网站建设平台报价安徽省住房与城乡建设厅网站
在当今快节奏的开发环境中,实现无缝、稳健的 CI/CD 流水线对于交付高质量软件至关重要。在本文中,我们将向您介绍使用 Bitbucket Pipeline、ArgoCD GitOps 和 AWS EKS 设置部署的步骤,所有步骤都将利用 Terraform 的强大功能进行编排。在Part 1里,将主要介绍通过 Terraform 创建和部署 CI/CD 流水线的前三步。
使用 Terraform 创建 AWS EKS Infra
我们有两种环境,一种是 Private Node + 2 NAT,另一种是 Public Node + 1 NAT。
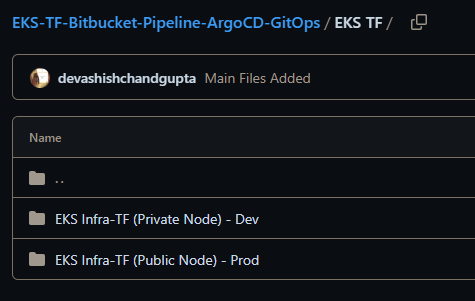
为了演示,以下将使用一个 AWS Ubuntu 22.04.3 LTS EC2 实例,并附加 AdministratorAccess ,从而实现 Linux 电脑上克隆 repo:

然后将目录更改为:
EKS-TF-Bitbucket-Pipeline-ArgoCD-GitOps/EKS TF/EKS Infra-TF (Public Node) - Prod
或者您也可以使用 Dev 版本,这两个版本完全相同,只是 Dev 版本有 2 个 NAT,而 Prod 版本只有 1 个 NAT。
现在,在将此应用于创建 AWS EKS Infra 之前,您需要做以下事情
- 在个人电脑上安装以下工具(根据操作系统进行选择)
