
Scratch图形化等级考试(1~4级)全部真题・点这里
一、单选题(共10题,共30分)
第1题
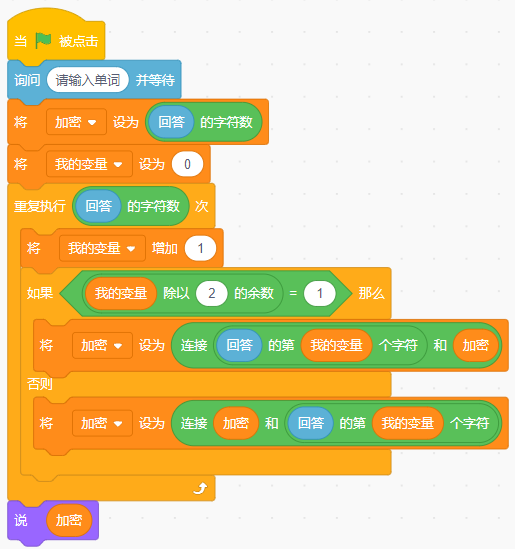
运行下列程序,输入单词“PLAY”,最后角色说?( )
A:LY4AP
B:AP4LY
C:YA4PL
D:PL4AY
答案:B
根据程序分析可知,首先获取单词字符数,然后奇数位的字母放在字符数左侧,偶数位在右侧,且越靠近中间数字的字母,在原单词中的位置编号就越小。所以输入PLAY后,会在字符数4的左右依次拼接字符,步骤为:①4,②P4,③P4L,④AP4L,⑤AP4LY
第2题
编写一个模拟注册验证的程序,图1和图2分别是小猫角色和手机角色的程序,下列说法正确的是?( )
![]()