如何在微信小程序上开店成都seo优化排名公司
1. 下载安装
参照:MySQL8.0下载安装_凯尔萨厮的博客-CSDN博客
2. MySQL启动与停止
方式(1).我的电脑>右键>管理>服务和应用程序>服务>(或在windows搜索栏输入services.msc)
找到MySQL80,右键启动或停止
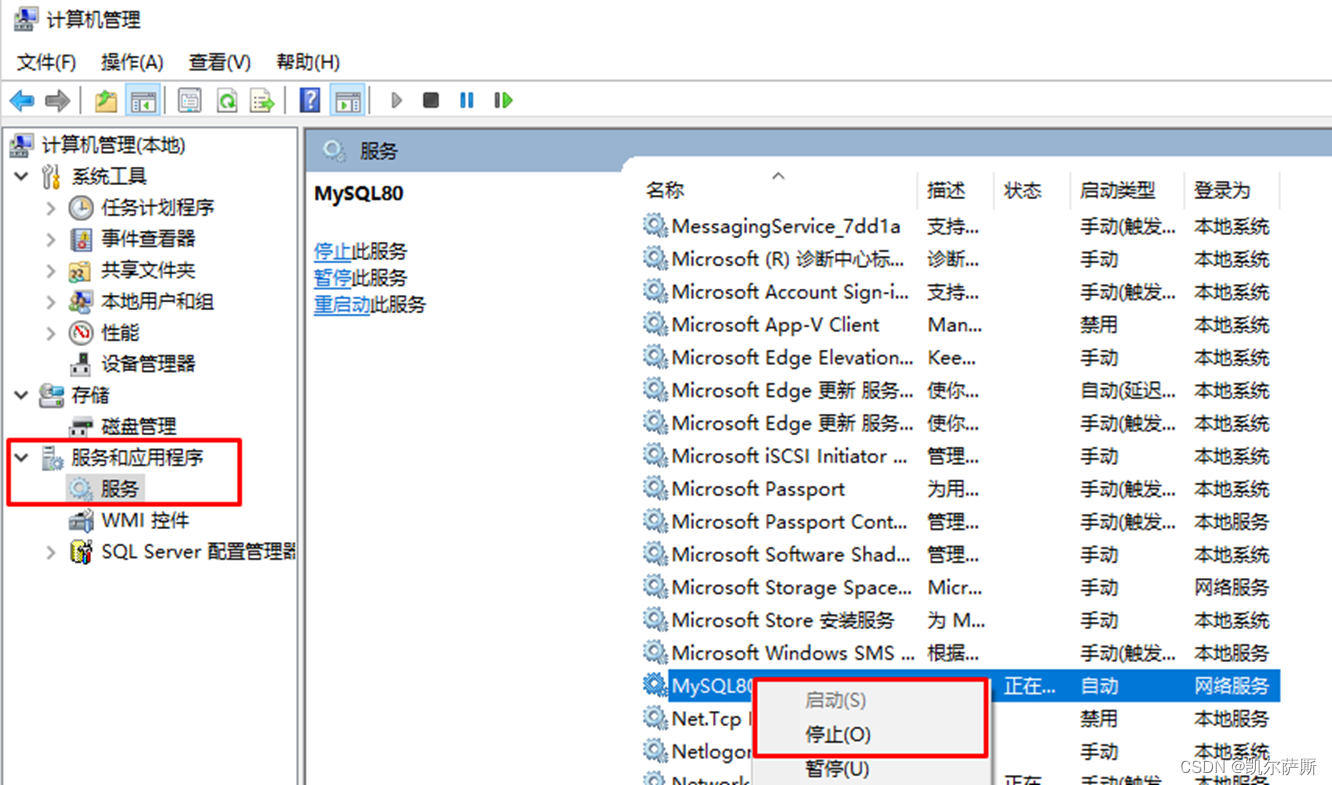
方式(2).管理员权限打开cmd,
启动命令:net start mysql80
停止命令:net stop mysql80

