建英文网站有用吗网站建设企业网站优化
Linux 查询当前进程所在的路径
top 命令查询相应的进程号pid
ps -ef |grep 进程名
lsof -I:端口号
netstat -anp|grep 端口号
cd /proc/进程id
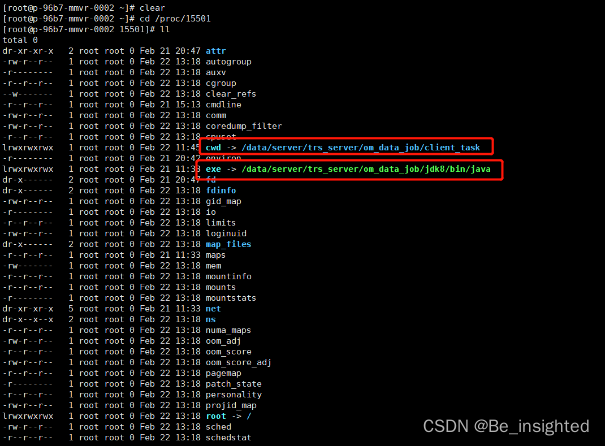
cwd 进程运行目录
exe 执行程序的绝对路径
cmdline 程序运行时输入的命令行命令
environ 记录了进程运行时的环境变量
fd 目录下是进程打开或使用的文件的符号连接
查看端口号对应进程
lsof -i :端口号
ubuntu 安装ssh
sudo apt-get install openssh-server
OpenGauss SpringBoot 配置
driver-class-name: org.postgresql.Driver
url:jdbc:postgresql://ip:port/db-name
共享WiFi
将带有无线网卡的电脑设置成热点(一般win10以上的系统)
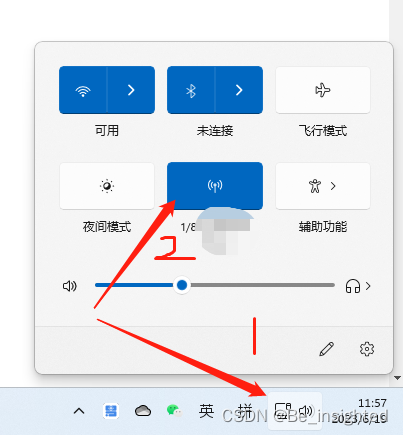
右键转到设置,可编辑WiFi信息。
MyBatis 使用map类型作为参数,复杂查询(导出数据)
interface声明
/*** @author Be.insighted*/@Mapperpublic interface InterviewerMapper{IPage<TInterviewer> query(IPage<?> page, @Param("param") Map<String, ?> param);}mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.*.mapper.InterviewerMapper"><!--面试官查询 管理端 --><select id="query" resultType="com.*.entity.TInterviewer" parameterType="map">select * from t_tablewhere del_flag=0 and valid_flag='0'<if test="param.keyword != null and param.keyword != ''">and (INSTR(interviewer_name,#{param.keyword}) or interviewer_code = #{param.keyword}) <!--姓名或者工号--></if><if test="param.companyCode != null and param.companyCode != ''">and company_code = #{param.companyCode} <!--企业编号--></if><if test="param.positionCode != null and param.positionCode != ''">and position_code = #{param.positionCode} <!--岗位编码--></if><if test="param.label != null and param.label != ''">and INSTR(label,#{param.label}) <!--标签--></if><if test="param.interviewerStatus != null and param.interviewerStatus != ''">and interviewer_status = #{param.interviewerStatus} <!--状态--></if><if test="param.interviewerStatus == null">and interviewer_status = '0' <!--状态--></if><if test="param.ids != null">AND id in<foreach collection="param.ids" index="index" open="(" close=")" item="item" separator=",">#{item}</foreach></if>order by create_time desc</select>
</mapper>
对应的controller
@GetMapping(value = "/interviewer/en/export")@ApiOperation(value = "面试官导出")public void export(HttpServletResponse response, InterviewerParams params) throws IOException, IllegalAccessException {LoginUser sysUser = (LoginUser) SecurityUtils.getSubject().getPrincipal();String companyCode = sysUser.getCompanyId();TInterviewer interviewer = interviewerConvert.toEntity(params);interviewer.setCompanyCode(companyCode);interviewer.setDelFlag(false);IPage<?> page = new Page();page.setCurrent(params.getPageNo());page.setSize(params.getPageSize());Map<String, Object> paramMap = new HashMap<>();String id = params.getIds();if (StrUtil.isNotBlank(id)) {EnInfo enInfo = enInfoService.getById(companyCode);String companyName = enInfo.getEnName();// 导出选中的数据paramMap.put("ids", id.split(","));List<TInterviewer> records = interviewerService.lambdaQuery().in(TInterviewer::getId, id.split(",")).list();List<InterviewerVO> temps = records.stream().map(item -> {InterviewerVO vo = new InterviewerVO();BeanUtils.copyProperties(item, vo);vo.setCompanyName(companyName);return vo;}).collect(Collectors.toList());List<String> positionCodes = records.stream().map(TInterviewer::getPositionCode).collect(Collectors.toList());List<String> collect = positionCodes.stream().distinct().collect(Collectors.toList());Map<String, String> positionCode2NameMap = new HashMap<>(collect.size());if (!CollectionUtils.isEmpty(collect)) {List<TPosition> positions = positionService.lambdaQuery().in(TPosition::getPositionCode, collect).list();positionCode2NameMap = positions.stream().collect(Collectors.toMap(TPosition::getPositionCode, TPosition::getPositionName));for (int i = 0; i < temps.size(); i++) {temps.get(i).setPositionName(positionCode2NameMap.get(temps.get(i).getPositionCode()));}}if (!CollectionUtils.isEmpty(temps)) {ExcelUtil<InterviewerVO> excelUtil = new ExcelUtil();excelUtil.setClose(false);excelUtil.buildExcel(response, temps);}return;} else {paramMap.put("keyword", params.getKeyword());paramMap.put("interviewerStatus", params.getInterviewerStatus());paramMap.put("positionCode", params.getPositionCode());paramMap.put("label", params.getLabel());paramMap.put("companyCode", companyCode);}IPage<TInterviewer> pageInfo = interviewerService.query4En(page, paramMap);List<TInterviewer> records = pageInfo.getRecords();EnInfo enInfo = enInfoService.getById(companyCode);String companyName = enInfo.getEnName();List<InterviewerVO> temps = records.stream().map(item -> {InterviewerVO vo = new InterviewerVO();BeanUtils.copyProperties(item, vo);vo.setCompanyName(companyName);return vo;}).collect(Collectors.toList());List<String> positionCodes = records.stream().map(TInterviewer::getPositionCode).collect(Collectors.toList());List<String> collect = positionCodes.stream().distinct().collect(Collectors.toList());Map<String, String> positionCode2NameMap = new HashMap<>(collect.size());if (!CollectionUtils.isEmpty(collect)) {List<TPosition> positions = positionService.lambdaQuery().in(TPosition::getPositionCode, collect).list();positionCode2NameMap = positions.stream().collect(Collectors.toMap(TPosition::getPositionCode, TPosition::getPositionName));for (int i = 0; i < temps.size(); i++) {temps.get(i).setPositionName(positionCode2NameMap.get(temps.get(i).getPositionCode()));}}if (!CollectionUtils.isEmpty(temps)) {ExcelUtil<InterviewerVO> excelUtil = new ExcelUtil();excelUtil.setClose(false);excelUtil.buildExcel(response, temps);}}
导出Excel工具类
package com.*.utils;import cn.com.*.annotation.Column;
import cn.com.*.annotation.Title;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.date.DateUtil;
import cn.hutool.core.io.IoUtil;
import cn.hutool.core.util.ReflectUtil;
import cn.hutool.core.util.URLUtil;
import lombok.Data;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.ss.usermodel.BorderStyle;
import org.apache.poi.ss.usermodel.FillPatternType;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.apache.poi.ss.usermodel.VerticalAlignment;
import org.apache.poi.ss.util.CellRangeAddress;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.OutputStream;
import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.net.URLEncoder;
import java.sql.Time;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;/*** @author Be.insighted* @title: ExcelUtil* @description: 默认每个sheet最多50000条数据 超过另起一个sheet* @date @date 2023-11-14 15:42*/
@Data