- AWS CLI: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
- Terraform CLI: https://developer.hashicorp.com/terraform/install
- Kubectl CLI:https: //kubernetes.io/docs/tasks/tools/
- 如果要在自己的电脑上运行脚本,请配置 AWS 访问密钥
现在运行 $ terraform fmt 命令来格式化 terraform 代码。

接下来,您可以在 vars.tf 文件中编辑环境名称、K8s 版本和 EKS 部署的地区。
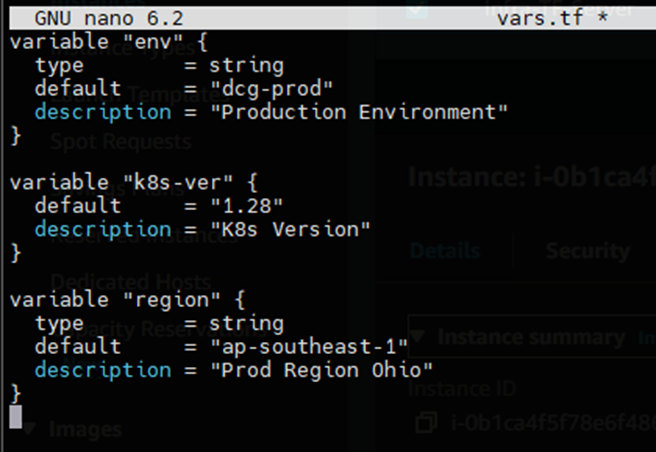
也可以使用 ap-southeast-1 区域,并通过更改 default 保存文件。
同时不要忘记更改 eks-node-groups-policy.tf 文件中的 desired_size 和 instance_types。
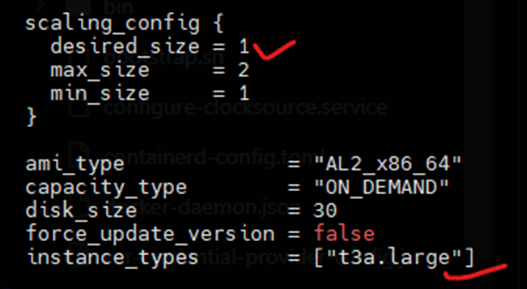
您应该为 Eks 集群节点选择一个中型或更好的大型实例,否则在安装 ArgoCD 或其他应用程序时会遇到问题,因为所有这些 EC2 实例类型都有 pod 数量限制,具体可以在这里查看:https://github.com/awslabs/amazon-eks-ami/blob/master/files/eni-max-pods.txt
现在运行 $ terraform init 下载依赖项:

