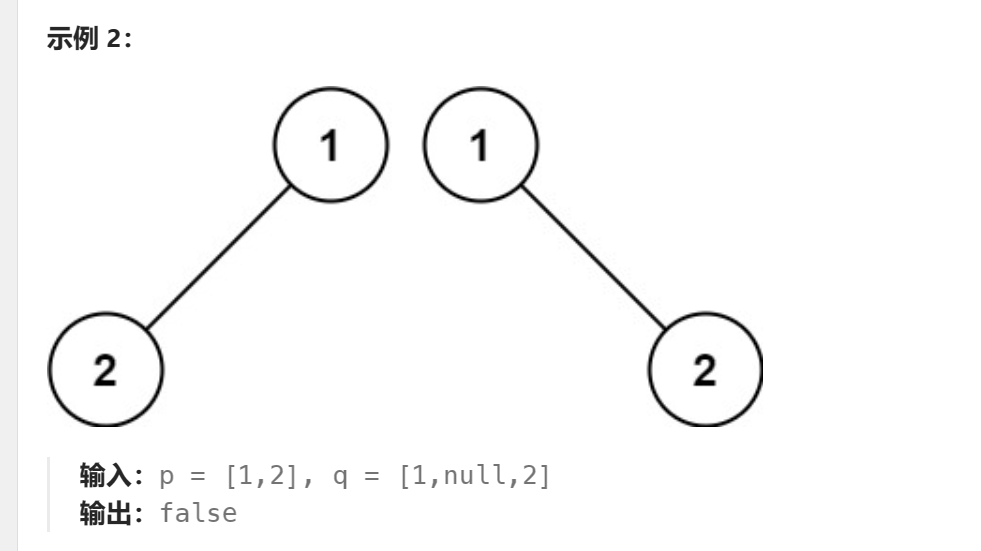

/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {if(p==NULL && q==NULL){return true;}if(p==NULL || q==NULL){return false;}if(p->val!=q->val){return false;}return isSameTree(p->left,q->left)&& isSameTree(p->right,q->right);}
递归其实大部分人都是想的太复杂了其实可以不先去向递归的展开图,先思考最小子问题就把他当成一个循环来做
