营销型网站单页wordpress联系方式代码
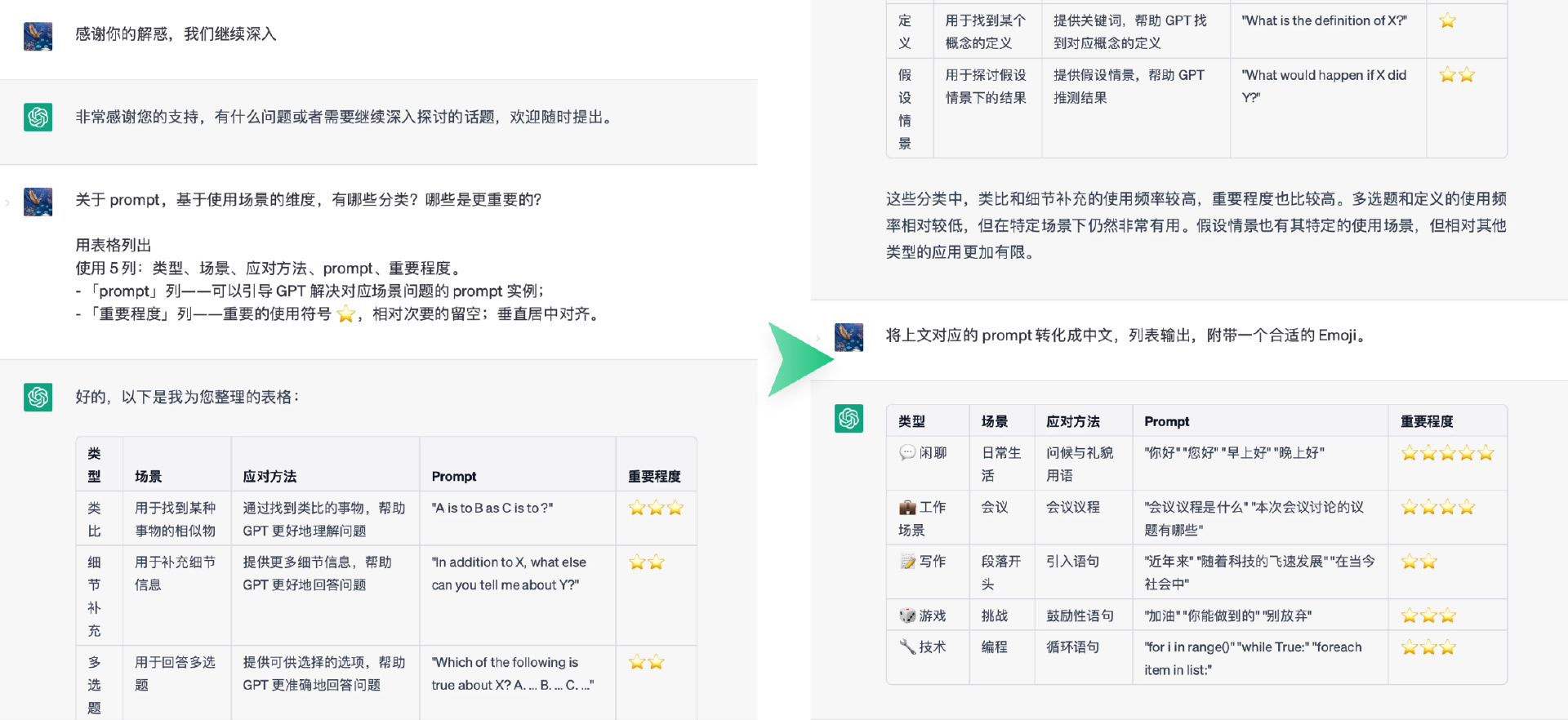
刚上手那会,我倾向于将 prompt 翻译为“指令”,但这并不精确。“指令”通常对应instructions,属于 prompt 中的纯指令部分,通常是一个动宾结构(做什么)。剩下的部分更多是描述(describe)。
• 角色设定:擅于使用 System 给GPT设定角色和任务,如“哲学大师”;