之后,您可以根据自己的喜好运行 $ terraform plan 或 $ terraform apply。
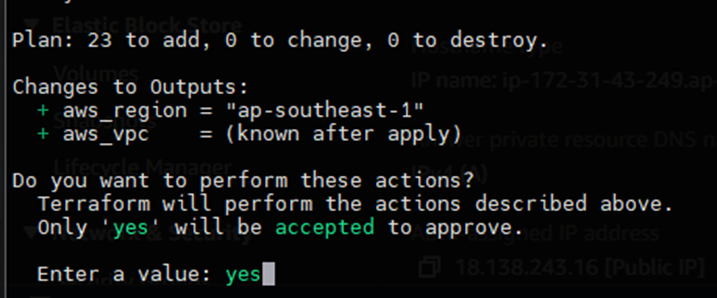
输入值 yes,然后等待完成,最多需要 10-15 分钟。
tf 代码将创建以下 AWS 服务:
- VPC
- 子网
- 子网路由表
- IAM 角色和策略
- 互联网网关
- NAT 网关
- 弹性 IP
- EKS 集群和节点组
当成功完成 tf 脚本后,您将在最后看到类似下面的屏幕:
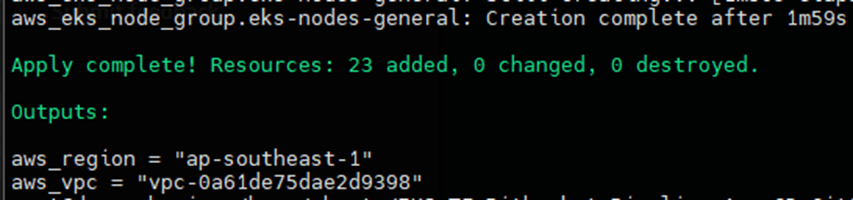
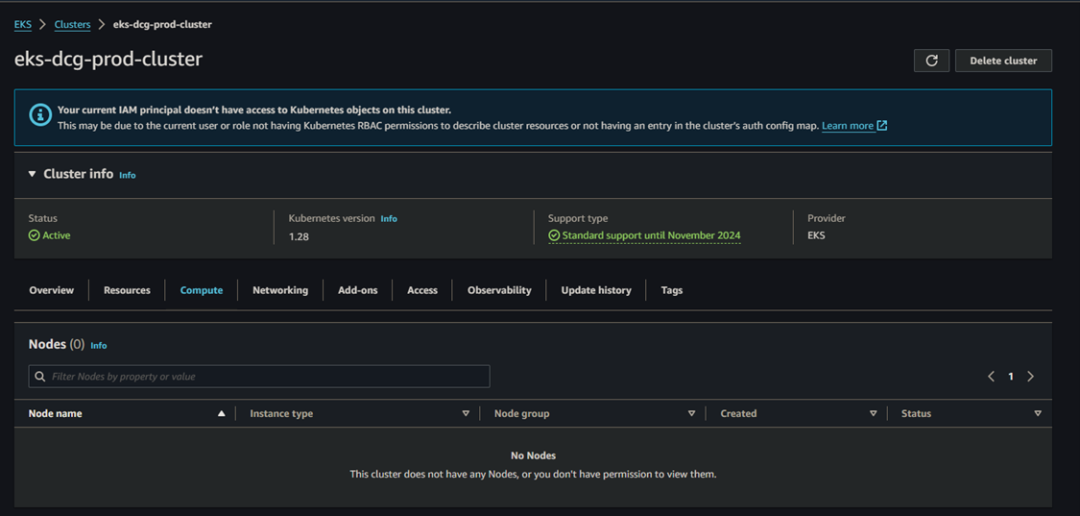
您还可以在 AWS 控制台中查看是否创建了 EKS 集群和所有资源。
现在,我们需要授予 kubectl 对 EKS 集群的访问权限,为此需要运行以下命令:
$ aws eks update-kubeconfig - region region-code - name my-cluster
您需要根据您的环境更新 region-code 和 my-cluster 名称,例如:

然后消除这个警告:

为此,您需要使用以下命令将 IAM 用户名和 arn 添加到 EKS configmap 中:
$ kubectl edit configmap aws-auth -n kube-system
它将打开一个新窗口,如下所示:
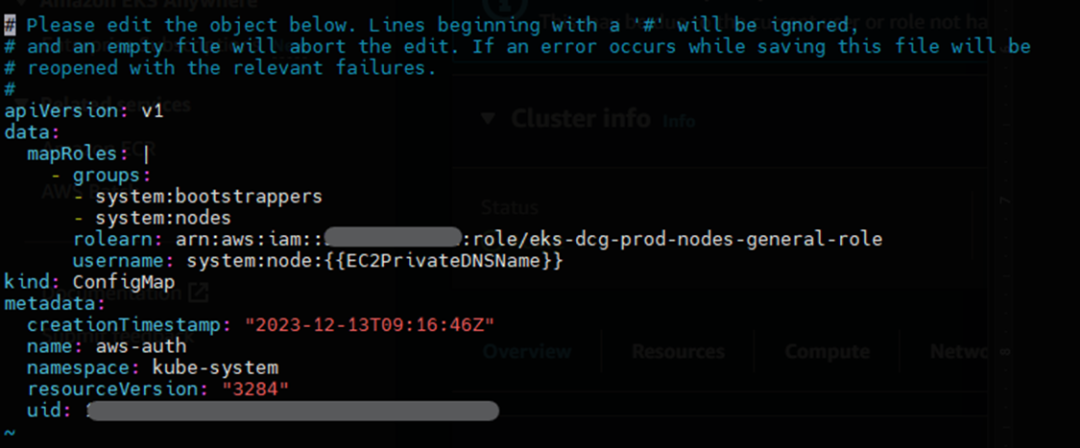
