阆中市网站建设服务天津建站费用
文章目录
- 1.打造网关
- 1.1 简介
- 1.2 连接模式
- 1.3 打造网关
- 2.身份认证与授权
- 2.1 身份认证方案
- 2.1.1 JWT是什么
- 2.1.2 启用JwtBearer身份认证
- 2.1.3 配置身份认证
- 2.1.4 JWT注意事项
1.打造网关
1.1 简介
BFF(Backend For Frontend)负责认证授权,服务聚合,目标是为前端提供服务。BFF是在前后端分离架构出来后才出现的,为前端提供单纯的API样式的网关。
在微服务架构中网关和BFF的区别实际不大,二者之间的职责可以是重叠,聚合的,本质来讲BFF模式是网关职责的一种进化。
1.2 连接模式
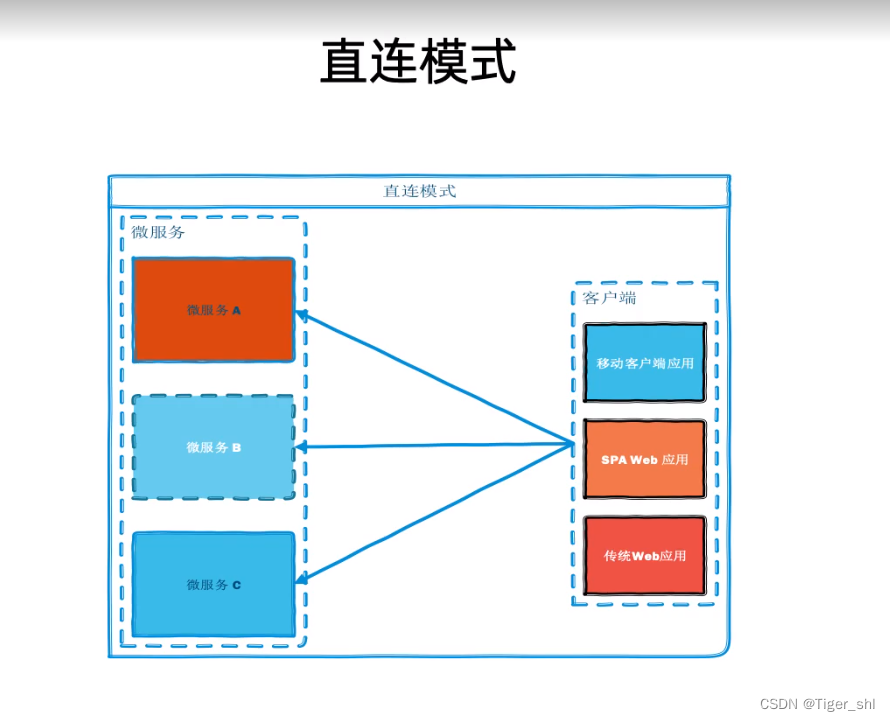
传统的连接模式
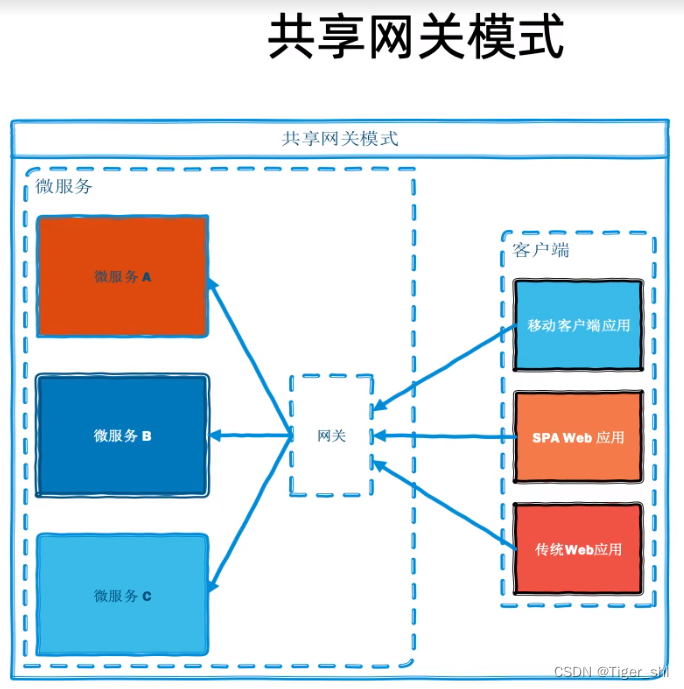
共享网关模式的好处是统一的入口,所有的应用程序通过单一的网关进行请求,适合网关比较强大并且所有接口都在网关上注册,要求网关的可用性比较高。
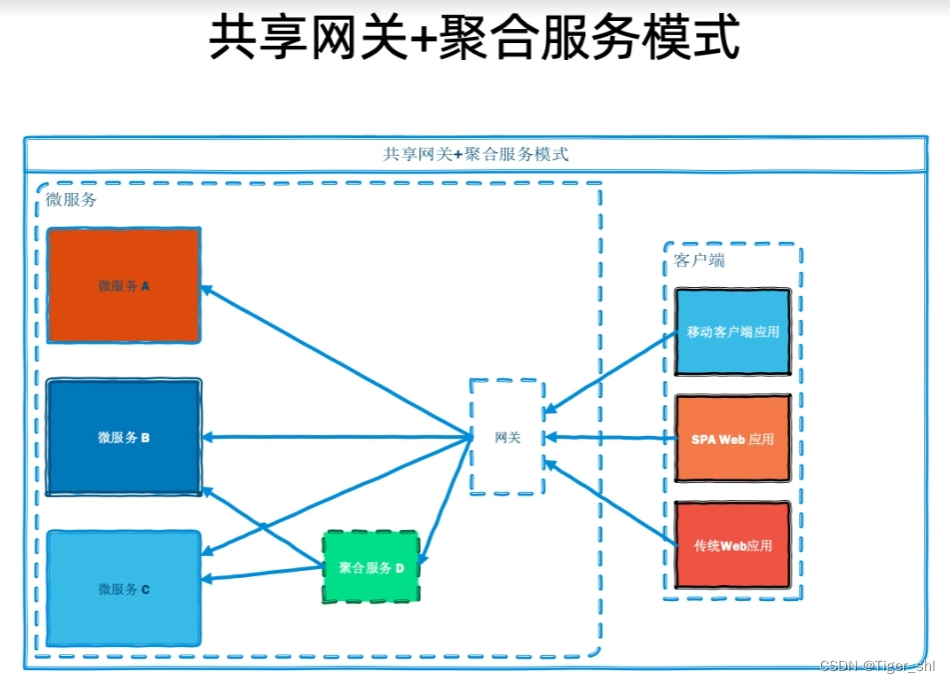
随着业务的发展,单个服务并不能满足要求,很可能需求是需要跨微服务之间进行组装数据,这时候就出现了聚合服务。聚合服务可以单独作为一个服务存在微服务的体系下,也是通过网关去访问它,实际上聚合服务也可以设计在网关中,这样的网关实际上就类似于BFF。
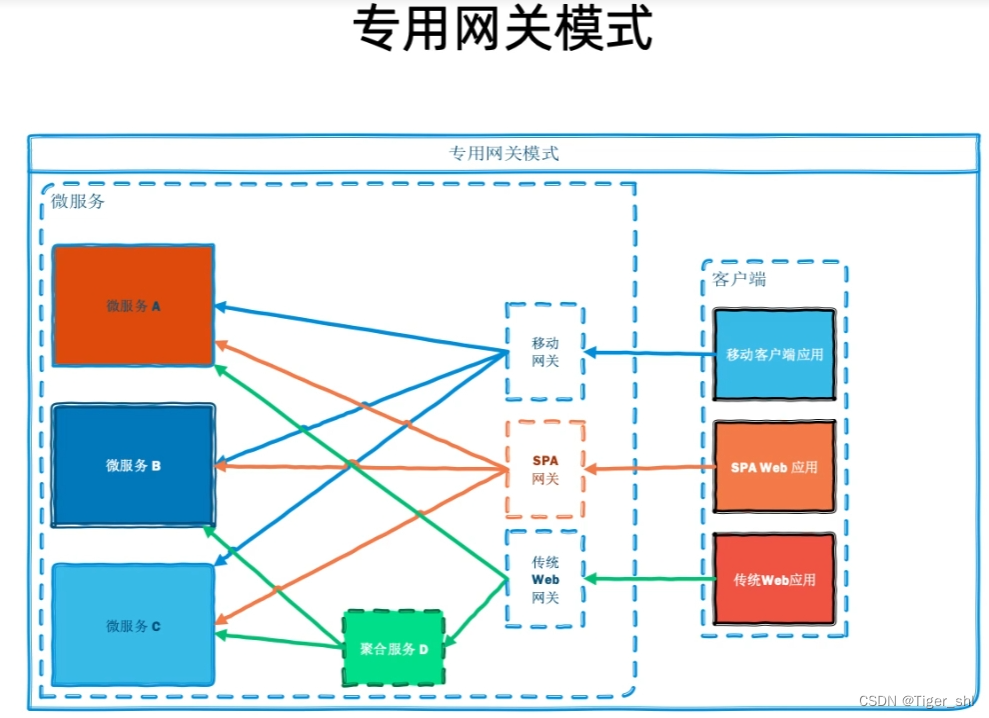
专用网关模式指的是针对不同的客户端采用不用的网关,比如将移动端和PC的网关分开。这样的好处在于,不同的客户端所依赖的网关是不同的,可以使故障隔离,不用端之间是不会收到相互之间的影响;同时也可以为不同端设计不同的数据聚合接口,暴露不同的微服务Api。不同业务线之间只要维护自己的网关,同时根据自身业务线去进行业务的拆分
1.3 打造网关
- 添加包Ocelot 14.0.3
- 添加配置文件ocelot.json
- 添加配置读取代码
- 注册Ocelot服务
- 注册Oceot中间件
// startuppublic Startup(IConfiguration configuration)
{Configuration = configuration;
