大安区网站建设南昌响应式网站建设
目录
Feign简介
Feign的作用
Feign的使用步骤
引入依赖
具体业务逻辑
配置日志
在其它服务中使用接口
接着上一篇博客,我们讲过了nacos的基础使用,知道它是注册服务用的,接下来我们我们思考如果一个服务需要调用另一个服务的接口信息,我们应该怎么进行调用呢?这里,我们引入了feign来进行服务之间接口的调用~
Feign简介
Feign是声明式Web Service客户端,它让微服务之间的调用变得更简单,类似controller调用service。SpringCloud集成了Ribbon和Eureka,可以使用Feigin提供负载均衡的http客户端
只需要创建一个接口,然后添加注解即可使用Feign。
我们需要注意:Feign是声明式Web Service客户端,说明它和ribbon一样,都是在客户端使用的负载均衡工具,所以在使用Feign的时候,我们还是要在消费者微服务中去进行代码编写。
Feign的作用
Feign旨在使编写Java Http客户端变得更容易,前面在使用Ribbon + RestTemplate时,利用RestTemplate对Http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一个客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步的封装,由他来帮助我们定义和实现依赖服务接口的定义,在Feign的实现下,我们只需要创建一个接口并使用注解的方式来配置它 (类似以前Dao接口上标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon 时,自动封装服务调用客户端的开发量Feign默认集成了Ribbon利用Ribbon维护了MicroServiceCloud-Dept的服务列表信息,并且通过轮询实现了客户端的负载均衡,而与Ribbon不同的是,通过Feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
