佛山网站优化推广方案网站建设和使用现状
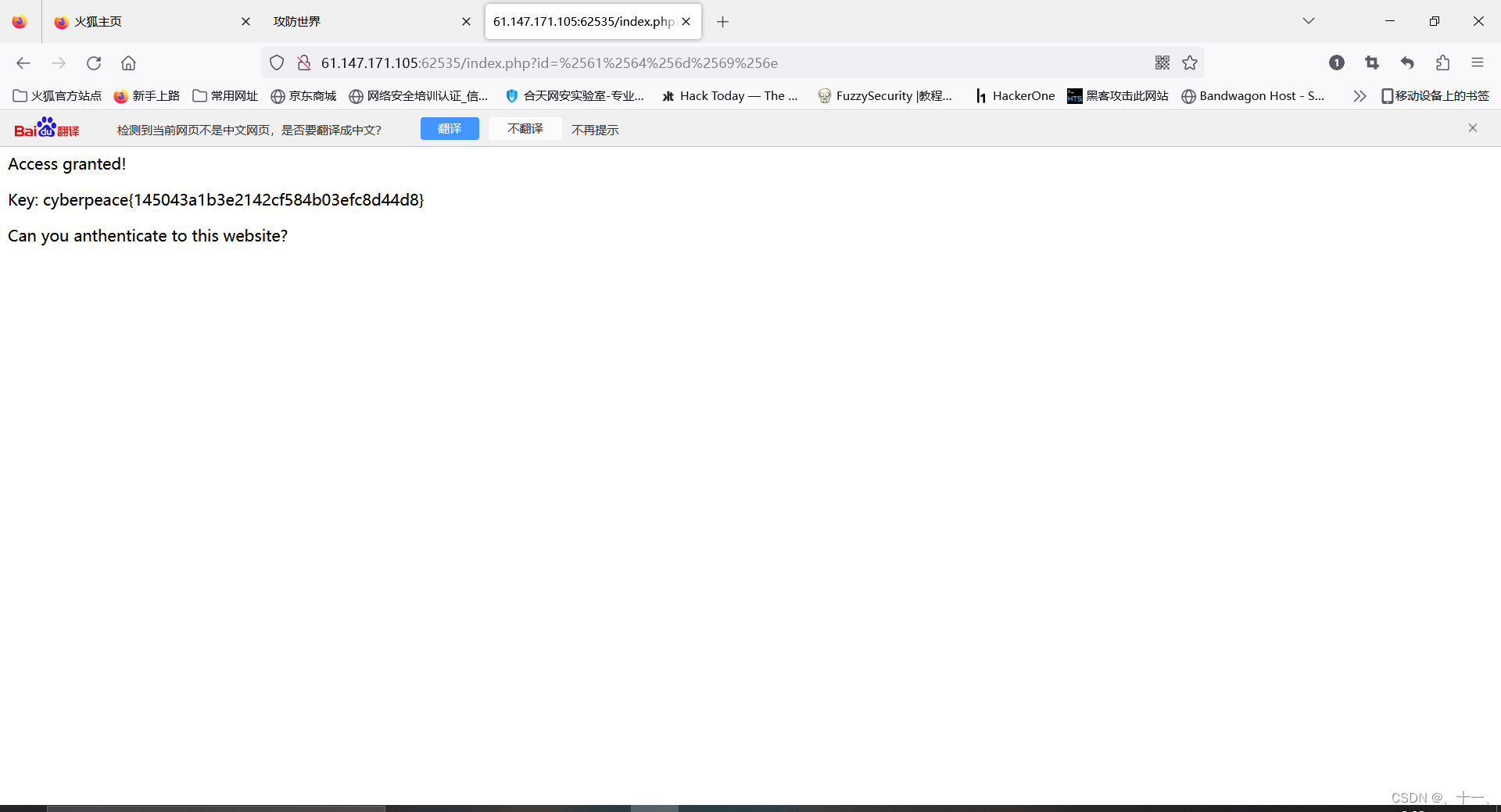
直接点击进入到http网页中,会得到这样一个界面
这里,我最开始使用了burp什么包也没有抓到,然后接着又用nikto进行探测,得到的只有两个目录,当时两个