}public IConfiguration Configuration { get; }public void ConfigureServices(IServiceCollection services)
{services.AddOcelot(Configuration);
}public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{... app.UseOcelot().Wait(); // 放最后是为了让网关内置的 Api仍然生效
}
2.身份认证与授权
2.1 身份认证方案
- Cookie
- JWT Bearer
2.1.1 JWT是什么
- 全程 Json Web Tokens
- 支持签名的数据结构
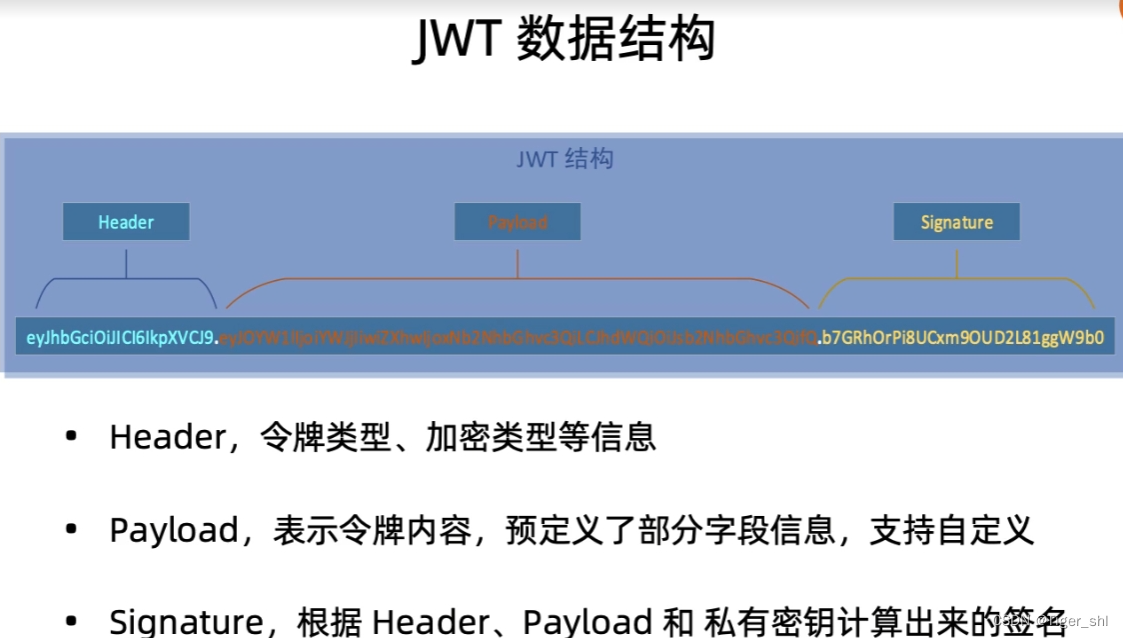
2.1.2 启用JwtBearer身份认证
- Microsoft.AspNetCore.Authentication.JwtBearer
2.1.3 配置身份认证
- Ocelot网关配置身份认证
- 微服务配置认证与授权
// appsetting.json配置秘钥
{"Logging": {"LogLevel": {"Default": "Information","Microsoft": "Warning","Microsoft.Hosting.Lifetime": "Information"}},"SecurityKey": "aabbccddffskldjfklajskdlfjlas234234234"
}// startup 配置var secrityKey = new SymmetricSecurityKey(Encoding.UTF8.GetBytes(Configuration["SecurityKey"]));services.AddSingleton(secrityKey);services.AddAuthentication(CookieAuthenticationDefaults.AuthenticationScheme).AddCookie(CookieAuthenticationDefaults.AuthenticationScheme, options =>{}).AddJwtBearer(JwtBearerDefaults.AuthenticationScheme, options =>{options.TokenValidationParameters = new TokenValidationParameters{ValidateIssuer = true,//是否验证IssuerValidateAudience = true,//是否验证AudienceValidateLifetime = true,//是否验证失效时间ClockSkew = TimeSpan.FromSeconds(30),ValidateIssuerSigningKey = true,//是否验证SecurityKeyValidAudience = "localhost",//AudienceValidIssuer = "localhost",//IssuerIssuerSigningKey = secrityKey//拿到SecurityKey};});// 注册
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{...// 这两个需要注册在UseEndpoints之前app.UseAuthentication();app.UseAuthorization();app.UseEndpoints(endpoints =>{endpoints.MapHealthChecks("/live");endpoints.MapHealthChecks("/ready");endpoints.MapHealthChecks("/hc", new Microsoft.AspNetCore.Diagnostics.HealthChecks.HealthCheckOptions{ResponseWriter = HealthChecks.UI.Client.UIResponseWriter.WriteHealthCheckUIResponse});endpoints.MapControllers();endpoints.MapDefaultControllerRoute();});app.UseOcelot().Wait();
}2.1.4 JWT注意事项
- Payload信息不宜过大
- Payload不宜存储敏感信息