Feign的使用步骤
引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency>具体业务逻辑
在我的user-service这个服务中,有一个用户登录的接口
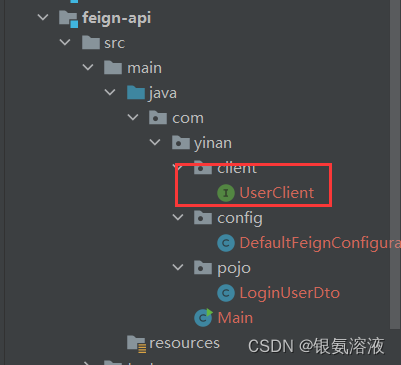
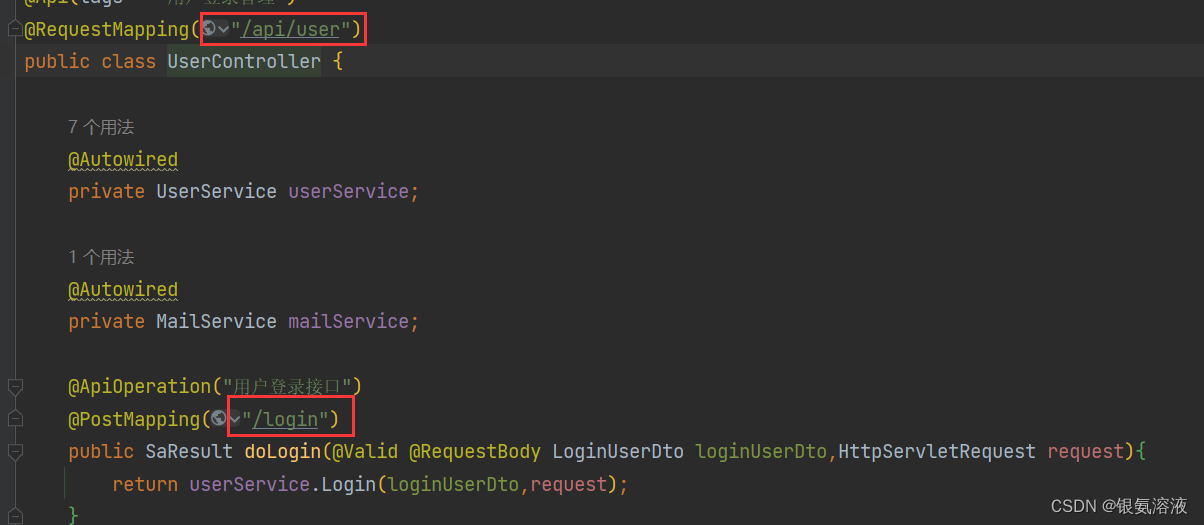 接下来,我们创建一个模块feign-api,在这个模块下创建UserClient接口
接下来,我们创建一个模块feign-api,在这个模块下创建UserClient接口
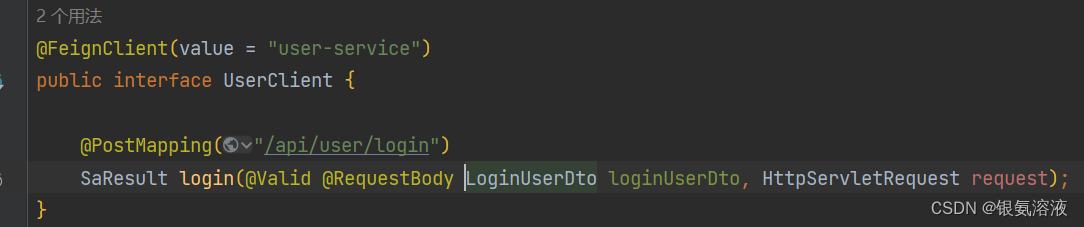
其中value = "user-service"的user-service是我的user-login模块配置在nacos服务上的服务名,其它的注解就和controller层的注解一样。
注意:还需要在这个接口上加上注解@Component/@Service,否则这个接口不会被spring托管/装配到spring容器中,那么我们在消费者model中使用这个类的时候就不能使用注解@Autowired实现对象自动注入到消费者的controller中(注意:我们是在springcould-api模块中定义的这个接口,并在这个接口上面加上了注解@Component,这个注解不是要在springcould-api模块中起作用,而是要在使用springcould-api模块的其他模块中起作用,即哪个模块导入了springcould-api模块,那么在这个model启动的时候,有注解@Component的这个接口就会被装配到spring容器中去,然后我们只需要在当前的这个模块中使用注解@Autowired就可以获取到这个接口在spring容器中的实例,就可以调用它内部的方法实现对应的功能)
