电商网站的特点做美陈网站
首先声明,这个印刷/勘误并非经过官方的认可,只是我个人的粗浅的理解。如果内容有误,恳请大家谅解指正。
其实有的并不算错,只是我个人认为不太准确,在我学习过程中产生了一些小疑惑和误解。
都是一些小毛病,瑕不掩瑜,本文的目的并非挑刺。在我心目中这本书是经典中的经典,中文版的翻译也是难得的精品。
此外,我所整理的内容应该也不完善,也请大家一起进行补充。
英文版wiki主页:
Modern Robotics Errata - Northwestern Mechatronics Wiki
英文版勘误:
Modern Robotics Errata - Northwestern Mechatronics Wiki
1. 中文版88页,第四章前向运动学印刷错误:

中文版把这个M矩阵的左上角第一个数字印刷成了1。
2. 中文版121页,第五章一阶运动学与静力学第第二点常见奇异的标题,翻译不太准确。
《2.3个平面转动副轴线平行》应为 《2.3个共面转动副轴线平行》
3. 中文版139页,第六章逆运动学,图6.7的注释翻译不太准确
“....而当初始估计值在xd-f(theta)高点之上或附近,结果可能导致...”
这个英文原文为:
... and an initial guess at or near the plateau would result in...
这里是“at”而非“up”。因此不用翻译成“高点之上”,而是写成“...高点或附近..“即可。
4. 中文版140页,第六章逆运动学,倒数第三行,翻译有误
“Jb的伪逆应该作为物体速度旋量...”
这显然是翻译错误,因为雅可比的绝对不可能是旋量,这里原书中是这样写的:
“the pseudoinverse of should act on a body twist
"
这里的act on 应该翻译为 “作用于” 更合适,而不是翻译成“作为”。
5. 中文144页/英文版235页,第六章逆运动学,小结部分公式错误加入dot上标:
误把 写成了
,其实这个
上面是没有dot的,加上了dot意味着它是角速度了。
6.中文版151页,第七章闭链运动学,最后一行公式印刷错误:

中文版错误的把红色框内的b印刷成了s。
7.中文版180页,第八章开链动力学,第四行翻译不准确(这点待定):
“....,以及速度乘积分量”
英文原版中也为“a velocity product component”
翻译的本身是没问题的,但这里描述的是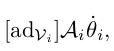
根据李括号的物理含义,个人认为这里应该为 叉积 而不是 乘积。
8. 中文版181页,第八章开链动力学,8.4小节下方第二行,印刷错误:
![]()
印刷的时候把“g”给漏掉了。
9. 中文版181页,第八章开链动力学,8.4小节,8.56式上方五行,翻译有误:
“....并且令表示由
确定的刚体雅可比矩阵。...”
这里很显然body不能翻译成“刚体”。根据书中之前的一贯描述,这里应该翻译为“物体”雅可比矩阵
10.中文版211页,第九章轨迹生成,(9.36)式印刷错误:
提到的“零惯量点”处印刷错误,写成了,实际上英文版原文是:
![]()

11.中文版258页,第十一章 机器人控制,第五行印刷错误1:
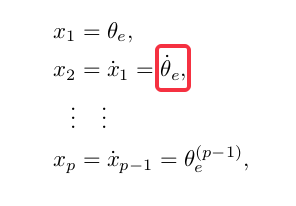
中文版书中在上方没有加那个“点”。
12. 中文版263页,第十一章 机器人控制,第五行印刷错误2:
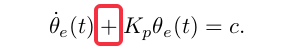
这里应该是加号,中文版错写成了等号。
13. 中文版275页,第十一章 机器人控制,(11.43式)上方一行翻译和之前不一致:
“...并使用为斜对称矩阵这一事实...”
这个翻译并没有任何错,但是书中一向称呼为“反对称矩阵”,私以为还是前后一致的好。。
14. 中文版297页,第十二章抓握与操作,(12.6式)印刷错误:

有效约束这里应该为等于,而非大于等于。
否则跟 12.5式 不可穿透性约束 成为一码事了。
15. 中文版299页,第十二章抓握与操作,倒数第二行印刷错误:
“....如果是接触接触则标签为S”,这里应该为“..如果是滑动接触则标签为S”
16. 中文版353页,第十三章 轮式移动机器人,第九行印刷错误:
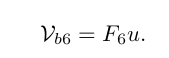
中文版把符号u给漏掉了。
感谢大家关注我的笔记专栏:
【现代机器人学】学习笔记