怎么利用云盘建设网站海南住建部建设网站的网站
撰文:Andrew Kang
编译:J1N,Techub News
本文来源香港Web3媒体:Techub News
比特币现货 ETF 的通过为许多新买家打开了进入加密货币市场的大门,让他们可以在投资组合中配置比特币。但以太坊现货 ETF 的通过,其影响则不那么明显。
当贝莱德比特币现货 ETF 申请提交时,我就对比特币的价格强烈看涨,当时比特币价格为 2.5 万美元,到了现在,比特币回报率为 2.6 倍,以太坊回报率为 2.1 倍。从周期底部开始,比特币回报率为 4 倍,以太坊回报率也为 4 倍。那么以太坊 ETF 能提供多少上行空间?我认为除非以太坊开拓出新的模式来改善其经济状况,否则不会有太大的上行空间。
我在 2023 年 6 月 19 日时表示⎡贝莱德申请比特币现货 ETF 的批准率高达 99.8%,这是我们最近听到的最积极的消息,可能为数百亿美元的资金流动打开闸门。然而,比特币价格仅上涨 6%,价格的表现未达到预期⎦。
流量分析
总体而言,虽然比特币现货 ETF 已积累了 500 亿美元的资产管理规模。但是,当通过排除预先存在的 GBTC 资产管理规模和置换(卖出期货或现货买入现货 ETF)来细分自推出以来的净流入量时,您会得到 145 亿美元的净流入量。然而,这些并不是真正的流入,因为有许多需要考虑的 delta 中性流量,即基差交易(卖出期货,买入现货 ETF)和卖出现货买入现货 ETF。通过查看 CME 数据和对 ETF 持有者的分析,我估计大约 45 亿美元的净流量可以归因于基差交易。ETF 专家表示,BlockOne 等大型持有者也将大量现货比特币转换为现货 ETF,大约估计为 50 亿美元。扣除这些流量,我们得出比特币现货 ETF 的真实净购买量为 50 亿美元
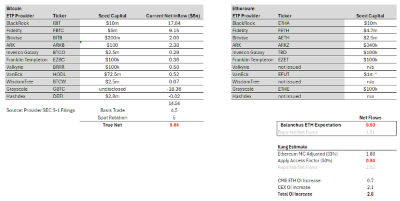
通过这种方式我们可以简单地推断以太坊的资金流量会是什么情况。彭博社 ETF 分析师 @EricBalchunas 估计以太坊流量可能是比特币的 10%。这使得 6 个月内真正的净购买流量为 5 亿美元,报告的净流量为 15 亿美元。尽管 @EricBalchunas 预测的准确率不高,但我相信他代表了一众传统金融机构的态度。
就我个人而言,我认为以太坊流量可能是比特币的 15%。从比特币 50 亿美元的真实净购买量(上文提到)开始计算,通过调整以太坊市值(占比特币的 33%)和 0.5 的⎡访问系数⎦,我们可以得出 8.4 亿美元的真实净购买量和 25.2 亿美元的报告净购买量。有一些合理的论据表明,ETHE (灰度以太坊期货 ETF)的溢价比 GBTC 要少,所以我认为乐观的情况是 15 亿美元的真实净购买量和 45 亿美元的报告净购买量。这大约占比特币流量的 30%。
无论哪种情况,预估的以太坊现货 ETF 的 15 亿美元真实净购买量都远低目前以太坊衍生品 28 亿的资金流入量,这还不包括现货的抢先交易(指市场预期看涨,提前买入现货)。这意味着在以太坊现货 ETF 上市前的资金流入量就超出预估的以太坊现货 ETF 资金流入量,因此以太坊现货 ETF 的价格在很大程度上已经被市场定价。
⎡访问系数⎦:根据 ETF 实现的流动性进行调整,考虑到不同的持有者基础,比特币明显比以太坊受益更多。例如,比特币是一种宏观资产,对存在准入问题的机构(宏观基金、养老金、捐赠基金、主权财富基金)更具吸引力。而以太坊则更像是一种技术资产,对 VC、加密货币基金、技术专家、散户等在加密货币准入方面没有那么严格限制的机构更有吸引力。50% 是通过比较以太坊与比特币的 CME OI (Open Interest,衍生品未平仓量)与市值比率得出的。
查看 CME 数据,在以太坊现货 ETF 推出之前,以太坊的 OI 明显低于比特币。OI 占供应量的约 0.3%,而比特币占供应量的 0.6%。起初,我认为这是早期的标志,但人们也可以说,这掩盖了传统金融资金对以太坊 ETF 缺乏兴趣的事实。华尔街交易员更偏向于交易比特币现货 ETF,他们往往掌握着一线的信息,因此如果他们没有在以太坊上使用同种交易方式,那么这一定是有充分理由的,可能意味着关于以太坊流动性的信息不足。
50 亿美元是如何将比特币从 4 万美元推高至 6.5 万美元的?
最明确直接的答案就是,单靠 50 亿美元是做不到的。因为现货市场上还有许多其他买家。比特币是一种真正在全球范围内被认可为关键投资组合资产的资产,并且拥有许多大机构长期持有 Saylor、泰达公司、家族办公室、高净值个人投资者等。虽然以太坊也有大机构持有,但我认为其数量级低于比特币。
请记住,在比特币现货 ETF 出现之前,比特币的最高价就已经达到 6.9 万美元,超 1.2 万亿美元以上市值。市场参与者、机构拥有大量现货加密货币。Coinbase 托管着 1930 亿美元,其中 1000 亿美元来自其它机构。 2021 年,Bitgo 报告 AUC 为 600 亿美元,币安托管 1000 多亿美元。6 个月后,比特币现货 ETF 托管了比特币总供应量的 4%。
我在 2 月 12 日发布了推文,关于加密货币市场的规模发表了观点,⎡我估计,今年长期的比特币需求量为 400-1300 亿美元以上。加密货币投资者最常见的大忌之一是低估世界上的财富、人们的收入、资金的流动性及其对加密货币的影响。我们经常听到有关黄金、股票、房地产市值的统计数据,以至于加密货币可能被许多人忽视。许多加密货币从业者都陷入了自己的局限思维中,但你旅行越多,结识的其他企业主、高净值人士等越多,你就越能意识到这个世界上的美元数量有多么难以想象,其中有多少可以进入比特币或其他加密货币。
让我通过粗略的需求规模练习来解释这一点。美国家庭平均收入为 10.5 万。美国有 1.24 亿个美国家庭,这意味着美国个人的年总收入为 13 万亿美元。美国占 GDP 的 25%,因此全球总收入约为 52 万亿美元。全球加密货币平均拥有率为 10%。在美国,这一比例约为 15%,在阿联酋则高达 25-30%。假设加密货币所有者每年只分配 1% 的收入,那么每年购买 BTC 的费用为 520 亿美元,每天为 1.5 亿美元⎦。
在比特币现货 ETF 推出时 MSTR (Microstrategy)和 Tether 购买了数十亿美元的比特币,以及当时进场的投资者,他们的持仓成本也属于低位。那时候人们普遍认为比特币现货 ETF 的通过是出货的信号。因此,数十亿美元的短期、中期和长期仓位已被出售,需要回购。最重要的是,一旦比特币现货 ETF 流量形成可观的上涨趋势,空头就需要回购。在比特币现货 ETF 推出之前,未平仓合约实际上有所下降,这很疯狂。
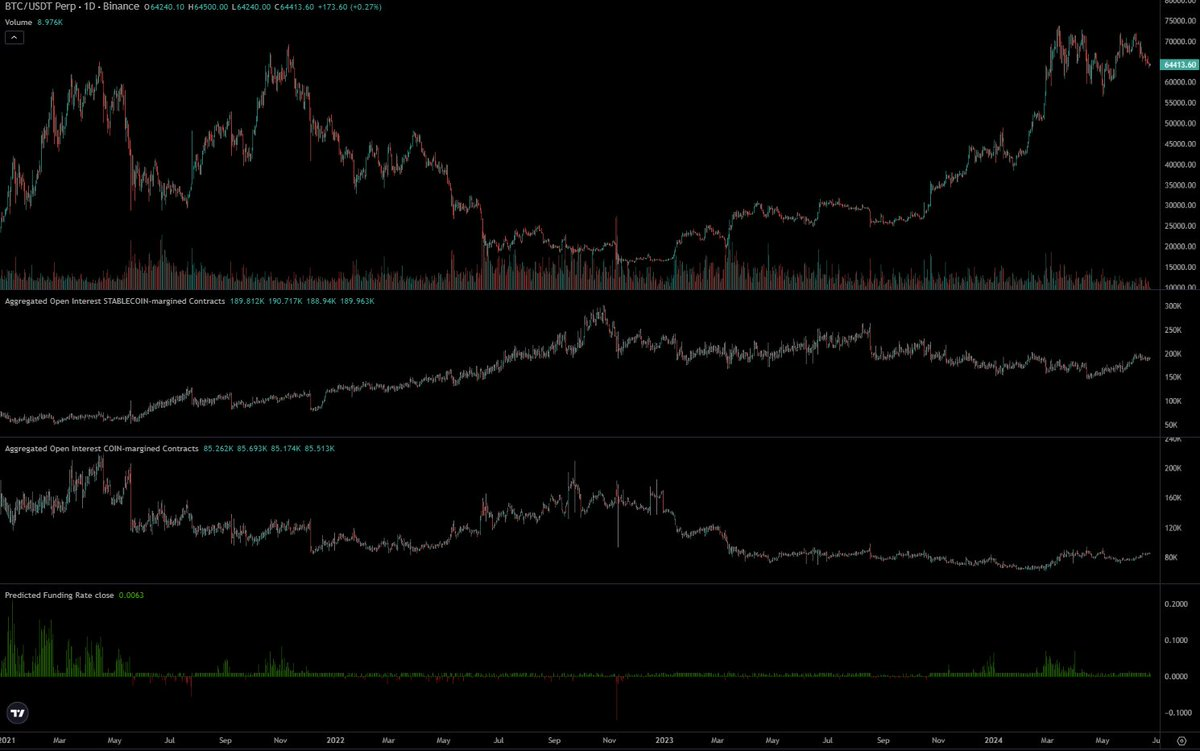
以太坊现货 ETF 的定位非常不同。以太坊价格现在是较现货 ETF 推出前低点的 4 倍,而比特币是 2.75 倍。加密货币原生 CEX OI 增加了 21 亿美元,使 OI 接近 ATH (历史最高价)水平。市场是有效的。当然,许多加密货币原生者看到了比特币现货 ETF 的成功,他们也对以太坊抱有同样的期望,并据此进行了定位。

就我个人而言,我认为加密货币原生用户的期望被夸大了,与传统金融市场的真实偏好脱节。就会导致那些深陷加密领域的人对以太坊的心理份额和购买量相对较高。实际上,对于许多大型非加密原生资本集团来说,以太坊作为关键投资组合配置的购买量要少得多。
传统金融最常见的宣传之一是以太坊是一种⎡科技资产⎦。全球计算机、Web3 应用商店、去中心化金融结算层等。这是一个不错的宣传,我在上一个周期中也买过它,但当你看实际收益时,很难接受。
在上一个周期中,你可以指出费用的增长率,并指出 DeFi 和 NFT 会产生更多的费用、现金流等,并以与科技股类似的视角将其作为一项技术投资提出令人信服的理由。但在这个周期,费用的量化是适得其反的。大多数图表都会显示持平或负增长。以太坊是一台提款机, 根据其年化率,只用 30 天的收入就为 15 亿美元,市盈率为 300 倍,扣除通货膨胀因素后的市盈率为负,分析师将如何向他们的家族办公室或宏观基金老板证明这一价格合理?

我甚至预计,前几周的 fugazi(通常指的是看起来大额交易量并不是由实际的资金流入引起)流量会较低,原因有二。首先,以太坊现货 ETF 的批准令人意外,发行人没有太多时间说服大额持有者将其以太坊转换为现货 ETF 形式。其次,持有者转换的吸引力较小,因为他们需要放弃质押或在 DeFi 中以太坊的收益。但请注意,目前以太坊质押率只有 25%。
这是否意味着以太坊将归零?当然不是,在某个价格下,它会被认为是物有所值的,当比特币未来上涨时,以太坊不一定会跟涨。在现货 ETF 推出之前,我预计以太坊的交易价格将在 3000 美元至 3800 美元之间。 现货 ETF 推出后,我的预期是 2400 至 3000 美元。但是,如果比特币在 2024 年 Q4 或者 2025 年 Q1 升至 10 万美元,那么这可能会将以太坊的价格突破 ATH,但以太坊比特币之后会走低。从长远来看,有一些发展值得期待,你必须相信贝莱德和 Fink 正在做大量相关工作,在区块链上建立一些金融基础设施,并将更多资产代币化。这对以太坊来说能带来多少价值,以及具体时间尚不确定。
我预计以太坊比特币将继续呈下降趋势,未来一年的比率将在 0.035 至 0.06 之间。尽管我们的样本量很小,但我们确实看到以太坊比特币每个周期都会创下更低的高点,所以这应该不足为奇。