3. 连接MySQL客户端
方式(1).搜索栏输入:mysql 8.0 command line client 回车

输入密码完成连接
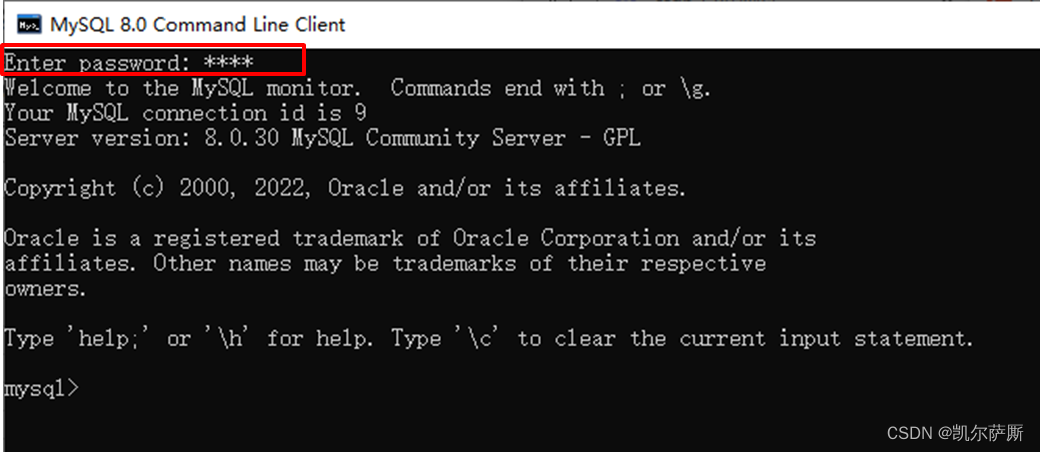
方式(2). 打开cmd命令
前提:要在任意目录执行MySQL命令,需要在Path中配置环境变量
![]()
输入命令:mysql -h localhost -P 3306 -u root -p
然后输入密码,完成连接
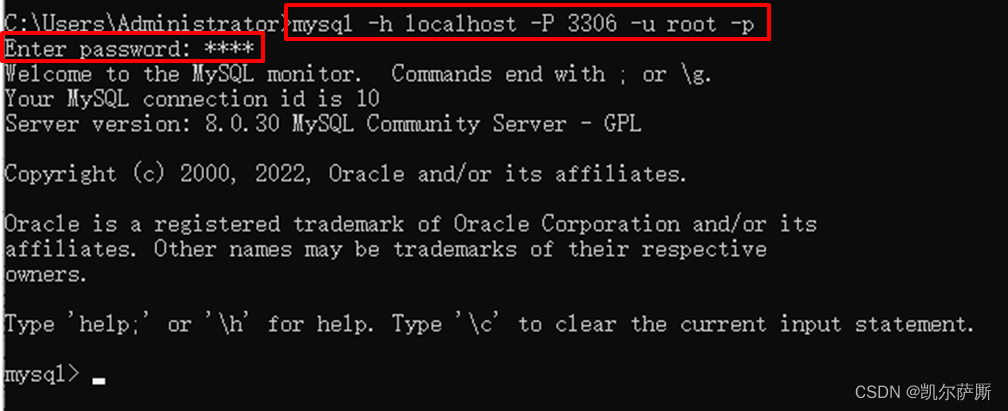
如果是本机mysql可以直接输入命令:mysql -u root -p

4. DDL-数据库操作(查询,创建,删除)
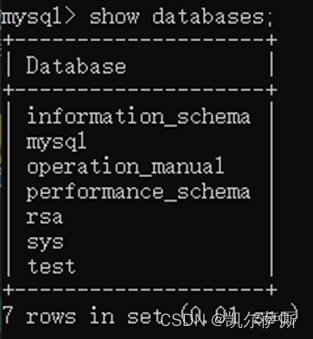
(1). 查询所有数据库
show databases;
(2).选择切换数据库
use {数据库名};

(3). 查询当前数据库
select database();

(4). 创建数据库
create database [if not exists] {数据库名} [default charset {字符集}];

(5). 删除数据库
drop database {数据库名};

