360免费建站官网入口17做网店这个网站好不好
文章目录
- Web3公链之Cosmos生态的项目:模块化区块链Celestia
- 什么是Celestia
- Celestia网络架构
- 数据可用性问题有哪些可用的解决方案?
- 发展历史
- 运行节点
- 参考
Web3公链之Cosmos生态的项目:模块化区块链Celestia
什么是Celestia
官网:https://celestia.org/
一直以来,区块链都是执行状态机复制的分布式网络,分成了数据、共识、执行这三层。在单体区块链中,数据、共识、执行这三层工作全都会由一个网络来完成,因此若复杂度越高、系统保持同步性的成本和复杂度也就越高。
以太坊Rollup 将执行层分离出去,处理复杂交易,解决了一部分问题,但Rollup 必须监控 L1 并且执行调用交易以便计算,再以不同方式将返回 L1。数据可用性还是依赖于以太坊的共识层与执行层,目前以太坊执行层使用成本仍然很高,开发者可部署的范围还是很有限。
以太坊 Rollup 二层网络是一个执行层,而这些项目的数据可用性、共识以及结算层都是以太坊,这样的Rollup 理论上将拥有接近以太坊主网的安全性。
Celestia 是一个模块化协议,它只处理数据可用性(DA),其他执行和结算工作可以锁定DA 层,开发人员可以直接选择要使用的执行环境在Celestia上构建 DApp。
Celestia 采用模块化架构,将区块链解构为数据、共识、执行,以精简化、模块化的共识层,来赋能预算不多的开发者,让他们轻松的部署自己的区块链。
Celestia 为模块化扩展提供了不同的解决方案,其架构目前有三种类型:
① 主权 Rollup:数据可用性层和共识层为 Celestia,结算层和执行层是自己的主权链;
② 结算 Rollup(代表项目 Cevmos):数据可用性层和共识层为Celestia,结算层为 Cevmos,应用链为执行层;
③ Celestium: 数据可用性层为 Celestia,共识层和结算层为以太坊,应用链为执行层。
从赛道来看,Celestia应该被并入公链赛道,但是Celestia与以前的单片式公链又有较大区别,因此可以将其单独细分为专注于共识层和数据可用性层的模块化公链,该细分赛道目前仍然处于非常早期的阶段。
Celestia网络架构
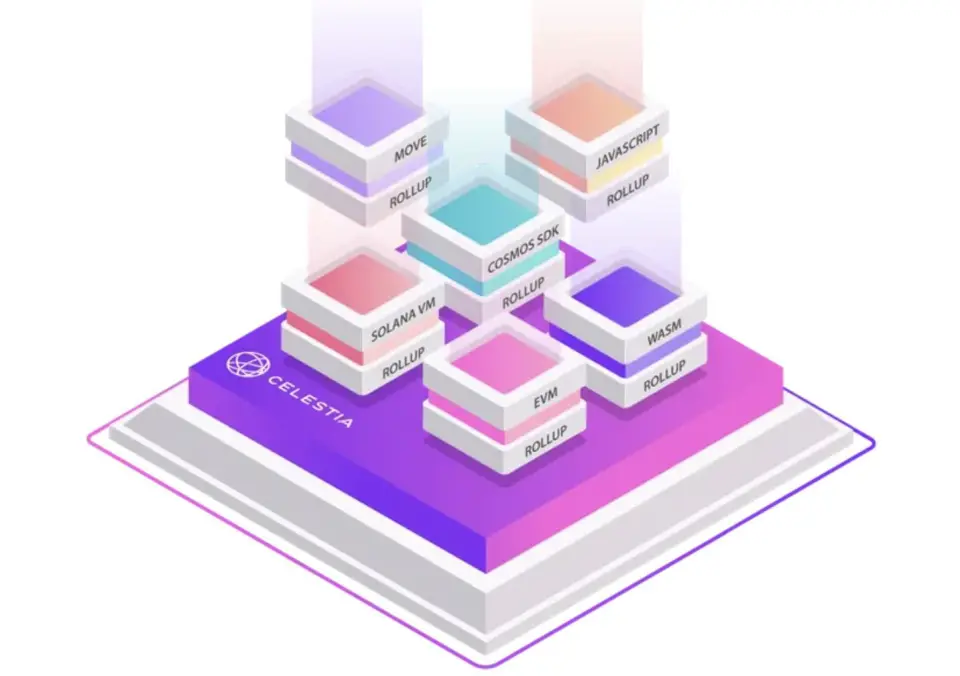
作为一个数据可用性层。Celestia采用PoS的共识机制,并且使用了Cosmos SDK来进行开发,但是其对Tendermint的共识算法进行了一些修改。修改后的Tendermint共识算法-Celestia Core包含了Celestia解决数据可用性问题的两个重点:数据可用性采样(Data Availability Sampling (DAS))与命名空间默克尔树(Namespaced Merkle Trees (NMTs))
数据可用性问题有哪些可用的解决方案?
