綦江网站建设公司网站图片有什么要求吗
cat +文件名 查看文件内容,
tac+文件名 倒着显示。
more +文件名 显示内容
less+文件名 和more的功能一样,按上下左右键,按Q键结束。
head+文件名,只显示前10行内容。
ln是一个默认创建硬链接的命令
ln +文件名
ls -i+文件名,
软连接: ln -s 文件名

 并且
并且


which 命令 可查看命令在哪里。
管道命令给到cut——grep “Linux” /etc/passwd |cut -c 1取一个字母。

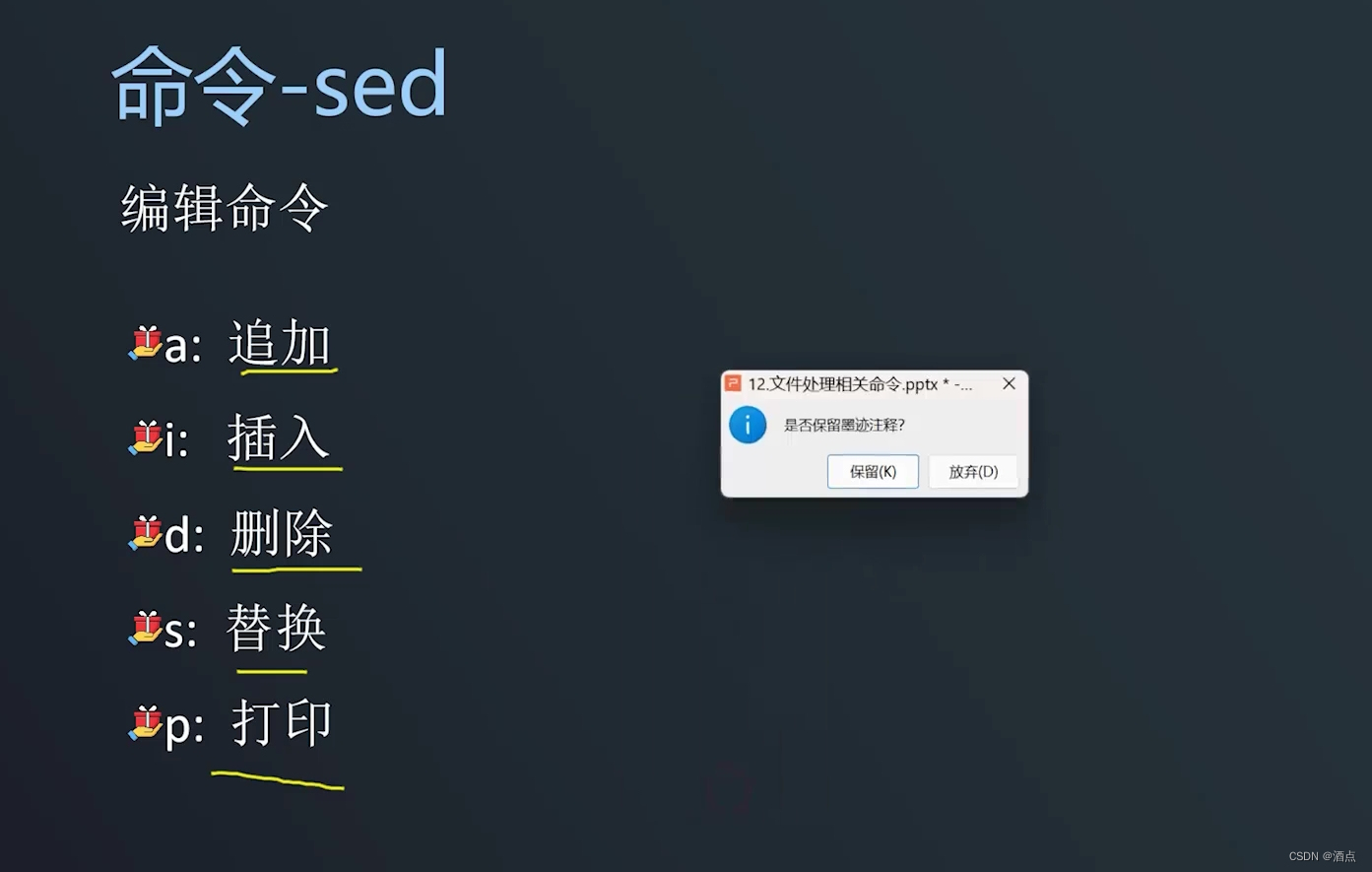
sed -n 'p' 文件名 ——打印
sed -i 'd' 文件名——删除
sed 's /linux/LINUX/'文件名 ——文件名中的……替换
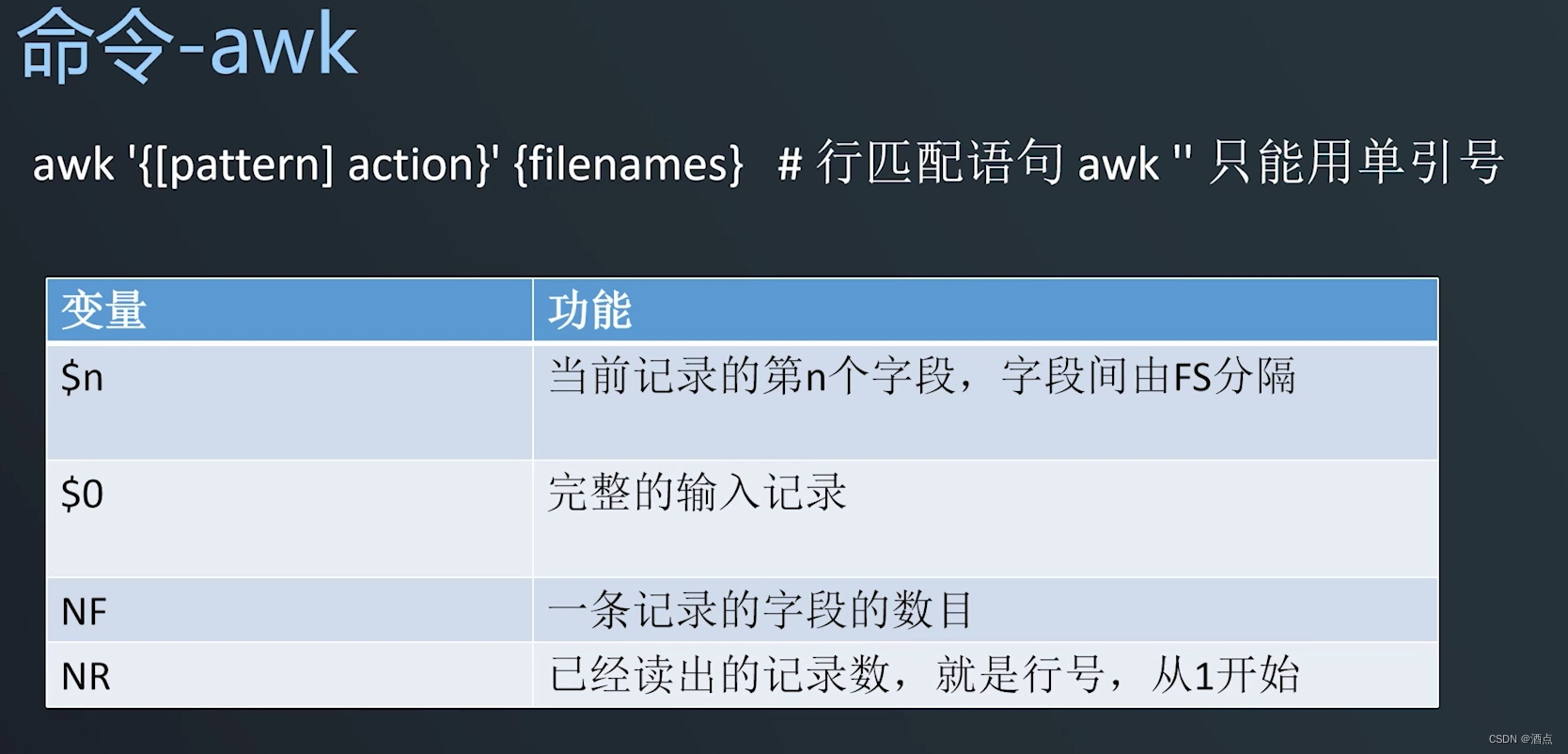