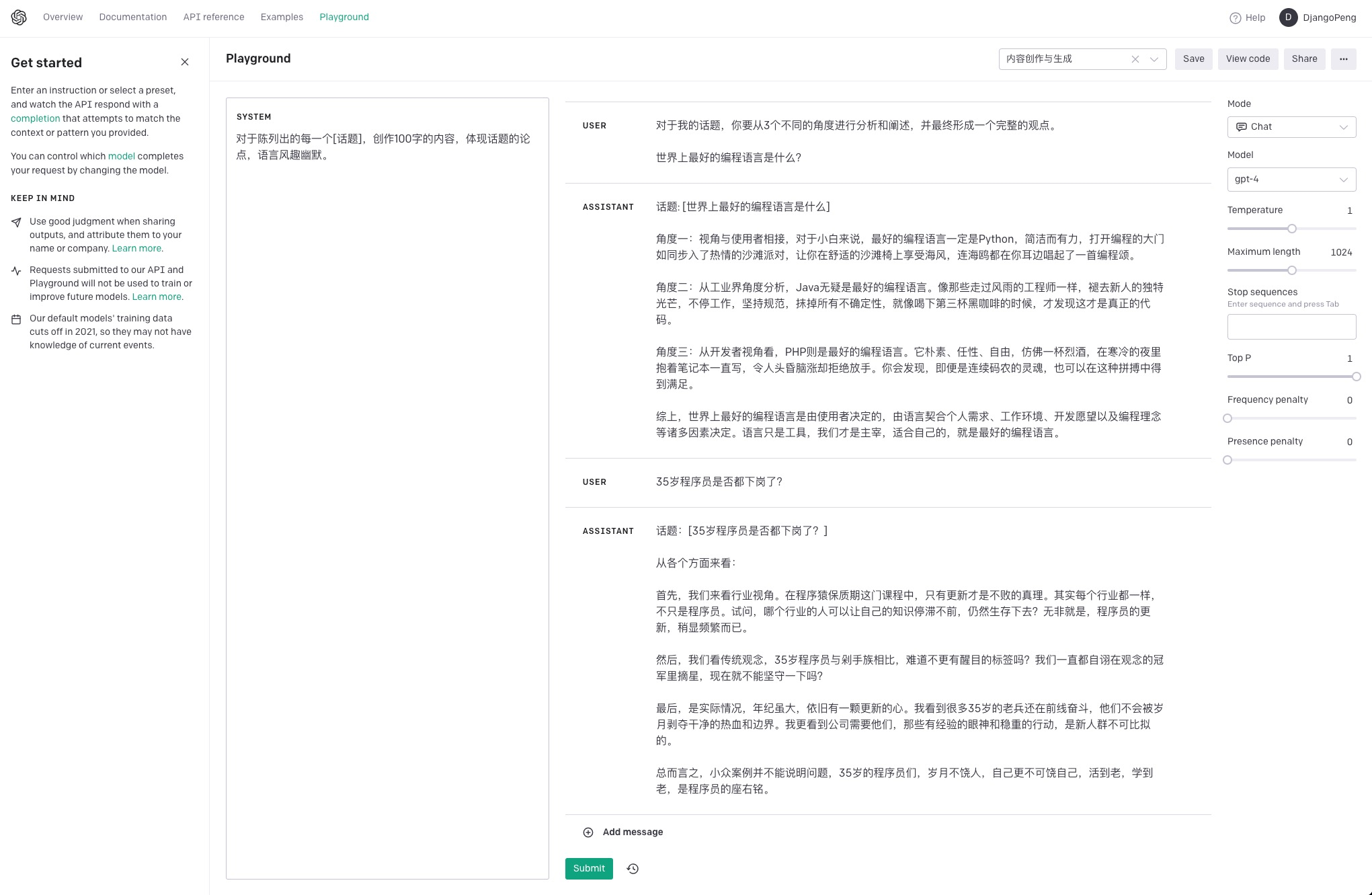
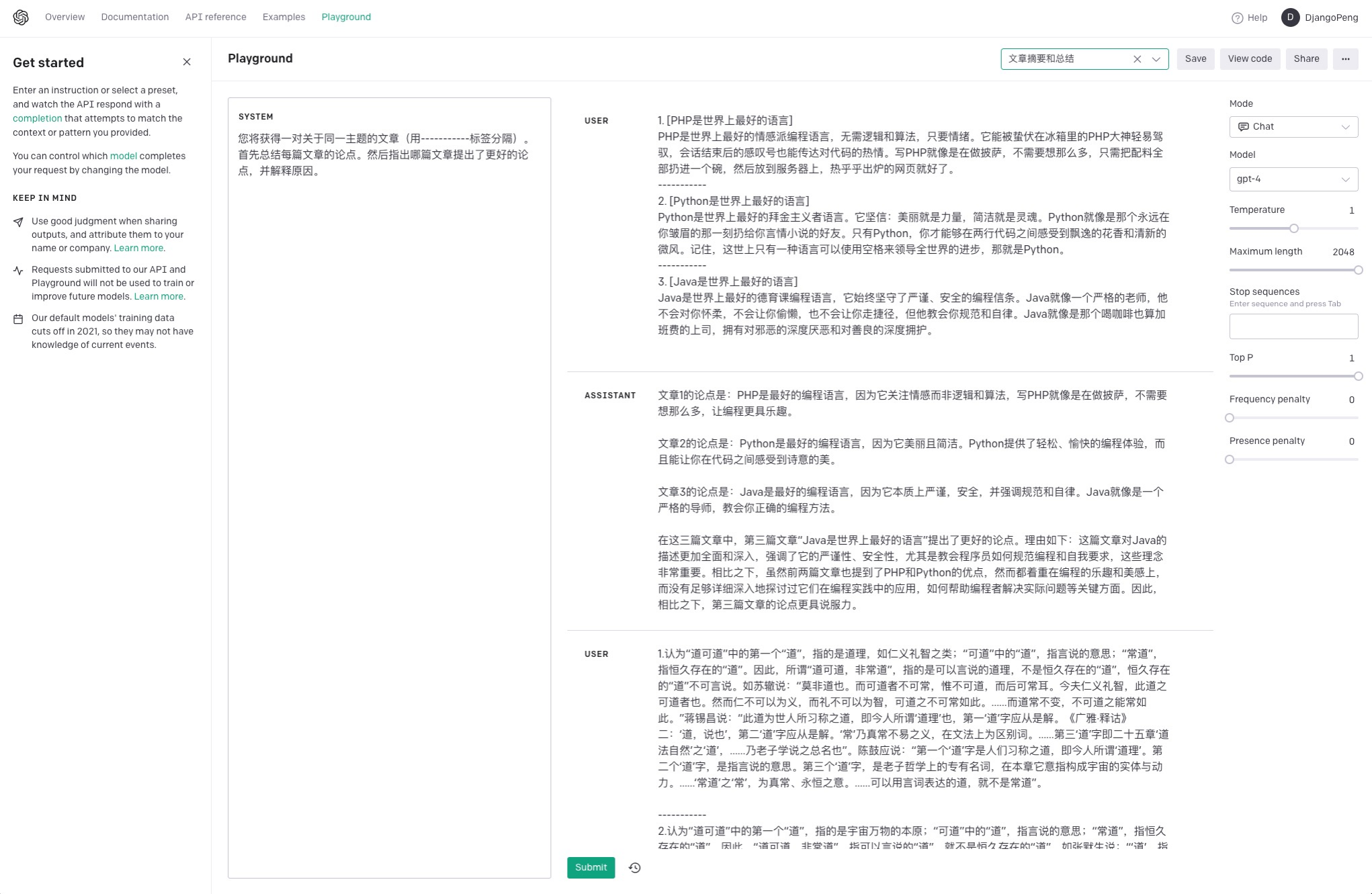
• 指令注入:在 System 中注入常驻任务指令,如“主题创作”;
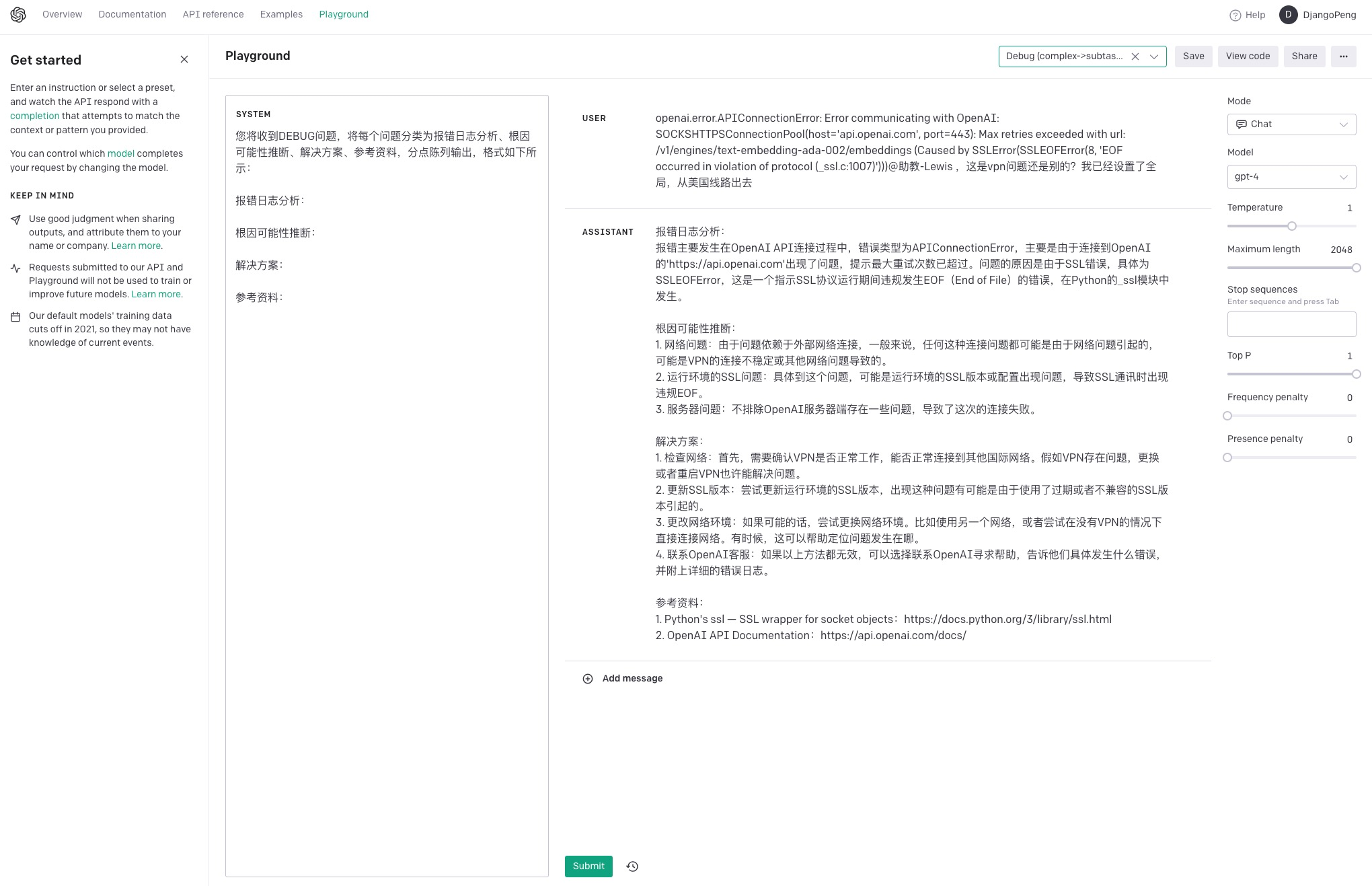
• 问题拆解:将复杂问题拆解成的子问题,分步骤执行,如:Debug 和多任务;
• 分层设计:创作长篇内容,分层提问,先概览再章节,最后补充细节,如:小说生成;
