西安火车站建设做网站更赚钱吗
前些天U盘挂掉了,去京东上买了一个宇瞻的16G的黑骑士,结果用GetInfo查了一下主控,发现是2251-61,用了几款量产工具都量产不成功,无奈之下只能采取HDD+的启动方式了。
之前一直都是用Easyboot制作的启动光盘,然后U盘量产时直接将制作好的ISO写入U盘的USB-CDROM分区内。现在不能量产了,尝试了下用UltraISO,启动---写入硬盘映像,可以正常写入U盘但是在DOS下无法启动,无奈之下只能采用grub4dos工具,制作全新的启动菜单。借鉴了各位前辈的帖子后,现总结如下:
后面需要用到的文件的下载地址:http://download.csdn.net/detail/chengli42/4066446
一、准备需要用到的工具:
1、grub4dos(http://sourceforge.net/projects/grub4dos/files/)
2、grubinst(http://sourceforge.net/projects/grub4dos/files/)
3、UltraISO 软碟通,提取映像启动文件,修改ISO用
4、4个映像文件,自己去网上下载
二、U盘可启动处理
使用UltraISO打开WIN7的ISO光盘,选择启动---写入硬盘映像,磁盘驱动器选择U盘,千万不要选错了,选择便携启动---写入新的硬盘主引导记录(MBR)---USB-HDD+,选择写入,等待写入完成。
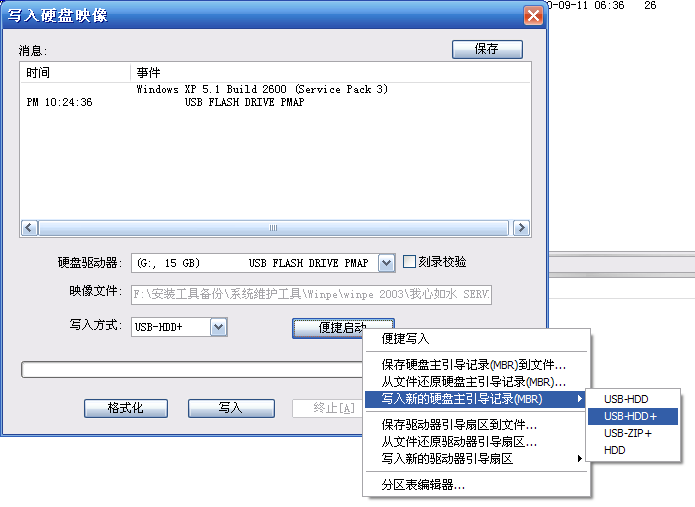
写入启动信息后,顺手将该WIN7的ISO文件中的内容全部提取到U盘的根目录,UltraISO选择操作--提取,提取/下的所有文件到根目录。在提取的文件中,将根目录文件夹sources中的ei.cfg文件删除,这样在安装WIN7时可以选择多版本,而不是仅仅是旗舰版。
三、grub4dos安装
首先将下载的grubinsit文件解压,运行文件grubinsit_gui.exe(vista和win7系统下需要以管理员身份运行,否则找不到U盘)选择目标U盘,设置如图,然后点install。