移动电商网站搭建什么网站能盈利
题目
表: Customer
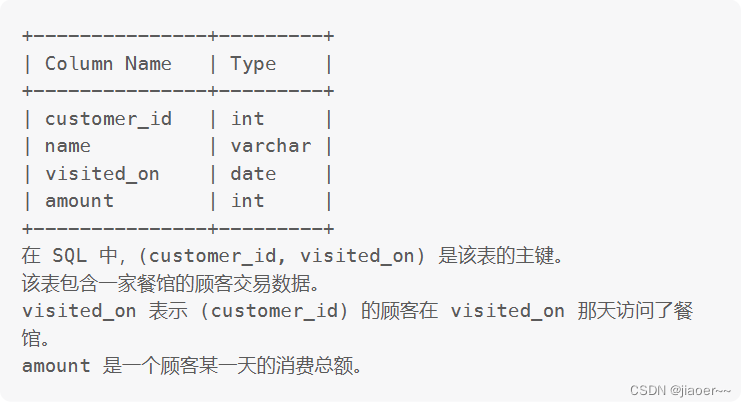
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
结果按 visited_on 升序排序。
返回结果格式的例子如下。
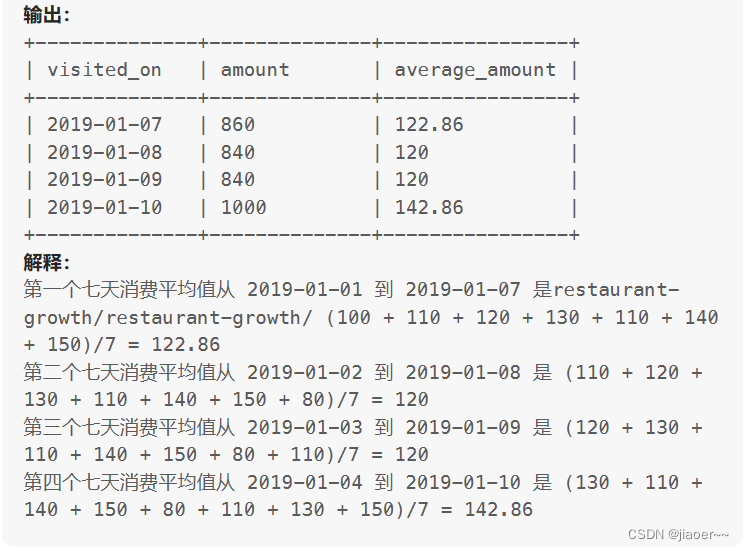
示例 1:

解题思路
1.题目要求我们分析一下可能的营业额变化增长,也就是计算一下以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。
2.首先我们从 Customer 表中选择 visited_on 列的值,并使用 GROUP BY 子句按 visited_on进行分组。同时,使用 SUM 函数计算每个 visited_on 值对应的 amount 列的总和,并将其命名为 amount。
3.然后我们使用SUM函数和窗口函数来计算visited_on列对应的amount列在过去6天内的累计总和。
4.最后,使用WHERE子句来筛选出visited_on值与最早的visited_on值之间的天数大于等于6的记录。通过使用datediff函数来计算visited_on与最早visited_on值之间的天数,并与6进行比较来实现的。
5.最终的结果将包含visited_on、sum_amount和average_amount三列的值,其中sum_amount是visited_on对应的amount列在过去6天内的累计总和,average_amount是每天的平均amount值。
代码实现
SELECT Distinct visited_on, sum_amount AS amount, ROUND(sum_amount/7, 2) AS average_amount
FROM(SELECT visited_on,SUM(amount) OVER (ORDER BY visited_on RANGE BETWEEN INTERVAL '6' DAYPRECEDING AND CURRENT ROW) AS sum_amountFROM(SELECT visited_on,SUM(amount) AS amountFROM CustomerGROUP BY visited_on)a
)b
WHERE datediff(visited_on,(SELECT MIN(visited_on) FROM Customer)) >= 6