• 编程思维:将prompt当做编程语言,主动设计变量、模板和正文,如:评估模型输出质量;
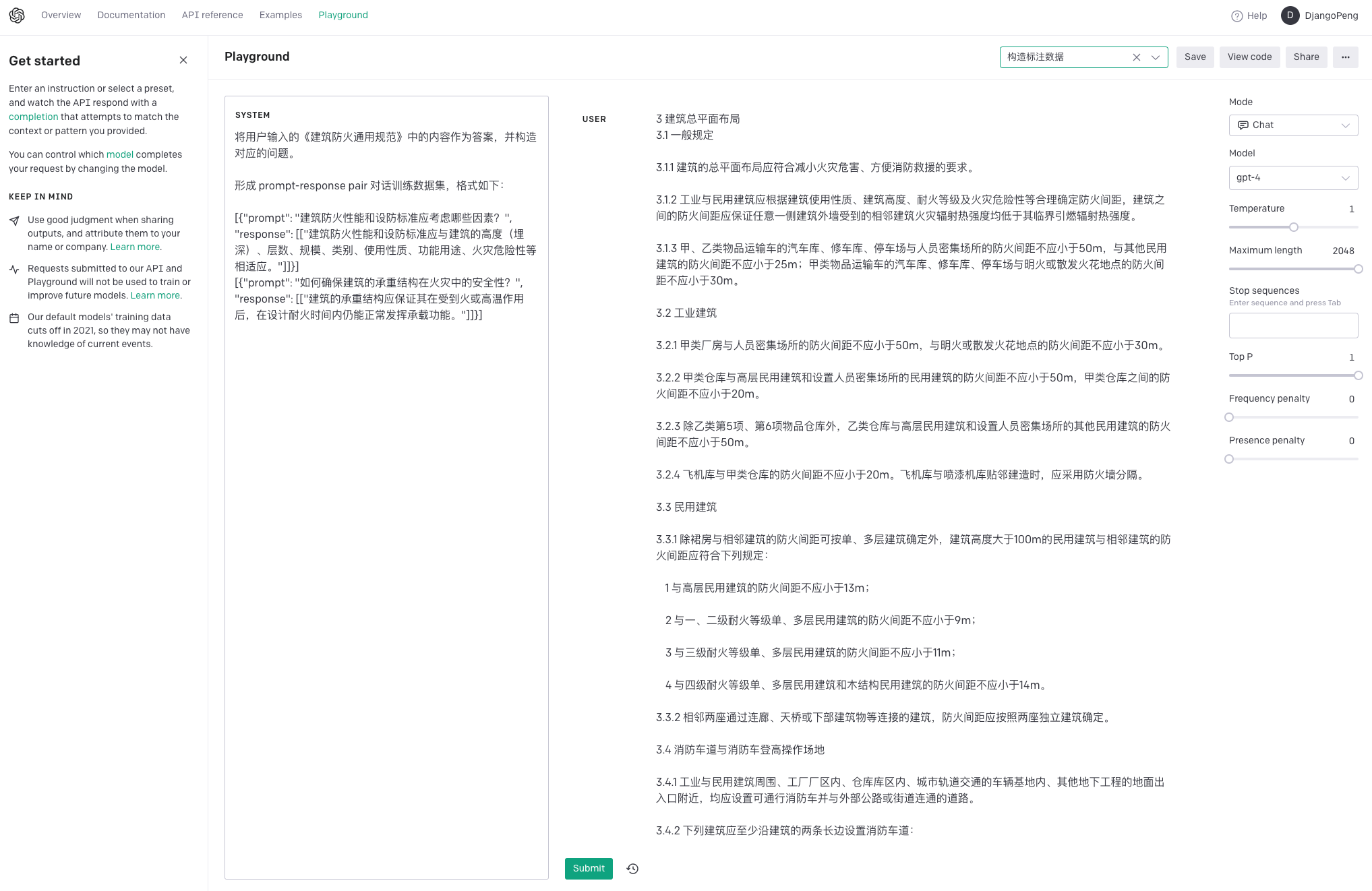
• Few-Shot:基于样例的prompt设计,规范推理路径和输出样式,如:构造训练数据;
Claude,ChatGPT 的优秀备胎,也支持中文:https://poe.com/。
ChatGPT : https://chat.openai.com/
明确具体的问题?


- 有意识地训练自己提出明确、具体的问题。
- 通过不同的 prompt 测试答案的一致性。
- prompt 工程可以有效提升 ChatGPT 回答的表现和效率。
- 注重自身的思维提升。
见面道辛苦
谁说 prompt 工程一定要是高深的语句?江湖流传的玄学 prompt 工程——在每个结果中加入“谢谢”,就能有效地提升输出质量。
角色设定

整个 prompt 中包含了两个人设。一个是引导我优化 prompt 的导师。导师人设要求ChatGPT 在结果中提供一个对输出方案量化的评估,如果评分较低,就说明一下问题点在哪里。这个问题点会促使我们进一步丰满 prompt 的信息。另一个人设是当我要求“运行”时,ChatGPT 提供具体问题的解决方案。
指令注入
问题拆解
预训练
科技进步日新月异,智能理解与日俱增,机器助力生产昼夜不停,犹如奔腾大河水滔滔不绝。
我是李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!