awk'{print $NF}' 文件名
awk'{print $1}' 文件名
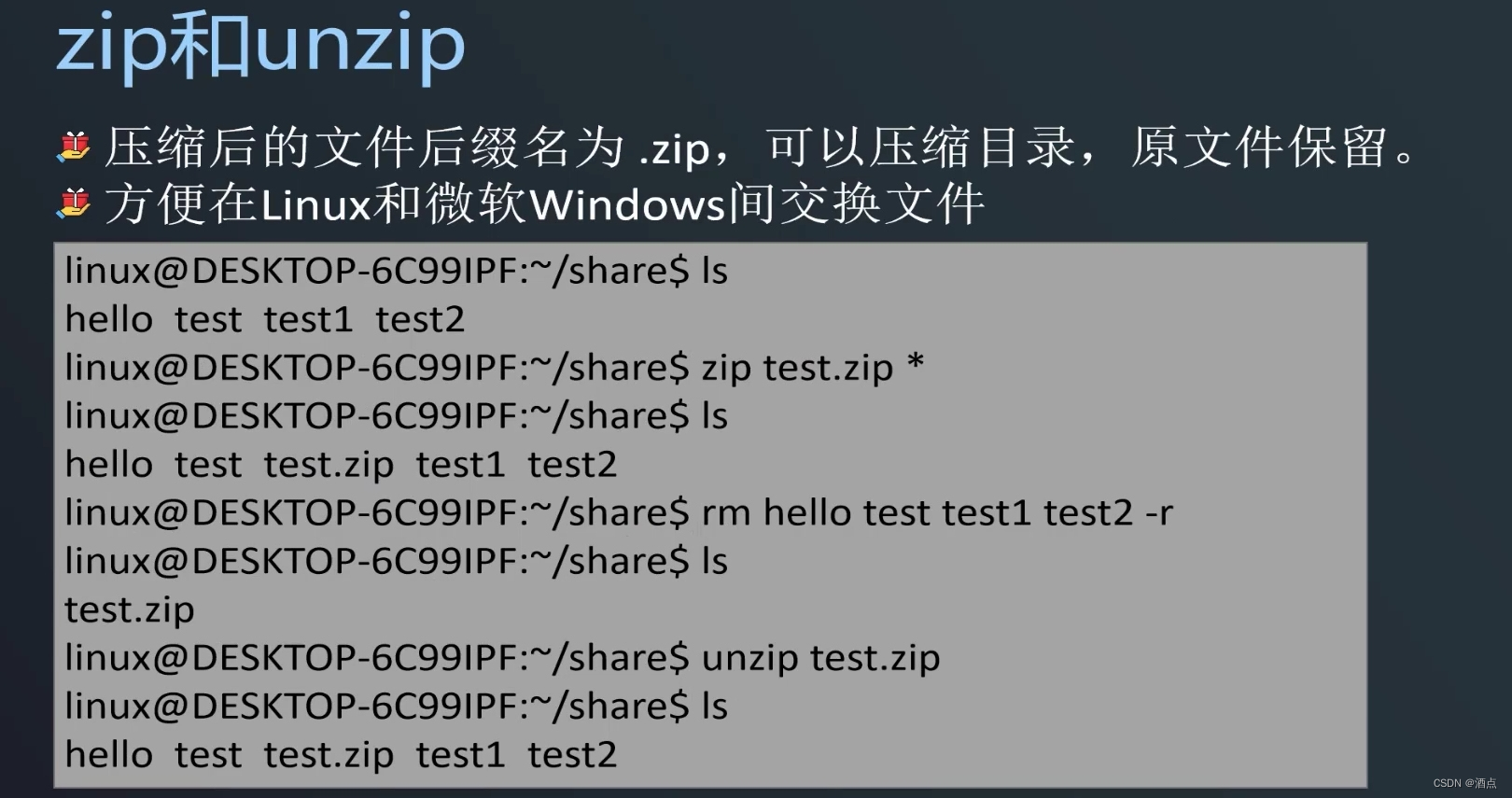
2-解压缩命令
归档和压缩。

mkdir建目录。touch创建文件。
gzip 文件名即可压缩文件
gunzip文件名即可解压文件


归档到tar文件里面 tar -c (test.tar)文件名 1 2
tar -xvf 文件名,释放。