配置日志
public class DefaultFeignConfiguration {@Beanpublic Logger.Level logLevel() {// 设置日志级别为BASICreturn Logger.Level.BASIC; }
}其中,feign有四种日志级别可供选择:
NONE:无日志记录(默认)BASIC:记录基本信息,包括请求方法和 URL 以及响应状态码和执行时间HEADERS:记录基本信息以及请求和响应的 HeaderFULL:记录请求和响应的 Header、Body 和元数据
具体请看 配置 Feign 的日志级别
在其它服务中使用接口
当我们实现好feign逻辑后,我们就可以在其他服务中,按照以下方式我们在要使用的服务的启动类上加上注解@EnableFeignClients,其中的属性分别为我箭头指向的逻辑。

注入feign-api到指定服务中
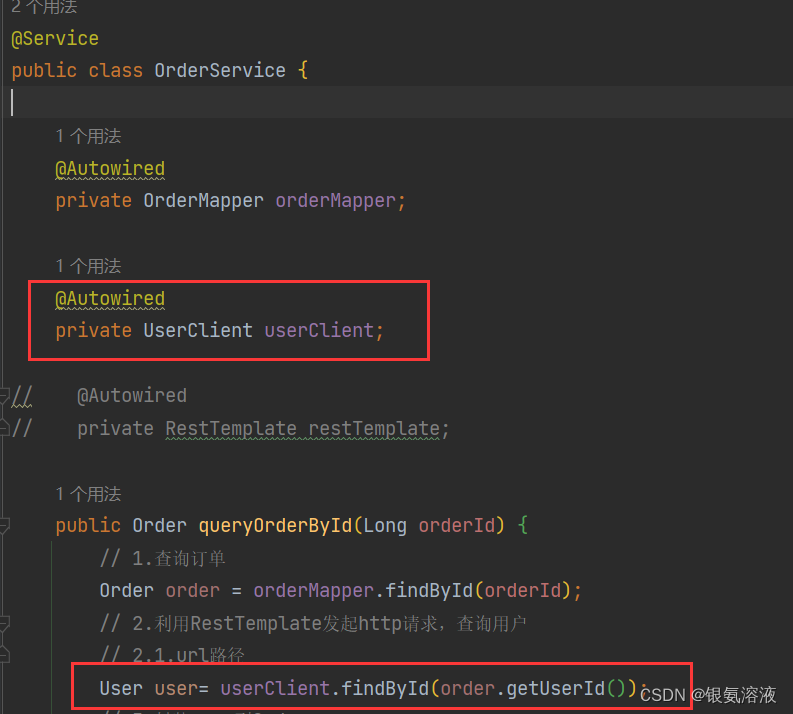
<!-- feign的客户端依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!-- 引入feign-api--><dependency><groupId>com.yinan</groupId><artifactId>feign-api</artifactId><version>0.0.1-SNAPSHOT</version></dependency>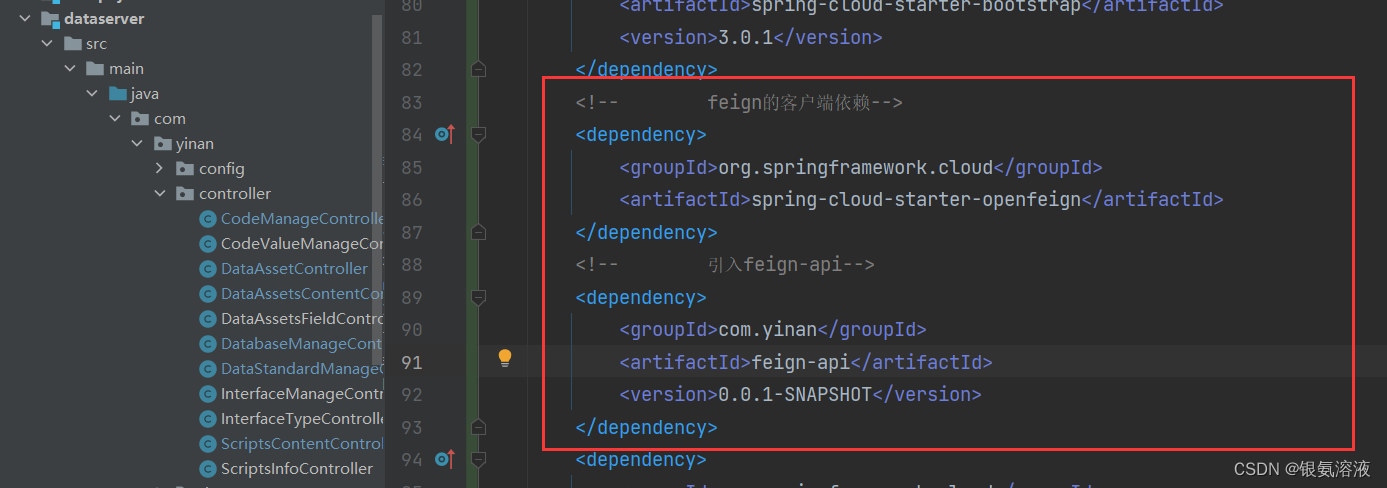 然后使用@Autowired注解将UserClient注入到需要使用到的代码中就可以啦~
然后使用@Autowired注解将UserClient注入到需要使用到的代码中就可以啦~
以下截图为我学习feign时的截图,并非我项目中的实际代码截图
以上就是feign的简单使用方法啦,希望能帮助到您~