织梦制作手机网站高级wordpress搜索
目录
- 前言
- 1. 图文界面
- 2. 命令行
前言
由于长期使用Linux界面,对于Window下的Redis,不知如何下手。特此记录该博文
特别注意,刚下载好的Redis,如果需要配置密码,可以再该文件进行配置:redis.windows-service.conf
在配置文件中,找到requirepass foobared文字
在其后面追加一行,输入requirepass 123456
之后重启服务即可生效,对于如何重启服务可看下文
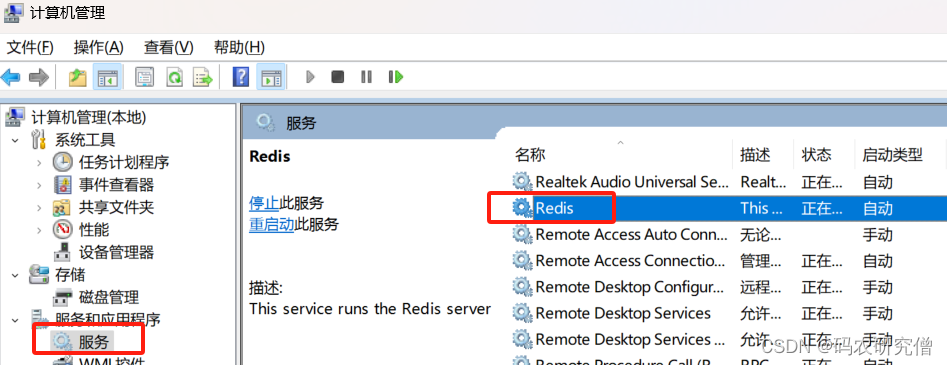
1. 图文界面
可以在计算机->管理->服务
重启Redis服务即可,如果要确定关闭,则需要在Redis服务中关闭即可:
2. 命令行
对于命令行开启与关闭
以下是配置了Redis环境变量,如果没有配置环境变量需要在Redis的安装目录下开启与关闭:
-
启动服务:
redis-server --service-start

-
停止服务:
redis-server --service-stop

还有另外一种方式进行关闭,通过查询其Redis的进程号:tasklist | findstr "redis"

并对其进程号进行关闭:taskkill /pid 11548 -f (该命令的执行需要在管理员下的cmd)