之后,在 mapRoles 段落后添加以下代码:
mapUsers: |— groups:— system:mastersuserarn: arn:aws:iam::XXXXXXXXXXXX:user/devashishusername: devashish
不要忘记更改您试图访问 EKS 控制台的 IAM 用户名。
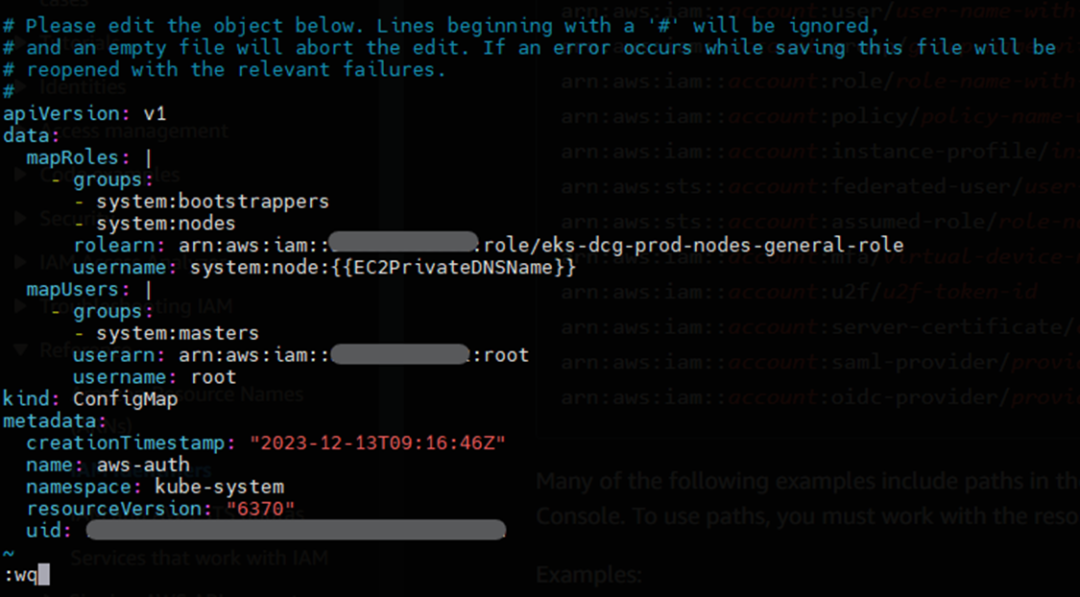
如果使用了 root 权限来创建和访问 EKS 集群,则必须使用 root 的userarn 和 username。
然后用 wq 保存文件,再刷新 EKS 集群页面——现在 IAM 用户警告应该已经消失了。
此外,您还可以在 EKS 集群的 Compute tab 中看到之前由于 RBAC 权限问题而没有出现的 Nodes。
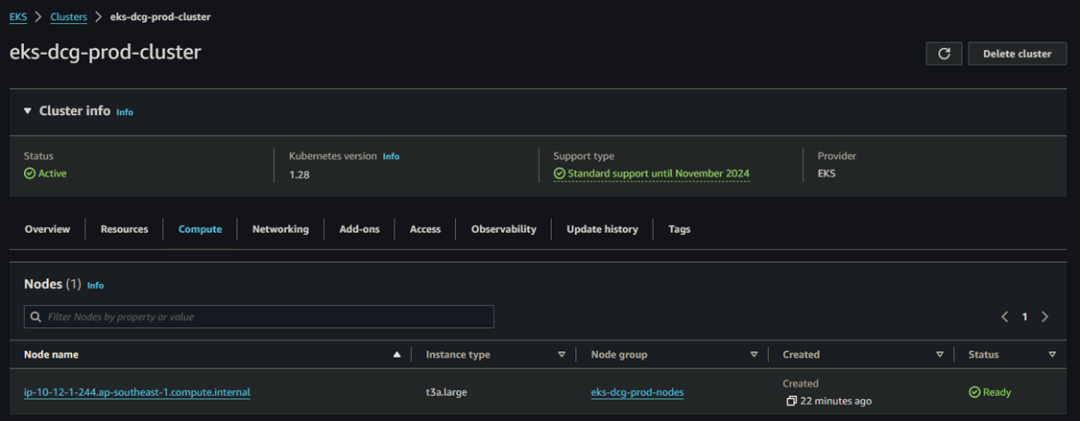
您还可以运行 kubectl 命令来检查 EKS 集群是否与 Kubectl CLI 工具连接。

这样 EKS 集群就已经准备就绪并运行正常了,现在让我们进入下一步。
在 EKS 集群上部署 ArgoCD 及其依赖项
为此,我们将使用 repo 网址:https://github.com/dcgmechanics/EKS-TF-Bitbucket-Pipeline-ArgoCD-GitOps/blob/main/EKS%20Addons/Readme.md ,只需按照文件中的步骤操作即可。
- 安装 ArgoCD

您可以使用以下命令检查正在运行的 ArgoCD pods:
$ kubectl get po -n argocd
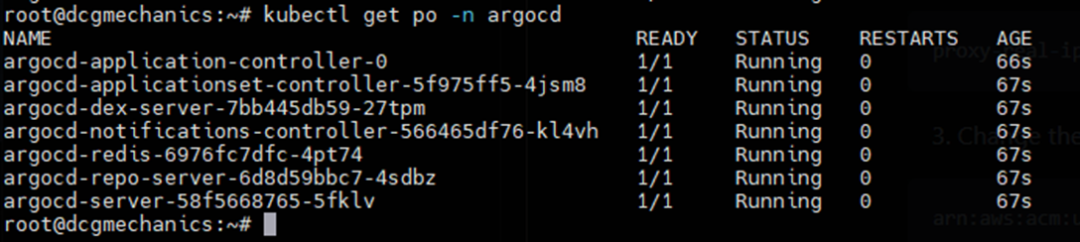
既然 ArgoCD 已经安装完成,现在让我们进入下一步。
- 使用 ACM 为 NLB 部署 Ingress-Nginx
在继续下一步之前,我们需要以下东西:
- VPC CIDR,即 proxy-real-ip-cidr
- AWS ACM 证书 arn id,即 arn:aws:acm
因此,如果没有,请创建它们。
首先,您需要使用 wget 下载 Ingress-Nginx for NLB 控制器脚本。
$ wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/aws/nlb-with-tls-termination/deploy.yaml

然后使用任何文本编辑器打开它。
$ nano deploy.yaml
再根据配置更改这些值。
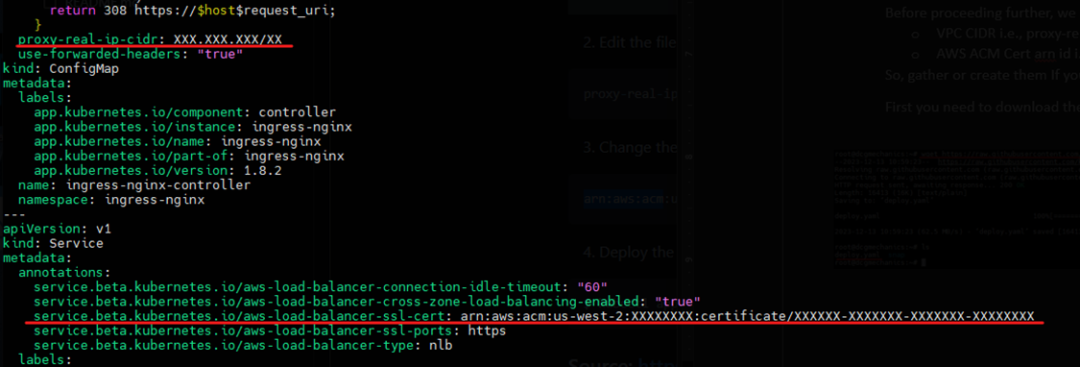
根据您的信息更改值后,请确保在创建 ACM 证书时使用通配符,然后运行以下命令:
$ kubectl apply -f deploy.yaml
- 部署 ArgoCD pod Ingress服务
首先使用 $ nano ingress.yaml 创建一个 YAML 文件,并粘贴 EKS Addons Readme.md 文件中的内容。不要忘记更改 host 值。
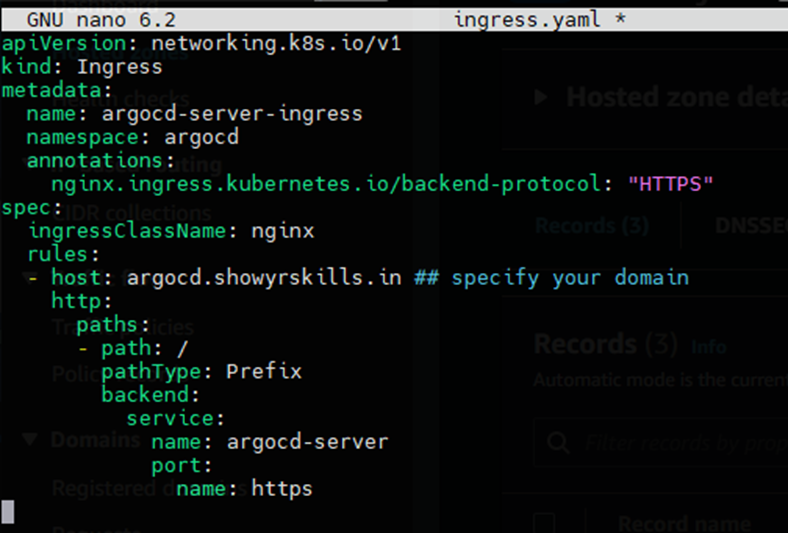
