做摄影的网站知乎高端网站建设设计公司哪家好
1、 背景介绍及难点分析
作为世界领先的物流行业整合商、端到端的全程供应链解决方案和一站式物流服务提供商,中国外运非常重视信息化建设,先后投资建设了 300多个信息系统,为中国外运的内部管理和业务运作提供 IT 支持和保障。
由于缺乏统一标准和统一管理,各类常用的主数据标准不一、代码各异,致使各系统之间的数据无法进行有效关联和共享,形成“信息孤岛”和“数据烟囱”,给公司数据集中和数据应用带来很大的困难,比较突出的问题主要集中在以下几个方面:
(1) 由于缺少统一外部单位主数据,致使客户和供应商在不同系统中标识不一,难以进行唯一性识别。同时由于缺乏对主数据真实性和有效性的验证,无法保证客户、供应商、人力资源及组织机构等基本信息准确性和有效性, 为公司运营管理和风险控制带来一定的影响。
(2) 员工主数据尚未进行统一管理和共享,员工身份数据不统一,不但无法对与员工关联的邮箱、登录账号等关键资源进行有效的管理,造成资源浪费和安全隐患,同时还给公司平台化、协同化所需要的统一用户目录管理、统一认证和单点登录集成等带来极大的阻碍。
(3) 内部组织机构没有统一的标准,人事、财务、业务口径各异,公司的内部管理无法实现统一口径。
(4) 业务基础主数据(如港口、内陆地点、机场、车站、航空公司、包装种类等)分散管理,数据标准不统一,管理水平参差不齐,数据质量不高,难以满足业务数字化、平台化协同的管理要求。
(5) 业务资源、物料、设备等没有统一的分类代码和主数据定义,公司在实施业务资源共享(云资源)、集中采购管理、物资管理等方面缺少标准数据支撑, 难以有效发挥作用。
2、 建设过程
如何解决这些问题,中国外运从 2013 年开始思考并不断探索。先从数据标准化开始,制定和完善急需数据代码标准和数据规范,以规范各类代码和基础数据。经过调研分析,并借鉴其他单位的经验,中国外运决定采用统一标准、统一平台加强主数据管理,实现数据标准落地,并于 2016 年启动主数据平台建设咨询和实施项目,搭建中国外运统一主数据管理工具。
中国外运于 2016 年 9 月开始启动主数据项目的建设工作,项目主要分为咨询和实施两个阶段,主数据咨询项目围绕主数据标准体系建立、 主数据管理工具规划、 主数据管理体系搭建进行了详细的调研规划,为实施阶段主数据管理工具的落地奠定了坚实的基础。
3、 建设成果
(1)设计了中国外运统一的主数据标准体系。
