什么网站发布任务有人做wordpress动态页面
指纹识别
1.CMS简介
CMS(Content Management System,内容管理系统),又称整站系统或文章系统,用于网站内容管理。用户只需下载对应的CMS软件包,部署、搭建后就可以直接使用CMS。各CMS具有独特的结构命名规则和特定的文件内容。
目前常见的CMS有DedeCMS、Discuz、PHPWeb、PHPWind、PHPCMS、ECShop、Dvbbs、SiteWeaver、ASPCMS、帝国、Z-Blog、WordPress等。
2.CMS指纹的识别方法
可以将CMS指纹识别分为四类:在线网站识别、手动识别、工具识别和Chrome浏览器插件(Wappalyzer)识别。不同的识别方法得到的结果可能不同,只需要比较不同结果,选取最可靠、最全面的结果。
(1)在线网站识别。
在线网站识别的主要工具如下。
BugScaner
潮汐指纹识别
云悉指纹识别
如图1-22所示,使用WhatWeb在线识别网站对“xxxxx.com”进行CMS指纹识别。
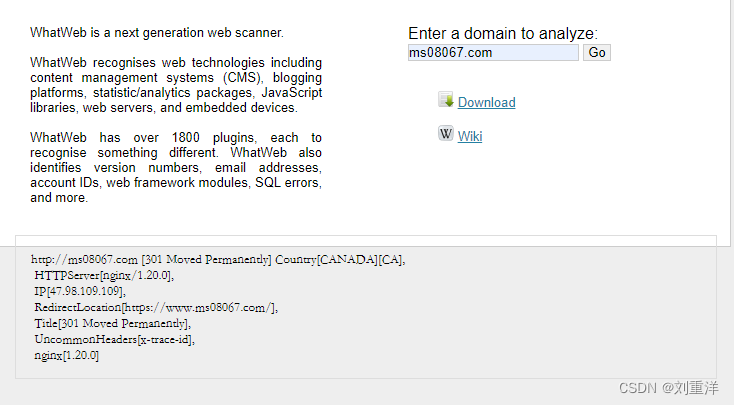
从检测结果中可以看出,“xxxxx.com”使用的中间件为Nginx,使用了Bootstrap框架进行开发。如果使用了某种CMS,则CMS的指纹信息也会显示。
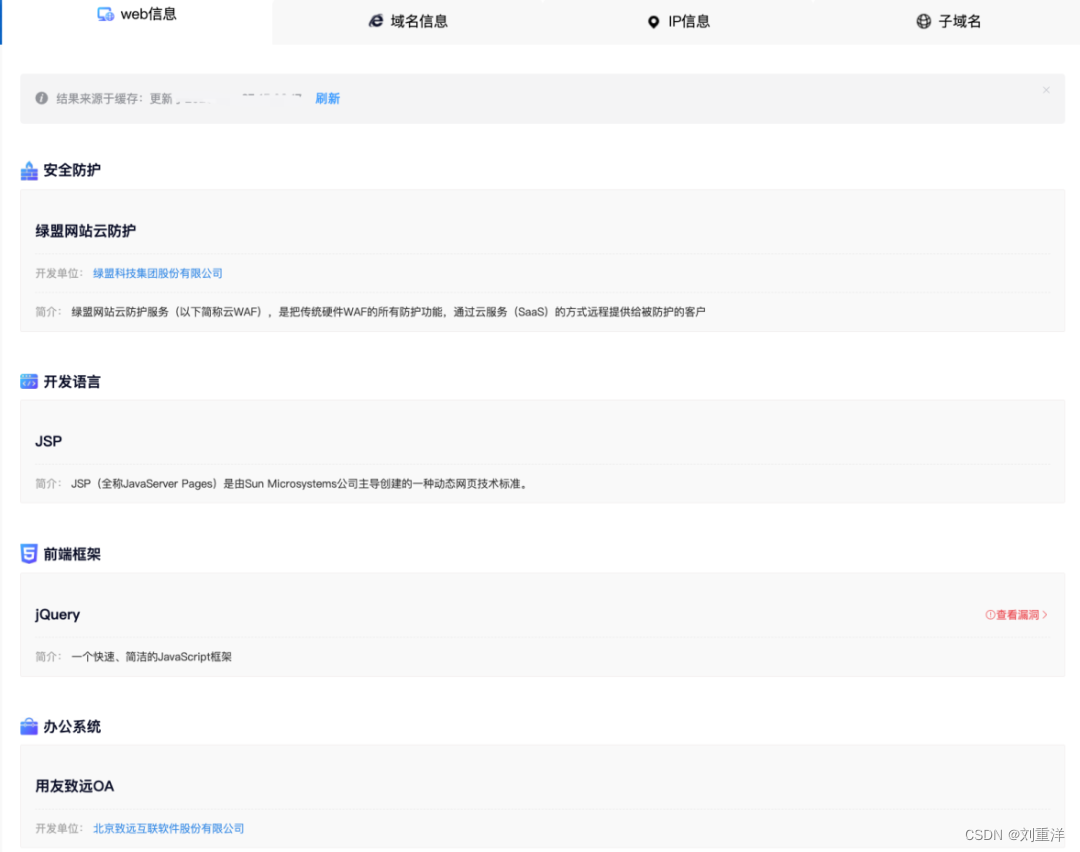
图1-23所示为使用云悉指纹识别对某网站进行CMS指纹识别的结果。可以看到,该网站使用了用友致远OA的办公系统,并且使用了绿盟网站云防护系统。
(2)手动识别。
根据HTTP响应头判断,重点关注X-Powered-By、Cookie等字段。
根据HTML特征,重点关注body、title、meta等标签的内容和属性。
根据特殊的CLASS类型判断,HTML中存在特定CLASS属性的某些DIV标签。
(3)工具识别。
指纹检测工具可以快速识别一些主流的CMS,并且当我们需要批量识别资产时,使用工具的多线程选项会帮助我们更快速地得到识别结果。如图1-24所示,使用WhatWeb工具对“xxxxx.com”进行指纹识别。

检测结果和在线版WhatWeb在内容详细程度上有所差异,但在主要的检测内容上基本一致,其中对参数“-v”的设置能起到返回详细检测内容的作用。命令行版WhatWeb还支持批量检测及插件管理,非常适合批量梳理Web资产指纹信息。
常用的CMS指纹检测工具如下。
Ehole
Glass
14Finger
WhatWeb工具版
(4)Chrome浏览器插件(Wappalyzer)识别。
Wappalyzer是一款功能强大且非常实用的Chrome网站技术分析插件,通过该插件能够分析目标网站所采用的平台构架、网站环境、服务器配置环境、JavaScript框架、编程语言、中间件架构类型等参数,还可以检测出CMS的类型。
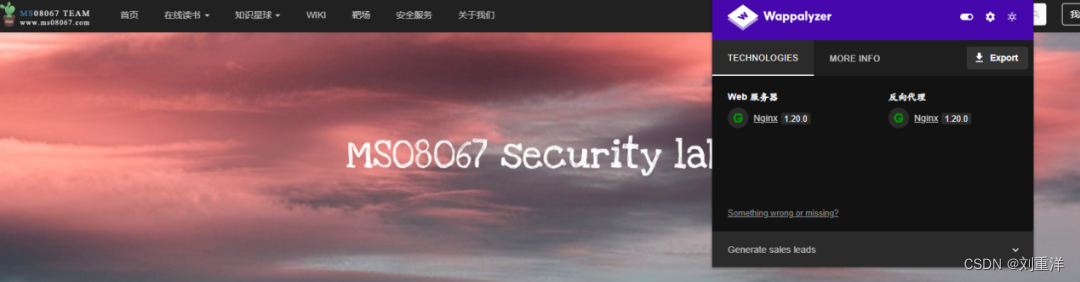
如图1-25所示,用该插件检测出“xxxxx.com”使用的Web中间件为Nginx。要想获得更多信息,读者可以根据自己的喜好开通高级权限来检测。
如果以上工具中没有目标网站的CMS指纹,则有可能目标网站是经过二次开发或完全自主开发的。这时,就需要寻找目标的一些突出特征,与当前目标有很强关联性的代码、目录、文件名,或者是网站的ICO图标文件。
得到相同网站的信息后,就可以通过渗透的手段,对其他网站进行渗透。这种手段在目标防控非常严格时比较有效,可以获得安全防护较为薄弱的网站,甚至是目标的测试站的信息,以曲线方式得到源代码,然后进行代码审计。
也可以在GitHub中搜索特征串或特征文件名,有可能获得二次开发前的CMS源码。