拖拽式wordpress建站工程公司税率是多少
引言
TCP每一次发送报文段,就会对这个报文段设置一次计时器。如果时间到了却没有收到确认报文,那么就要重传该报文。
这个之前在TCP传输的机制中提到过,这个章节就来研究一下超时时间问题。
关于加权的概念
有必要提及一下加权的概念,这属于数学知识,但可用帮助我们理解超时重传机制。
权是在测量时不同的精准度,加权就是乘上权重/系数的含义,加权是对精准度的一种测量。
比如说:你参加了一个竞赛,专家、老师和学生分别为你打分。最后分数进行计算后作为总成绩。我们下意识认为是(8+6+7)/3=7这样通过加法平均数的方式进行计算。但是在你看来不公平!因为你认为专家是懂竞赛的,不应该因为老师的打分和学生的随意而影响了总成绩。因此赛事委员设置专家的权重和老师及学生的权重为0.5:0.3:0.2,那么加权后就是8*0.5+6*0.3+7*0.2=7.2。这样相对更加公平。下图就是加权的计算方式。
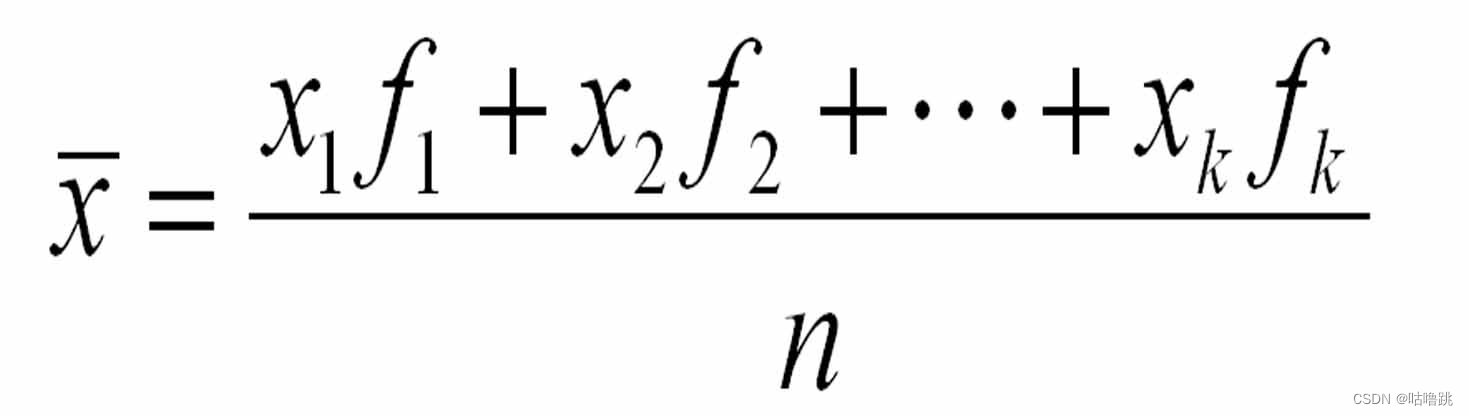
好了,此时就能对超时重传时间进行描述了。
超时重传时间
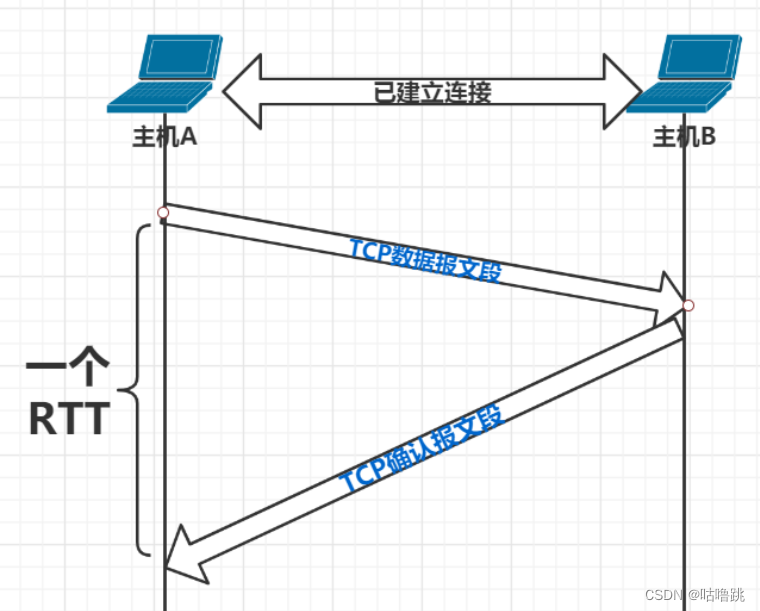
下图所示,TCP数据报文发送直到TCP确认报文回馈的这段时间为一个RTT时间。这个之前也提到过。
但是会出现以下两种情况:
一,超时重传时间远远小于一个RTT时间,那么就会导致ACK信息还没到达前,请求重传就发出了,结果ACK到达了,重传发出后的请求又导致重复的信息再次发送了。占用了大量带宽!
二,如果超时重传时间远远大于一个RTT时间,那么一旦出现问题需要重传了,超时重传的请求隔了很久才到达,大大影响了网络使用空间。
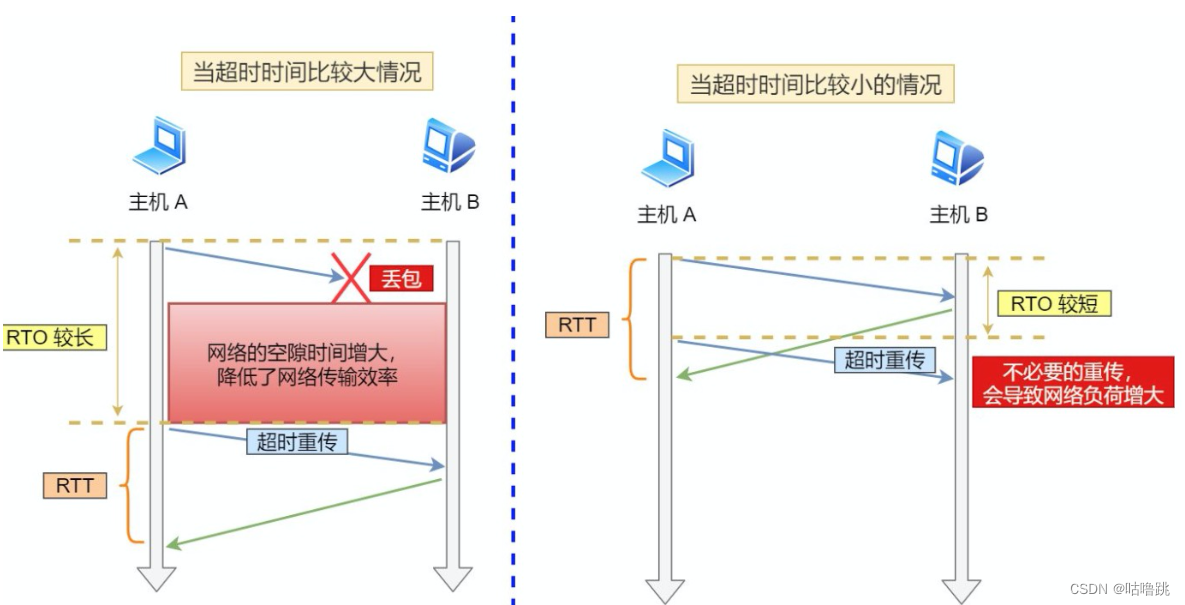
上图是两种可能发生的情况
为了避免上述情况的发生,超时重传的时间应该略微大于RTT时间,可是问题来了,怎么保证呢?这时就要采用加权计算的方式了。
我们知道每个报文在一段时间内的传输速率不同,因此重传时间不应该是一个固定值,而是随着RTT值的变动而变动且要略大于RTT值。我们此时假设RTO为超时传输时间,RTTs为加权的平均往返时间。那么就有如下计算方式:

我们得出了加权的RTTs的值,这个数值决定了各个阶段RTT在加权情况下的往返时间,随后,我们要使得RTTO略微大于RTTs即可,那么有以下计算公式:
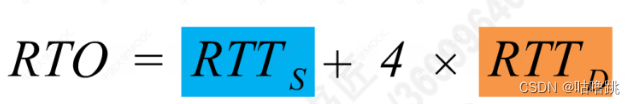
我们知道RTTs是上述的加权平均往返时间,那么RTTD是什么呢?
RTTD为RTT的偏差的加权平均值。官方建议这样计算:第一次测量时,RTTD的值取为测量到的RTT样本值的一半。在以后的测量中,使用以下公式计算加权平均RTTD的值。

它的计算方式和RTTs计算方式大同小异,我认为RTTD是为了进一步精准确定RTTs的范围,将RTTs的加权平均值和4倍的RTTD的偏差加权平均值放在一起就能得到RTO的值。
好了,确定了RTO的数值,我们就可以重传了,而每一次重传又会发生两种情况好了,新问题又来了:
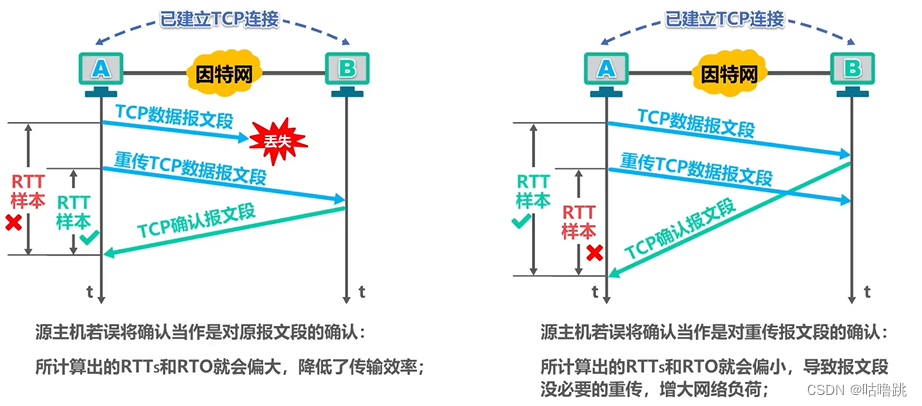
也就是说,重传时,问题又会出现之前RTT的情况,此时的RTO如果不进行更改,那么问题会再次显现。
那么此时引入了一个算法(Karn算法),公式是:

其中“r”的值为2,每一次重传都会将旧的超时重传时间扩大2倍。当报文段不再重传时,才会根据报文段的往返时延更新平均往返时延RTT和超时重传时间RTO的数值。这样的好处是,我不需要对重传报文的往返时间重新计算了。