从特征一致性、识别唯一性、长期有效性、交易稳定性四个因素方面对数据进行识别,梳理规划数据管理范围及业务边界,确定主数据范围,最终设计完成了中国外运统一的主数据标准体系。

主数据标准体系
(2) 建立了统一的主数据管理工具。
基于主数据功能点、功能机制以及数据交换与集成特点,建立统一的主数据管理工具,实现了主数据的全生命周期管理,满足了各应用系统数据集成和数据共享的需求。
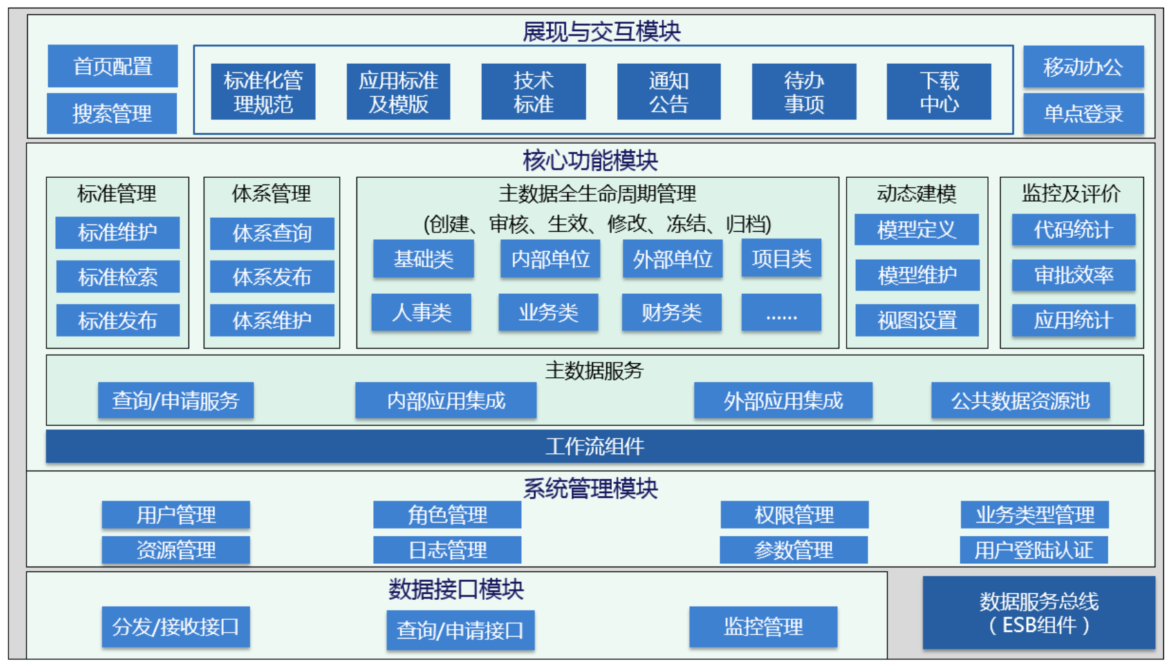
主数据管理工具功能架构
(3)实施了 6 大类主数据,完成了大量数据清洗和加载。
基于主数据标准体系,一期项目选取了通用基础类、内部单位类、外部单位类、员工类、财务类、业务类主数据进行实施,详细制定了每类主数据标准及维护细则并完成各类数据的清洗, 形成了统一的主数据代码库。
(4)完成内外部应用系统的集成,提供一站式数据服务。
主数据平台通过企业服务总线(ESB)对外统一分发不同类型的主数据,各应用系统通过 ESB 订阅各自需要的主数据类型。
(5)改造了 HR 数据驱动的邮件管理流程,实现了员工数据的统一规范管理。
通过主数据平台与 IT 服务台、邮件系统集成,打通 HR 与邮件系统(AD 域)的数据, 为用户关键数据建立可靠关联,解决了难以对员工电子邮件实施有效管理的老大难问题, 为平台化协同工作打下基础。
(6)引用标准的企业工商数据,统一规范客户、供应商数据。
主数据平台上线以后,引用权威的工商数据作为基准数据,确保客户供应商数据的准确、真实、有效和完整。针对境外公司,通过邓白氏(D.U.N.S)、公司官网和线下核实等各种渠道严格核实、验证数据的真实性。
(7)搭建“五位一体”的主数据运维服务保障体系。
建立了统一的主数据管理和运营机制,针对不同主数据类型配备了信息员和审核员,按照数据维护和审核流程,对主数据全生命周期进行严格管理,确保主数据的质量和时效性,为公司各方面的应用提供准确可靠的主数据。
4、 总结和展望
主数据管理工具是中国外运进行数据治理的重要抓手,是公司实现数字化管理、平台化协同和全程可视化服务的重要基础,为公司提供物流数据服务,打通物流链前后各环节提供基础数据支撑。主数据管理是一项长期而艰巨的基础性工作,一期项目的实施只是跨出了一小步,未来中国外运将构建业务统计指标体系、 管理指标体系、梳理资产分类、代码和关键属性值等,后续还有更长的路要走。在认真总结经验的基础上,中国外运更加坚定信心, 继续努力推进数据治理建设和应用推广工作,为公司的平台化、 数字化战略实施做出应有的努力。