5. DDL-表操作(查询,创建,修改,删除)
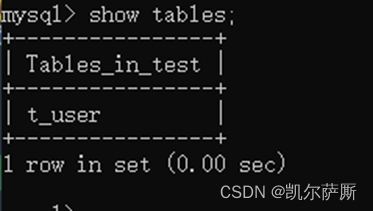
(1). 查询所有表
show tables;
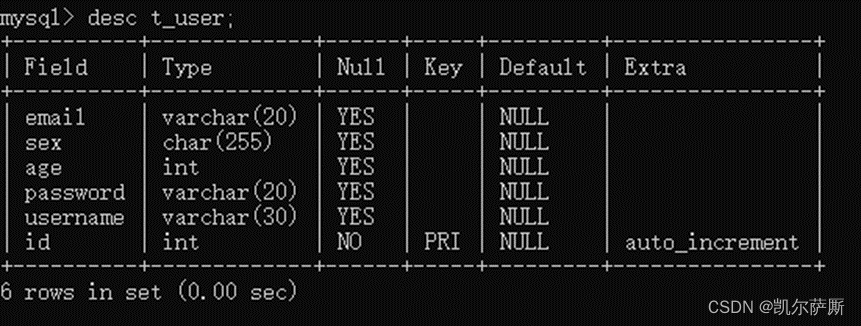
(2). 查询表结构
desc {表名};
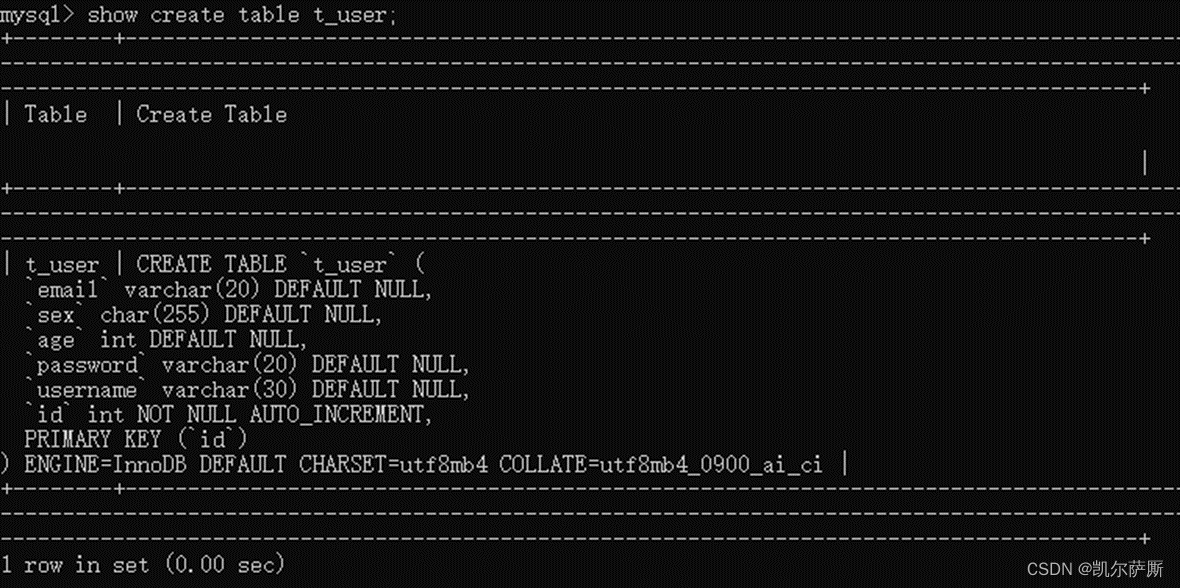
(3). 查询建表语句
show create table {表名};
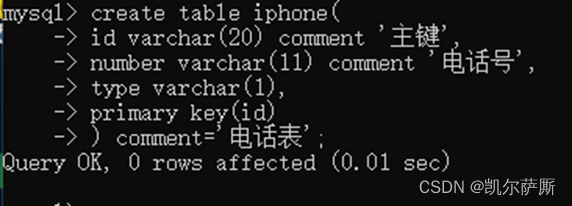
(4). 创建表
create table {表名} (
{字段名} {类型} [COMMENT 注释],
{字段名} {类型} [COMMENT 注释]
) [COMMENT=表注释]
(5). 修改表-添加字段
alter table {表名} add {字段名} {类型} [comment注释,约束];

(6). 修改表-修改类型
alter table {表名} modify {字段名} {类型} [comment注释,约束];

(7). 修改表-修改字段名与类型
alter table {表名} change {旧字段名} {新字段名} {新类型} [comment注释,约束];

(8). 删除字段
alter table {表名} drop {字段名};

(9). 修改表名
alter table {表名} rename to {新表名};

(10). 删除后再新建表(清空数据,需要用户有删除表权限)
truncate table {表名};

(11). 删除表
drop table [if exists] {表名};

6. DML-数据操作(增删改)
(1). 插入数据
单条插入(指定字段名)
insert into {表名} (字段1, 字段2, ...) values (值1, 值2, ...);

单条插入(全部字段,按顺序)
insert into {表名} values (值1, 值2, ...);

批量插入(指定指定名)
insert into {表名} (字段1, 字段2, ...) values (值1, 值2, ...), (值1, 值2, ...), ...;

批量插入(全部字段,按顺序)
insert into {表名} values (值1, 值2, ...), (值1, 值2, ...), ...

(2). 修改数据
update {表名} set {字段1}={值1}, {字段2}={值2}, ... [where 条件];

(3). 删除数据
delete from {表名} [where 条件];

7. DQL-数据操作(查询)
编写顺序
select from where group by having order by limit;
(1). 查询(指定字段)
select {字段1}, {字段2}, ... from {表名} [where 条件];
查询(全部字段)
select * from {表名} [where 条件];
(2). 去除重复查询
select distinct {字段1}, {字段2}... from {表名} [where 条件];
(3). 条件查询
select * from {表名} where
比较运算符:等于[{字段1} = {值1}], 不等于[{字段1} != {值1}, {字段1} <> {值1}]
大于[{字段1} > {值1}], 大于等于[{字段1} >= {值1}]
小于[{字段1} < {值1}], 小于等于[{字段1} <= {值1}]
在范围之间[ beturn {大于等于.小值} and {小于等于.大值} ]
在指定值之中[ in {值1}, {值2},... ], 不在之中 not in
像指定值[ like ('_{值}_')] [ like (‘%{值}%’) ] , 不像 not like
空 [ {字段1} is null ], 非空 [ {字段1} is not null ]
逻辑运算符: 与 and , && . 或 or , || . 非 !
(4). 分组查询
select * from {表名} where {条件} group by {分组字段} having {分组后查询条件};
(5). 排序查询
select * from {表名} where {条件} order by {排序字段} [asc];// 升序
select * from {表名} where {条件} order by {排序字段} desc;// 降序
select * from {表名} where {条件} order by {排序字段1} desc, {排序字段2} asc;// 降序
(6). 分页查询
select * from {表名} where {条件} limit {起始索引} {查询记录数};// 索引从0开始
例:select * from {表名} where {条件} limit 0 10;// 首页 10条记录
例:select * from {表名} where {条件} limit 10 10;// 第二页 10条记录
注释: DQL执行顺序,from 决定表, where 决定条件,group by having 分组, select决定项目,order by排序,limit 分页。
(7). 关联查询
隐式内联:select * from {表1} {表2} where {过滤条件};
显示内联:select * from {表1} inner join {表2} on {联结条件} where {过滤条件};
左外联结:select * from {表1} left [outer] join {表2} on {联结条件} where {过滤条件};
右外联结:select * from {表1} right [outer] join {表2} on {联结条件} where {过滤条件};
全外联结:select * from {表1} full outer join {表2} on {联结条件} where {过滤条件};
(8). 联合查询
select * from {表1} union select * from {表2};
select * from {表1} union all select * from {表2};
(9). 嵌套查询(子查询)
标量子查询:select * from {表1} where {字段} = (select {字段} from {表2});
行子查询:select * from {表1} where {字段, 字段} = (select {字段, 字段} from {表2});
列子查询:select * from {表1} where {字段} [in,any,some,all] (select {字段} from {表2});
表子查询:select * from {表1} where {字段, 字段} in (select {字段, 字段} from {表2});
注释:子查询位置 where from select后
(10). 流程函数
if ( {表达式}, {字段1}, {字段2});// 如果表达式成立,则字段1,否则字段2
ifnull ( {字段1}, {字段2} ); // 如果{字段1}是null则用字段2,否则字段1
case when {表达式} then {字段1} else {字段2} end; // 如果表达式成立,则字段1,否则字段2
case {字段1} when {值1} then {} when {值2} then {} else {} end; // 如果满足条件,则,否则
8. DCL-数据访问权限控制(查询,创建,删除,授权)
(1). 查询用户
use mysql;
select * from user;
(2). 创建用户
create user '{用户名}'@'{主机名}' identified {密码};
例:create user 'admin1'@'localhost' identified '123456'; // 本地访问权限
例:create user 'admin2'@'%' identified '123456'; // 全部机器访问权限
(3). 修改密码
alter user '{用户名}'@'{主机名}' identified with mysql_native_password by {新密码};
(4). 删除用户
drop user '{用户名}'@'{主机名}';
(5). 用户权限
all, allprivileges 所有权限
select insert update delete 查询,插入,修改,删除权限
alter, drop, create 修改表,创建数据库与表,删除数据库与表
(6). 查询用户权限
show grants for '{用户名}'@'{主机名}';
(7). 授予用户权限
grant {权限},{权限}... on {数据库.表名} to '{用户名}'@'{主机名}';
例:grant {权限},{权限}... on {数据库}.* to '{用户名}'@'{主机名}'; // 数据库下所有表
例:grant {权限},{权限}... on *.* to '{用户名}'@'{主机名}'; // 所有数据库所有表
(8). 撤销权限
revoke {权限},{权限}... on {数据库.表名} from '{用户名}'@'{主机名}';