目录打开后,一个是fond界面,一个是这个网页的界面
因为不知道该怎么解,就看了看百度,答案还挺多的,我也就不说思路了,因为对php我也不晓得
在index.php后面加上s,也就是index.phps
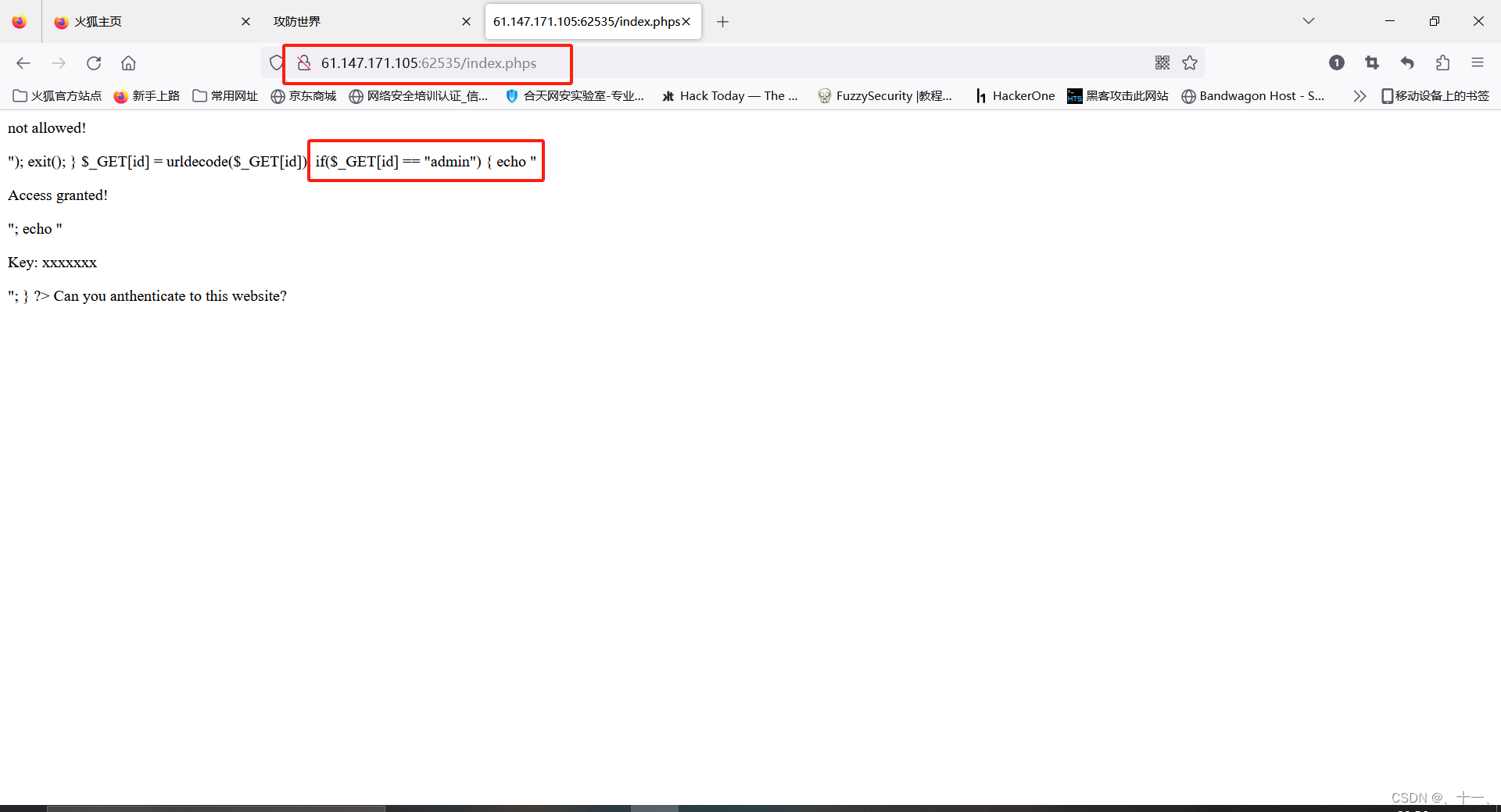