然后运行:
$ kubectl apply -f ingress.yaml
在 EKS 上部署 argocd 服务 ingress 文件。您可以使用以下命令查看服务是否部署成功。
$ kubectl get ingress -n argocd

ADDRESS 值需要一些时间才能显示,所以请耐心等待。然后创建一个 A Record,将 ArgoCD 子域名指向该 NLB。
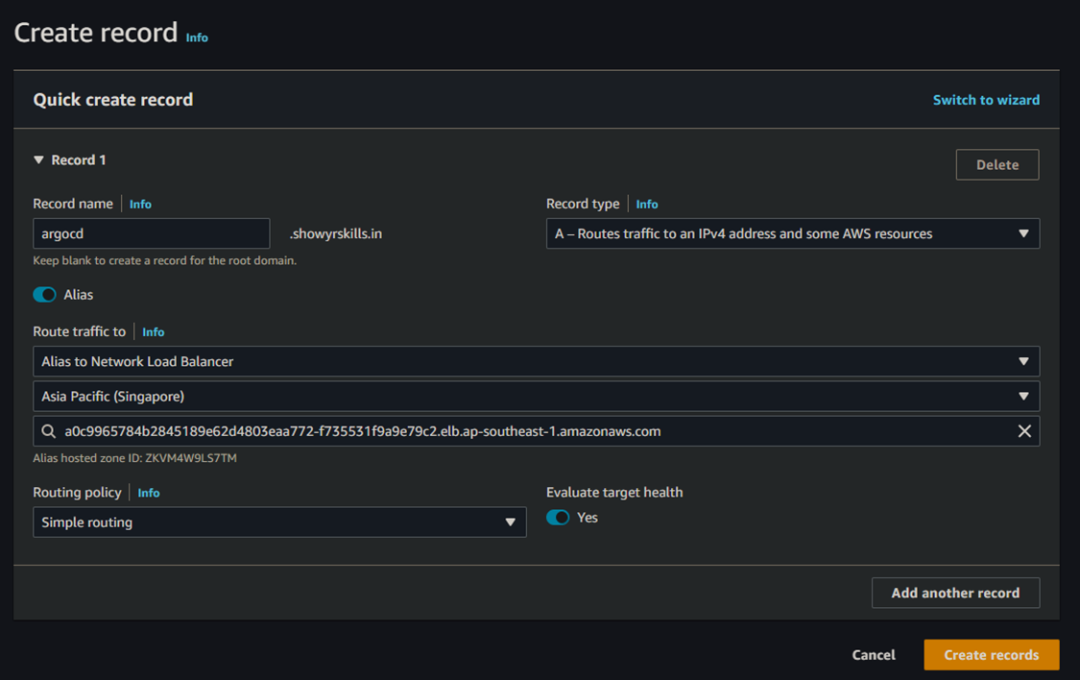
现在,您可以访问网站:https://argocd.showyrskills.in。

从 CLI 恢复密码,然后使用密码登录 ArgoCD,用户名应为 admin。
使用以下命令找回密码:
$ kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo echo echo.| base64 -d; echo
之后就可以成功登录了。
既然 ArgoCD 已经正常运行,现在让我们进入下一步。
设置 Bitbucket Pipeline并部署到 ECR Repo
为此,我们需要创建一个 Bitbucket 和 AWS ECR Repo,其中 Bitbucket Pipeline 将把应用程序部署到 ECR Repo 中。
转到您的 Bitbucket ID 并创建一个新的 repo:
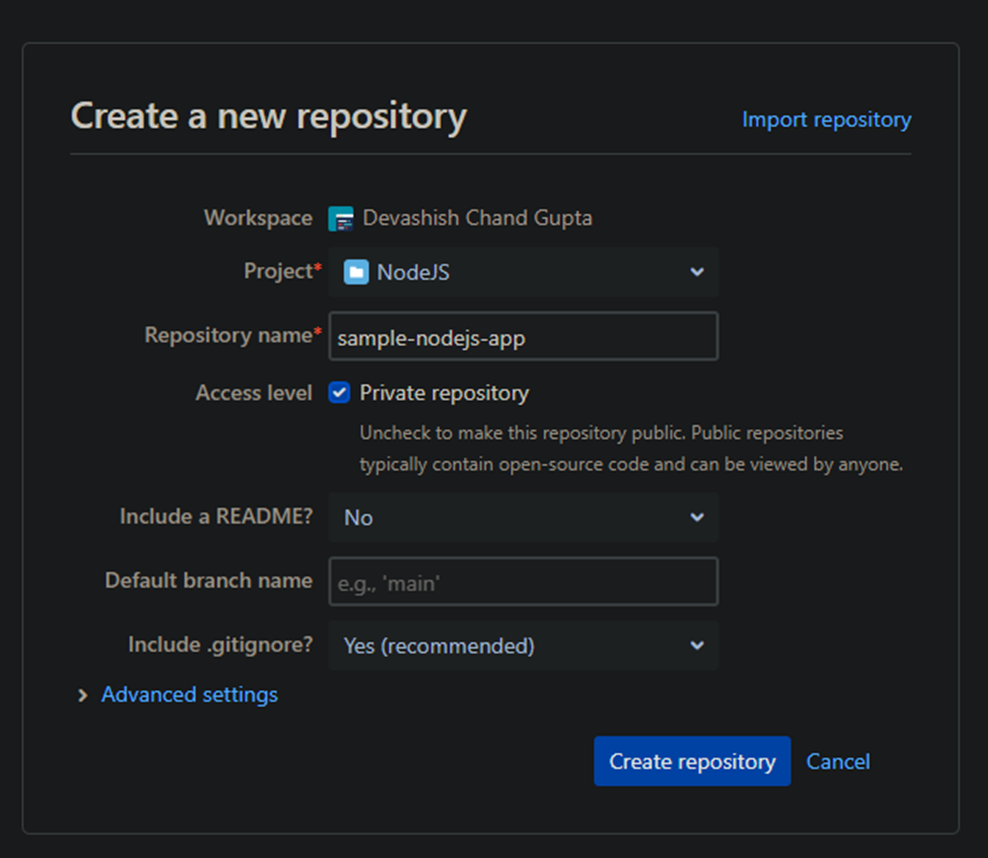
创建 repo 后,我们需要 3 个文件:
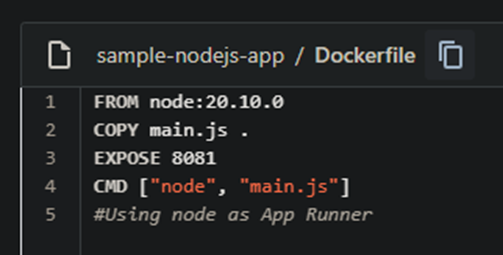
- main.js
- Dockerfile
- bitbucket-pipeline.yaml
在 Bitbucket Pipeline + Dockerfile 文件夹下的repo 中提供了示例文件。
因此,让我们根据您的应用程序创建所有 3 个文件。我将在 main.js 文件中使用示例 node js 应用程序。
请记住,在创建 Bitbucket Pipeline YAML 文件之前,先创建 AWS ECR Repos,因为运行中需要它。例如,在 AWS ECR 中创建了以下私有 repo。
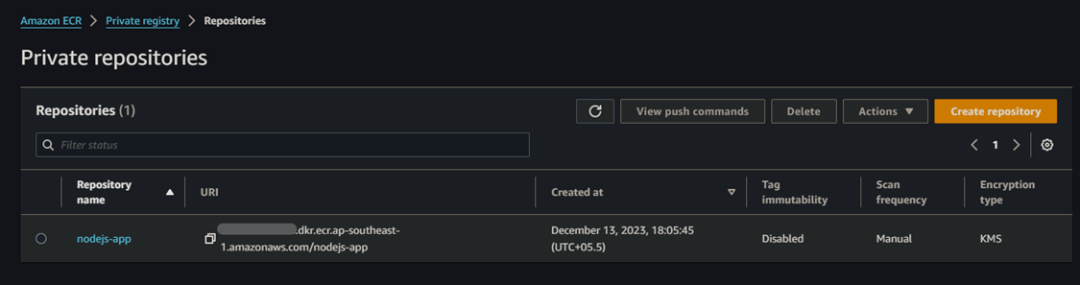
现在,我们需要将 ECR 仓库中的一些值复制并粘贴到 Bitbucket Pipeline 的 YAML 文件中。
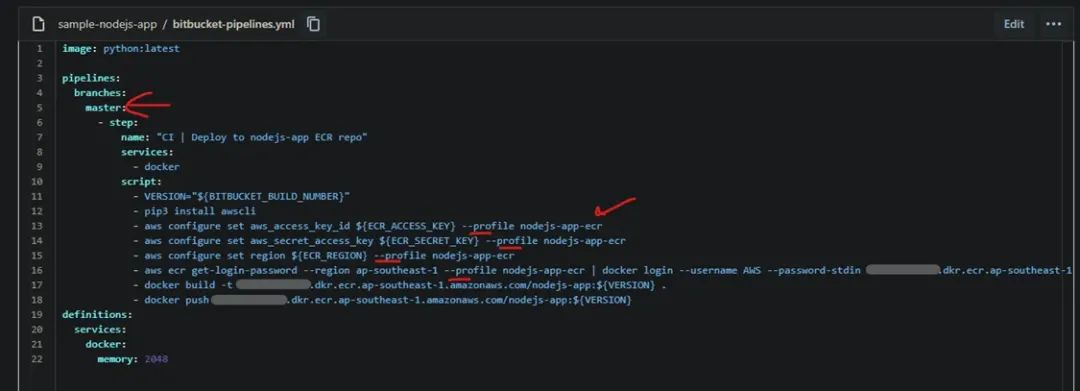
确保根据需要更新分支名称和 -profile 标签,否则 Pipeline 将无法访问 iam 访问密钥。
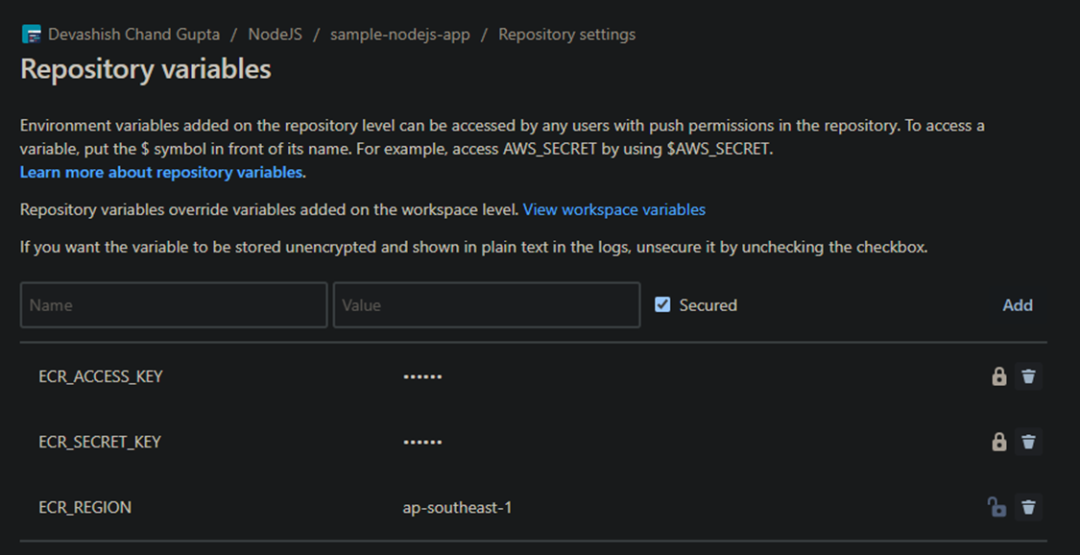
现在,我们需要创建一个具有 ECR 仓库访问权限的 AWS 访问密钥对,并作为以下变量添加到 Bitbucket Pipeline中。
- ECR_ACCESS_KEY
- ECR_SECRET_KEY
- ECR_REGION
此外,为了在 Bitbucket Pipeline中添加版本库变量,我们首先需要启用它。
