网站开发大概要多少钱dedecms做网站和thinkphp
一、IO概念
• I/O 即输入Input/ 输出Output的缩写,其实就是计算机调度把各个存储中(包括内存和外部存储)的数据写入写出的过程;
I : Input
O : Output
通过IO可以完成硬盘文件的读和写。
• java中用“流(stream)”来抽象表示这么一个写入写出的功能,封装成一个“类”,都放在http://java.io这个包里面。
二、来理解“流”是什么?
通过“流”的形式允许java程序使用相同的方式来访问不同的输入/输出源。stream是从起源(source)到接收的(sink)的有序数据。我们这里把输入/输出源对比成“水桶”,那么流就是“管道”,这个“管道”的粗细、单向性等属性也就是区分了不同“流”的特性。
三、IO流的分类
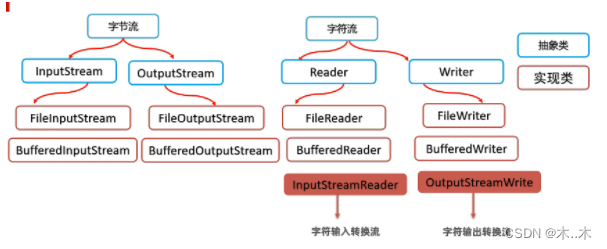
可以从两个不同的维度进行分类:
• 1、按照流的方向(输出输入都是站在程序所在内存的角度划分的)
• 输入流:只能从中读取数据【主要由InputStream和Reader作为基类】
• 输出流:只能向其写入数据【主要由outputStream和Writer作为基类】
在下图中,从磁盘读取数据到内存是输入流,从客户端读取数据到server是输入流;同样,把内存数据写到磁盘是输出流,把server数据写到client是输出流
按照 流的方向 进行分类:
以内存作为参照物:
往内存中去:叫做输入(Input)。或者叫做读(Read)。
从内存中出来:叫做输出(Output)。或者叫做写(Write)。
• 2、按照流的操作颗粒度划分
按照 读取数据方式 不同进行分类:
• 字节流:
按照 字节 的方式读取数据,一次读取1个字节byte,等同于一次读取8个二进制位。
这种流是万能的,什么类型的文件都可以读取。包括:文本文件,图片,声音文件,视频文件 等…以字节为单元,可操作任何数据【主要由InputStream和outPutStream作为基类】
eg.
假设文件file1.txt,采用字节流的话是这样读的:
a中国bc张三fe
第一次读:一个字节,正好读到’a’
第二次读:一个字节,正好读到’中’字符的一半。
第三次读:一个字节,正好读到’中’字符的另外一半。
• 字符流
按照 字符 的方式读取数据的,一次读取一个字符.
这种流是为了方便读取 普通文本文件 而存在的,这种流不能读取:图片、声音、视频等文件。只能读取 纯文本文件,连word文件都无法读取。以字符为单元,只能操作纯字符数据,比较方便【主要由Reader和Writer作为基类】
注意:
纯文本文件,不单单是.txt文件,还包括 .java、.ini、.py 。总之只要 能用记事本打开 的文件都是普通文本文件。
eg.
假设文件file1.txt,采用字符流的话是这样读的:
a中国bc张三fe
第一次读:'a’字符('a’字符在windows系统中占用1个字节。)
第二次读:'中’字符('中’字符在windows系统中占用2个字节。)
综上所述:流的分类:
输入流、输出流
字节流、字符流
四、IO流四大家族首领
字节流
java.io.InputStream 字节输入流
java.io.OutputStream 字节输出流
字符流
java.io.Reader 字符输入流
java.io.Writer 字符输出流
注意:
1.四大家族的首领都是抽象类。(abstract class)
2.所有的流都实现了:java.io.Closeable接口,都是可关闭的,都有 close() 方法。
流是一个管道,这个是内存和硬盘之间的通道,用完之后一定要关闭,不然会耗费(占用)很多资源。养成好习惯,用完流一定要关闭。
3.所有的 输出流 都实现了:java.io.Flushable接口,都是可刷新的,都有 flush() 方法。
养成一个好习惯,输出流在最终输出之后,一定要记得flush()刷新一下。这个刷新表示将通道/管道当中剩余未输出的数据强行输出完(清空管道!)刷新的作用就是清空管道。
ps:如果没有flush()可能会导致丢失数据。
4.在java中只要“类名”以 Stream 结尾的都是字节流。以“ Reader/Writer ”结尾的都是字符流。