public class ExcelUtil<T> {/*** 设置每行的宽度 每个值的index 对应第几列 如{1500,1000} 表示第一个1500长度 第二个1000长度 以此类推*/private int[] size;/*** 查询条件文本描述*/private String queryCriteria;/*** 是否关闭流 默认关闭*/private boolean close = true;public ExcelUtil() {this.queryCriteria = null;}public ExcelUtil(String queryCriteria) {this.queryCriteria = queryCriteria;}public void buildExcel(HttpServletResponse response, List<T> list, String filename) throws IOException, IllegalAccessException {String name = Objects.isNull(filename) ? "" : filename;OutputStream output = response.getOutputStream();response.reset();response.setCharacterEncoding("UTF-8");name = URLEncoder.encode(name + DateUtil.format(new Date(), "yyyyMMddHHmmss") + ".xls", "UTF-8");response.setHeader("Cache-Control", "no-cache, no-store, must-revalidate");response.setHeader("Content-Disposition", "attachment; filename=" + URLUtil.encode(name, "UTF-8"));response.setHeader("Pragma", "no-cache");response.setHeader("Expires", "0");response.setContentType("application/msexcel;charset=utf-8");List<String> parameter = new ArrayList<>();List<Field> fieldArrayList = new ArrayList<>();if (CollUtil.isNotEmpty(list)) {Class<?> clazz = list.get(0).getClass();Field[] fields = clazz.getDeclaredFields();for (Field field : fields) {if (field.getAnnotation(Column.class) != null) {if (!StringUtils.isEmpty(field.getAnnotation(Column.class).name())) {parameter.add(field.getAnnotation(Column.class).name());} else {parameter.add(field.getName());}fieldArrayList.add(field);}}Title title = clazz.getDeclaredAnnotation(Title.class);if (title != null) {name = title.title();}} else {return;}HSSFWorkbook hssfWorkbook = new HSSFWorkbook();try {final int sheetNum = (int) Math.ceil((float) list.size() / 50000);HSSFCellStyle style = hssfWorkbook.createCellStyle();style.setFillForegroundColor((short) 22);style.setFillPattern(FillPatternType.SOLID_FOREGROUND);style.setBorderBottom(BorderStyle.THIN);style.setBorderLeft(BorderStyle.THIN);style.setBorderRight(BorderStyle.THIN);style.setBorderTop(BorderStyle.THIN);style.setAlignment(HorizontalAlignment.CENTER);style.setVerticalAlignment(VerticalAlignment.CENTER);//2022年4月8日17:16:09 增加,解决:导出数据之后数据并未换行,只有双击之后才展现换行效果style.setWrapText(true);HSSFFont font = hssfWorkbook.createFont();font.setFontHeightInPoints((short) 12);style.setFont(font);HSSFCellStyle style2 = hssfWorkbook.createCellStyle();style2.setAlignment(HorizontalAlignment.CENTER);//垂直居中style2.setVerticalAlignment(VerticalAlignment.CENTER);//2022年4月8日17:16:09 增加,解决:导出数据之后数据并未换行,只有双击之后才展现换行效果style2.setWrapText(true);for (int n = 1; n <= sheetNum; n++) {final HSSFSheet sheet = hssfWorkbook.createSheet("sheet" + "-" + n);List<T> toOut = null;if (sheetNum > 1) {if (n == sheetNum) {toOut = getSubList(list, 0, list.size() - 1);} else {toOut = getSubList(list, 0, 50000);}} else {toOut = list;}if (CollUtil.isNotEmpty(toOut)) {Class<?> clazz = toOut.get(0).getClass();HSSFRow row1 = sheet.createRow(0);HSSFCell cellTitle = row1.createCell(0);cellTitle.setCellStyle(style);Title title = clazz.getDeclaredAnnotation(Title.class);if (title != null) {if (StringUtils.isNotBlank(queryCriteria)) {cellTitle.setCellValue(title.title() + " " + queryCriteria);} else {cellTitle.setCellValue(title.title());}sheet.addMergedRegion(new CellRangeAddress(0, 0, 0, parameter.size() - 1));}if (getSize() != null && getSize().length > 0) {for (int i = 0; i < getSize().length; i++) {sheet.setColumnWidth(i, getSize()[i]);}} else {int length = parameter.size();this.size = new int[length];for (int i = 0; i < length; i++) {this.size[i] = 10000;sheet.setColumnWidth(i, getSize()[i]);}}HSSFRow row2 = sheet.createRow(1);for (int i = 0; i < parameter.size(); i++) {HSSFCell cell = row2.createCell(i);cell.setCellStyle(style);cell.setCellValue(parameter.get(i));}for (int i = 0; i < toOut.size(); i++) {HSSFRow row = sheet.createRow(i + 2);for (int j = 0; j < fieldArrayList.size(); j++) {Field field = fieldArrayList.get(j);Object value = ReflectUtil.getFieldValue(toOut.get(i), field);HSSFCell cell = row.createCell(j);cell.setCellStyle(style2);Column column = field.getDeclaredAnnotation(Column.class);if (value != null && !"null".equals(value)) {String rule = column.timeFormat();boolean rate = column.rate();boolean condition = StringUtils.isNotBlank(rule) && (field.getType().equals(Date.class) ||field.getType().equals(java.sql.Date.class) ||field.getType().equals(Time.class) ||field.getType().equals(Timestamp.class));if (condition) {SimpleDateFormat simpleDateFormat = new SimpleDateFormat(rule);cell.setCellValue(simpleDateFormat.format(value));} else if (rate && field.getType().equals(BigDecimal.class)) {BigDecimal valueReal = (BigDecimal) value;cell.setCellValue(valueReal.multiply(new BigDecimal("100")) + "%");} else {cell.setCellValue(value.toString());}} else {if (field.getType().equals(Integer.class) || field.getType().equals(Long.class) ||field.getType().equals(Double.class) || field.getType().equals(Float.class) ||field.getType().equals(BigDecimal.class)) {cell.setCellValue(0);} else {cell.setCellValue("");}}}}}}hssfWorkbook.write(output);} finally {IoUtil.close(hssfWorkbook);if (close) {IoUtil.close(output);}}}/*** 截取list 含左不含右** @param list* @param fromIndex* @param toIndex* @param <T>* @return*/private static <T> List<T> getSubList(List<T> list, int fromIndex, int toIndex) {List<T> listClone = list;List<T> sub = listClone.subList(fromIndex, toIndex);return new ArrayList<>(sub);}}column、title注解定义
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Inherited
@Documented
public @interface Column {String name() default "";String timeFormat() default "";boolean rate() default false;
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Inherited
@Documented
public @interface Title {String title() default "";}
导出的对象定义
@Data
@Accessors(chain = true)
@ApiModel(value = "面试官表示")
@Title(title = "面试官信息")
public class InterviewerVO implements Serializable {private String id;/**
* 企业编码
*/@Excel(name = "企业编码")@Column(name = "企业编码")@Dict( dictTable="sys_depart",dicCode="id",dicText="depart_name")private String companyCode;/**
* 企业名称
*/@Excel(name = "企业名称")@Column(name = "企业名称")private String companyName;/**
* 面试官名称
*/@Excel(name = "面试官名称")@Column(name = "面试官名称")private String interviewerName;/**
* 面试官编号,取黄河人才网的id
*/private String interviewerCode;/**
* 部门
*/private String department;/**
* 岗位名称
*/@Excel(name = "岗位名称")@Column(name = "岗位名称")private String positionName;/**
* 岗位code
*/private String positionCode;/**
* 标签
*/@Excel(name = "标签")@Column(name = "标签")private String label;/**
* 联系方式
*/@Excel(name = "联系方式")@Column(name = "联系方式")private String contactInfo;/**
* 面试官类别
*/@Dict(dicCode = "interviewer_type")private String interviewerType;/**
* 面试官状态
*/@Dict(dicCode = "interviewer_status")private String interviewerStatus;/**
* 面试官有效标识
*/private String validFlag;/**
* 创建人姓名
*/@Excel(name = "创建人")@Column(name = "创建人")private String createName;/**
* 创建人工号
*/private String createCode;/**
* 创建时间
*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")private Date createTime;/**
* 更新人
*/private String updateName;/**
* 更新时间
*/private Date updateTime;
}