Celestia专题系列1 : 什么是数据可用性(DA:Data Availability)
参考URL: https://zhuanlan.zhihu.com/p/493099971?utm_id=0
-
下载所有数据
解决数据可用性问题的最简单的方法是要求每个人(包括轻客户端)下载所有数据。显然,这不能很好地扩展, 这也是大多数区块链(例如比特币和以太坊)目前所做的。 -
数据可用性证明(Data Availability Proofs)
数据可用性证明(Data Availability Proofs)是一项新技术,它允许客户通过仅下载该区块的一小部分来以非常高的概率检查该块的所有数据是否已发布。
客户端可以通过仅访问一小部分数据来检查整个区块数据是否已发布。
数据可用性证明的完整细节有点复杂,并且依赖于其他假设,例如要求网络中的轻客户端数量最少,以便有足够的轻客户端发出样本请求,以便它们可以共同恢复整个块。如果您想了解更多信息,可以查看原始数据可用性证明论文。
发展历史
2019.05 LazyLedger白皮书发布
2021.03.04 LazyLedger Labs完成150万美元种子轮融资,计划年底启动测试网
2021.06.15 LazyLedger更名Celestia
2022.05.25 Celestia启动其首个测试网Mamaki
2022.10.20 Celestia完成5500万美元融资,Polychain Capital等领投
2023.03.15 Celestia测试网Blockspace Race上线,区块浏览器已启动
2023.05.12 Celestia:Quantum Gravity Bridge初期版本已上线Blockspace Race测试网
运行节点
官方文档:https://docs.celestia.org/nodes/light-node/
# celestia light init --p2p.network mocha2023-10-21T22:45:38.120+0800 INFO node nodebuilder/init.go:31 Initializing Light Node Store over '/root/.celestia-light-mocha-4'
2023-10-21T22:45:38.152+0800 INFO node nodebuilder/init.go:63 Saved config{ "path": "/root/.celestia-light-mocha-4/config.toml"}
2023-10-21T22:45:38.152+0800 INFO node nodebuilder/init.go:65 Accessing key ring...
2023-10-21T22:45:38.161+0800 WARN node nodebuilder/init.go:194 Detected plai ntext keyring backend. For elevated security properties, consider using the `file` ke yring backend.
2023-10-21T22:45:38.162+0800 INFO node nodebuilder/init.go:209 NO KEY FOUND IN STORE, GENERATING NEW KEY... {"path": "/root/.celestia-light-mocha-4/keys"}
2023-10-21T22:45:38.209+0800 INFO node nodebuilder/init.go:214 NEW KEY GENER ATED...NAME: my_celes_key
ADDRESS: celestia1pnx0a88ckqkljcrcvajcsf0jgy2fg6j3tl2d95
MNEMONIC (save this somewhere safe!!!):
xxx xxxx2023-10-21T22:45:38.210+0800 INFO node nodebuilder/init.go:72 Node Store in itialized
root@good:~/celestia-node# celestia light init --p2p.network mocha
2023-10-21T22:46:31.910+0800 INFO node nodebuilder/init.go:31 Initializing Light Node Store over '/root/.celestia-light-mocha-4'
2023-10-21T22:46:31.914+0800 INFO node nodebuilder/init.go:63 Saved config {"path": "/root/.celestia-light-mocha-4/config.toml"}
2023-10-21T22:46:31.915+0800 INFO node nodebuilder/init.go:65 Accessing keyring...
2023-10-21T22:46:31.925+0800 WARN node nodebuilder/init.go:194 Detected plaintext keyring backend. For elevated security properties, consider using the `file` keyring backend.
2023-10-21T22:46:31.937+0800 INFO node nodebuilder/init.go:72 Node Store initialized
通过连接到验证器节点的grpc端点(通常在端口9090上)的轻节点:
如果您需要连接的RPC端点列表,则可以在Mocha TestNet页面上找到列表:https://docs.celestia.org/nodes/mocha-testnet/#rpc-endpoints
nohup celestia light start --core.ip full.consensus.mocha-4.celestia-mocha.com --p2p.network mocha > nohup_celestia.output 2>&1 &
参考
[推荐]Celestia专题系列1 : 什么是数据可用性(DA:Data Availability)
参考URL: https://zhuanlan.zhihu.com/p/493099971?utm_id=0
关于数据可用性问题的以太坊研究 wiki 帖子
https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding