HTML建网站百度下载安装
3dsMax插件Datasmith Exporter安装使用方法
某些文件格式无法用Datasmith直接导入虚幻引擎,这些数据必须先被转换为Datasmith能够识别的文件格式。Datasmith Exporter插件就可以帮助您的软件导出可以被Datasmith导入虚幻引擎的.udatasmith格式文件。
在开始使用虚幻引擎中的3dMax内容之前,您就需要安装3dMax的Datasmith Exporter插件。本文就给大家讲解Datasmith Exporter插件的安装和卸载方法。
【适用版本】
3dMax2017 - 2024
【安装方法】
按照以下步骤为计算机上安装的任何支持版本的3dMax安装Datasmith Exporter插件。
1.关闭计算机上运行的所有3dMax实例。如果任何实例仍在运行,则安装将失败。
2.如果您已经安装了旧版本的Datasmith Exporter插件,我们建议您先卸载它。
3.双击运行安装程序。
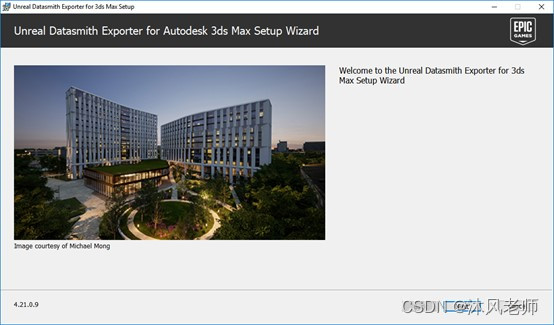
4.按照屏幕上的提示继续,并接受许可协议。
5.安装程序会自动检测系统上安装的3dMax版本。选中要通过Datasmith导出的每个版本的复选框,然后单击“安装”。

提示:Epic在每次发布虚幻引擎时都会为3dMax发布新版的Datasmith Exporter插件。如果您切换到不同版本的虚幻引擎,请确保下载并安装匹配版本的插件。
【卸载插件】
使用标准的Windows控制面板实用程序可以从系统中查找和删除用于3dMax的Datasmith Exporter应用程序。
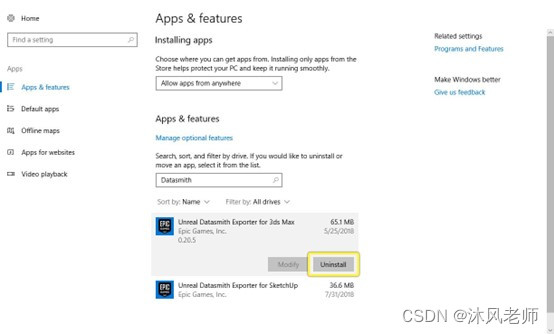
例如,在Windows 10上,您可以使用“应用程序和功能”控制面板。单击列表中Datasmith导出器插件的条目,然后单击卸载:
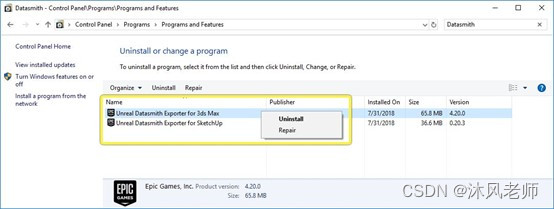
或者,使用“卸载或更改程序”控制面板。右键单击Datasmith导出器插件的条目,然后从上下文菜单中选择“卸载”:
【使用方法】
安装3dMax的Datasmith Exporter插件后,导出场景时可用的UDATASMITH文件类型。
在3dMax中按照以下步骤使用此新文件类型导出场景。
1. 从3dMax的“文件”菜单或主菜单栏最左侧的“Max”菜单中,选择“导出”。

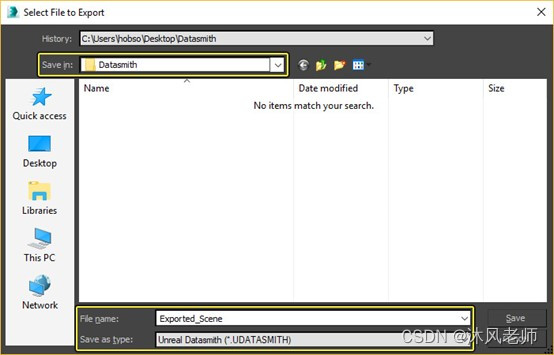
2. 设置以下内容:
保存位置:为新的Datasmith文件选择一个位置。
文件名:给你的文件一个名字。
另存为类型:选择Unreal Datasmith(*.UDATASMITH)
3.单击“保存”。
4.在Datasmith Export Options(数据史密斯导出选项)窗口中,您可以筛选要包含在导出文件中并转入虚幻引擎的信息。
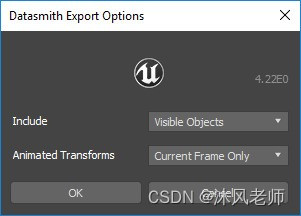
5.单击“确定”。
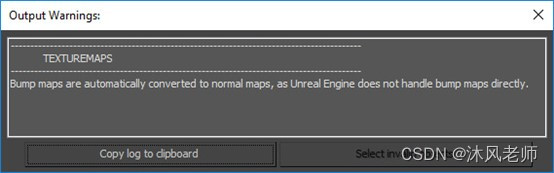
导出完成后,导出器会显示其在内容中发现的问题的报告——通常,这些都是导出器无法完美翻译或者可能不会像在3dMax中那样在虚幻引擎中显示的警告性提示。
提示:与新的.udasmith文件一起,您将看到一个名称相同但后缀为_Assets的文件夹。如果将.udatasmith文件移到新位置,请确保也将此文件夹移到同一位置。