网站建设网络门户深圳的公司排名
I/O配置
主输出、从输入(MOSI)
主出从入(MOSI )引脚是主器件的输出和从器件的输入,用于主器件到从器件的串行数据传输。当SPI 配置为主器件时,该引脚为输出,当 SPI 配置为从器件时,该引脚为输入。数据传输时 MSB 在前。
主输入、从输出(MISO)
主入从出(MISO )引脚是从器件的输出和主器件的输入,用于从器件到主器件的串行数据传输。当SPI 配置为主器件时,该引脚为输入,当 SPI 配置为从器 件时,该引脚为输出。数据传输时 MSB 在前。
串行时钟(SCK)
串行时钟(SCK )引脚是主器件的输出和从器件的输入,用于同步主器件和从器件之间在 MOSI 和MISO 线上的串行数据传输。当 SPI 配置为主器件时,该引脚输出时钟,当 SPI 配置为从器件时,该引脚为输入。
从选择(SSN)
从选择(SSN )引脚用来控制从器件选中,如 图 16-2所示,当 SPI 配置为主器件时, SSN 引脚必须接高电平,当 SPI 配置为从器件时, SSN 引脚必须接 低电平。
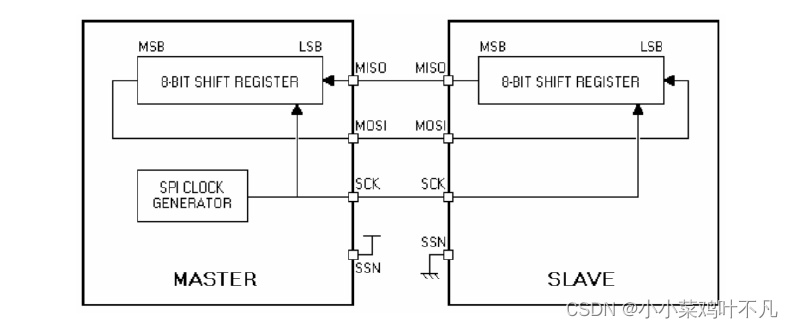
SPI主从器件的连接如图 所示:
主从器件的MOSI 、 MISO 和 SCK 分别连在一起,主器件的 SSN 必须接高电平,从器件的 SSN 必须接低电平。主从器件通过 MOSI 、 MISO 连成一个环路,主器件输出时钟,数据传输时,主器件通过MOSI 输出数据,从器件通过 MISO 输出数据。一字节数据传输完毕,主从器件将交换 8 位移位寄存器数值。
数据传输配置
1、 进行数据传输前需先配置 SPCR.SPE 位和 SPCR.MSTR 位,以使能 SPI 和设置主从模式。
2、 配置 SPCR.CPHA 位和 SPCR.CPOL 位,以设置串行时钟相位和极性(主从器件需一致)。
3、 配置 SPCR1.SPR3 位和 SPCR.SPR[2:0] 位,以设置串行时钟波特率(若为从器件模式则不用设置,串行时钟速率由主器件决定)。
4、 需要时,配置中断,配置 IRCIE2.SPIIE,SPCR.SPIE 和 SPCR.SPIF 位。
5、 主器件模式下数 据传输前需先将从器件的 SSN 引脚拉低,主器件的 SSN 引脚必须保持高电平。主器件模式下 MCU 写 SPDR 寄存器的动作启动数据传输,中断标志 SPIF 置起完成数据传输。
6、 从器件模式处理较为特殊,当 CPHA=0 时,从器件的 SSN 引脚拉低启动数据传输,从器件的SSN 引脚拉高结束数据传输(即使在此之前 SPIF 中断已经产生),因为从器件不知道传输何时开始,当 SSN 引脚拉低后, MISO 引脚立即开始数据 MSB 的传输。
当CPH A=1 时,从器件在串行时钟的第一个沿启动数据传输,在 SPIF 置位后结束数据传输。
数据冲突
当SPITXBUF 数据尚未被读进移位寄存器,或者 SPIRXBUF 中的数据未被 CPU 读取时,对SPITXBUF/SPIRXBUF 寄存器的写操作会产生对应的冲突错误, SPIIF.TXCOL/SPIIF.RXCOL 位会置起,产生中断。导致冲突的写入数据将被忽略。数据冲突错误在主从模式下都会产生。
对SPITXBUF 的写 操作,由芯片内部的 Master 模块发起,包括 CPU 、 DMA 等等。对 SPIRXBUF的写操作,则由外部 SPI 器件发起。
当数据冲突发生时,SPITXBUF 和 SPIRXBUF 内原有数据不会被刷新,新写入的数据丢失。