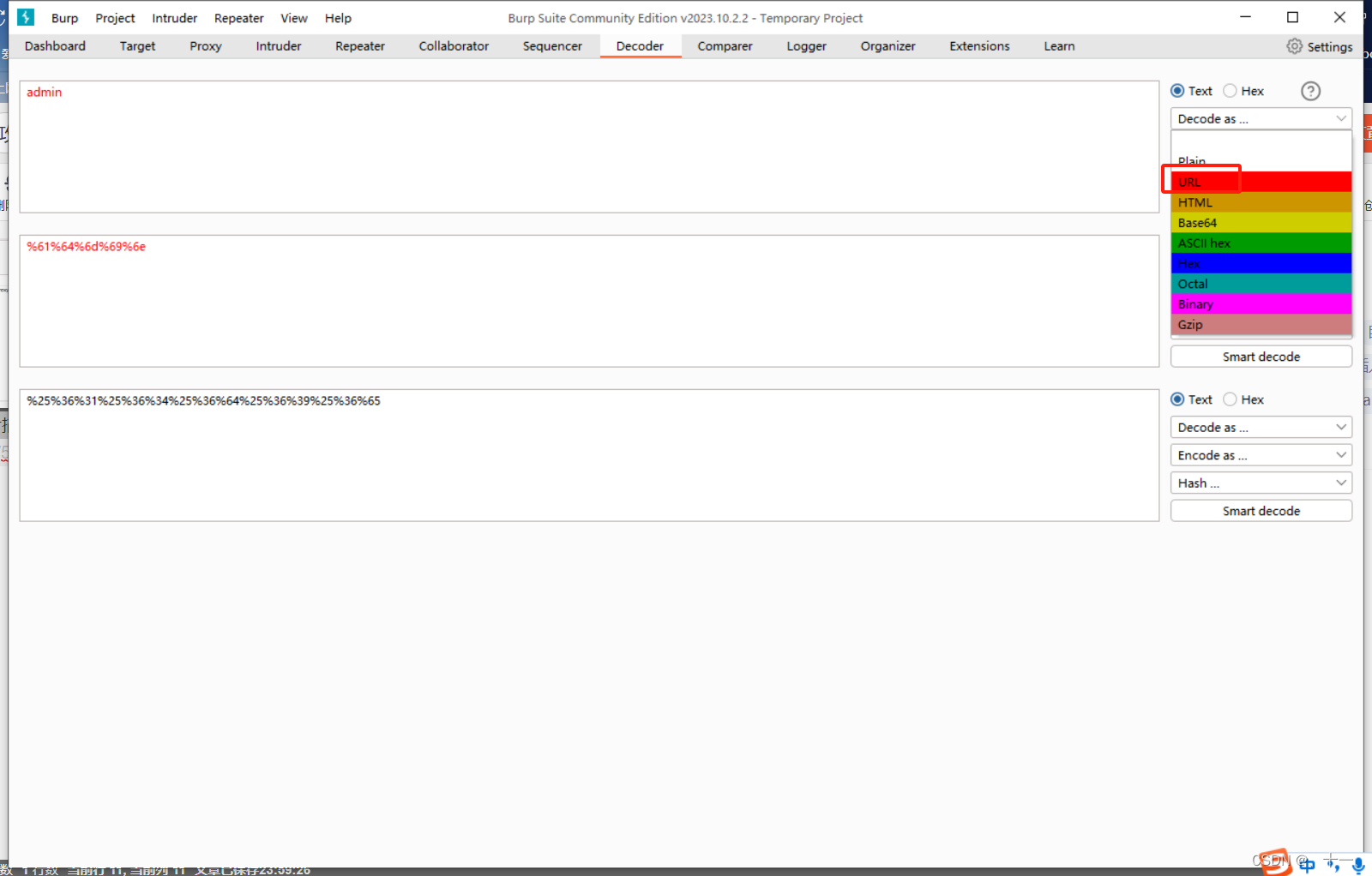
将admin进行解码,我这里使用的burp进行的解码,我的是2023.10.2.2版本的
看我方框位置,三个解码框,一定要都选择URL
最后,将这一串解码输入到浏览器中

最后得出flag值