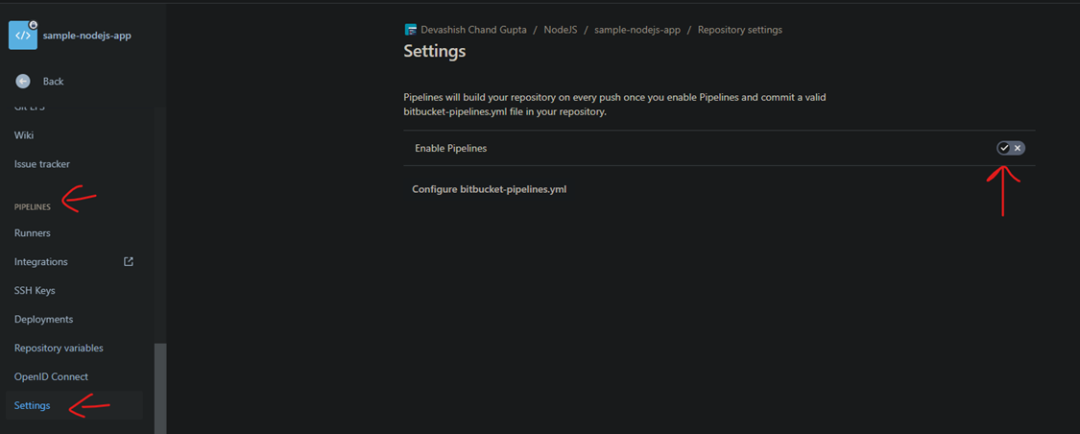
然后,对于 ECR Repo 访问,我们需要创建一个具有 AmazonEC2ContainerRegistryPowerUser 访问权限的 IAM 用户。
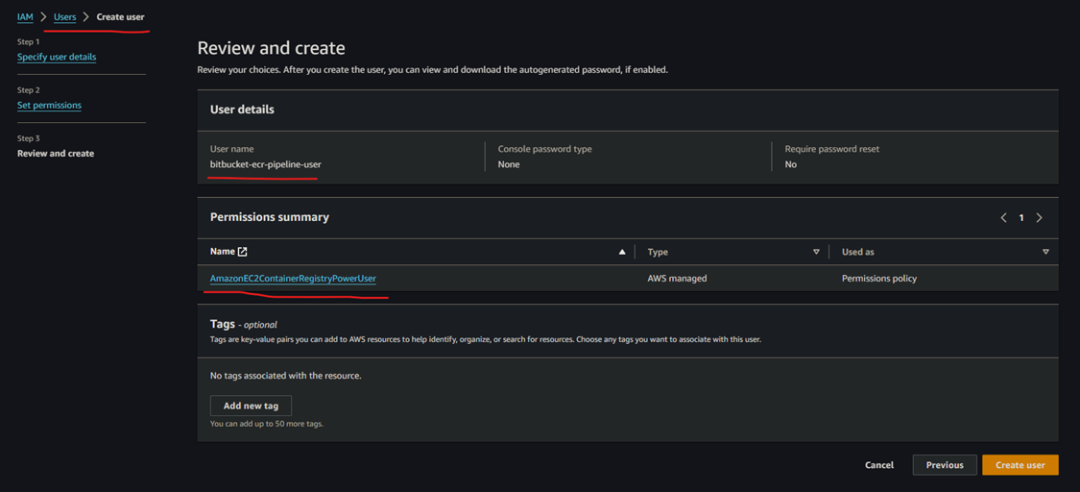
然后创建 AWS Access Key Pair,并将其添加到 Bitbucket Pipelines 版本库变量中,如下所示:
之后,您的 repo 中就应该有以下文件了:

确保写入正确的文件名,否则可能无法工作,流水线也不会执行。

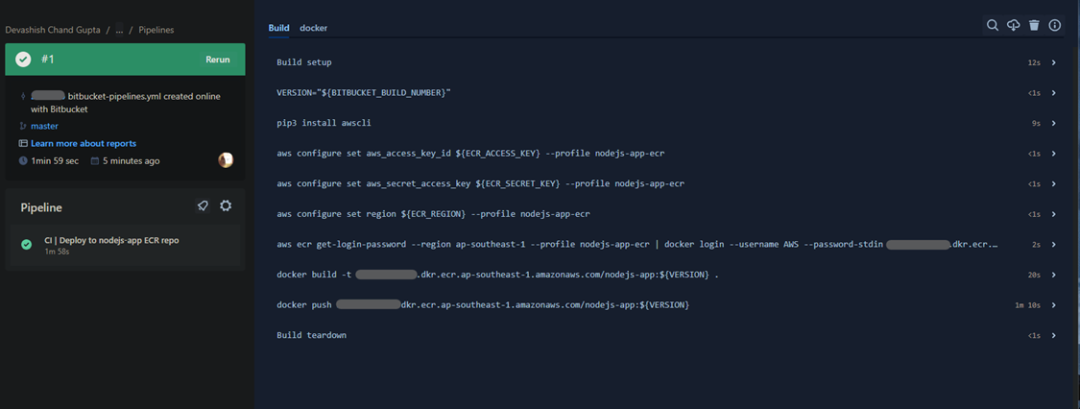
完成所有步骤后,流水线将自动运行。

几分钟后,流水线应该就会运行成功,并将容器镜像部署到 ECR Repo 上。
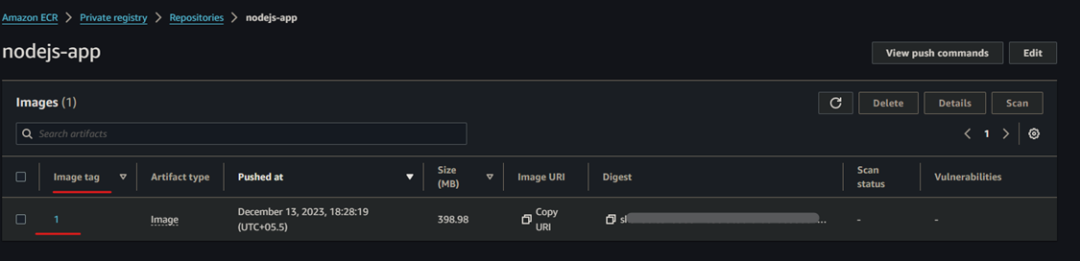
我们可以看到,标记为 1 的镜像已成功上传到 ECR,因为我们使用了 ${BITBUCKET_BUILD_NUMBER} 作为镜像的标记,所以可以更容易地通过相应的 ECR Repo 找到流水线编号。
既然部署到 ECR Repo 的 Bitbucket Pipeline 已经正常运行,也就说明可以准备进行下一步了。
在 Part 2 中,我们将会更详细地囊括后两个重要步骤,并指导您如何利用Terraform在 Bitbucket Pipeline 上实现端到端的 ArgoCD GitOps。