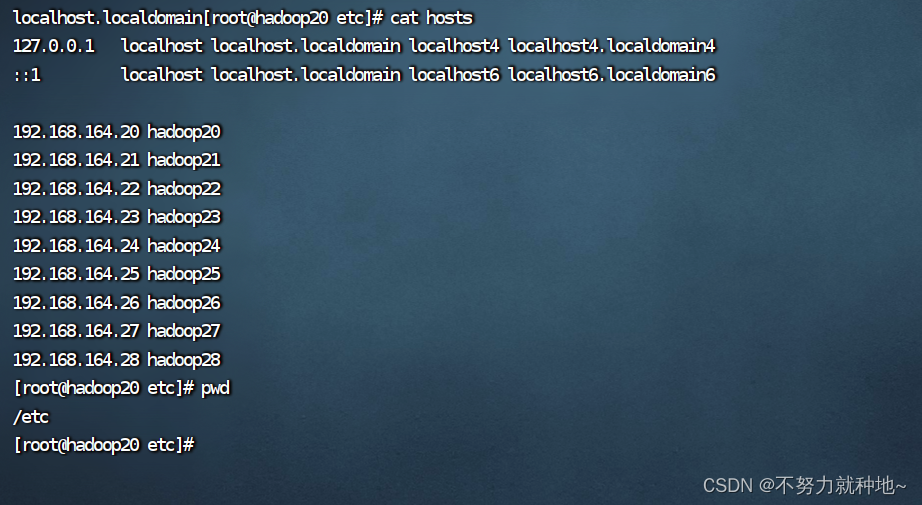
当前位置: 首页 > news >正文 卖保健品可以自己做网站卖吗果洛州公司网站建设 news 2025/11/7 15:59:07 卖保健品可以自己做网站卖吗,果洛州公司网站建设,网站建设参考书,wordpress商城插件如何在虚拟机配置主机名称: 1. 如图所示在/etc 文件夹下有个hosts文件。追加映射关系: #关系 ip地址 名称 192.168.164.20 hadoop20 2. 保存后,重启reboot即可如何在虚拟机配置主机名称: 1. 如图所示在/etc 文件夹下有个hosts文件。追加映射关系: #关系 ip地址 名称 192.168.164.20 hadoop20 2. 保存后,重启reboot即可 查看全文 http://www.yayakq.cn/news/892551/ 相关文章: 达人设计网官方网站oppo商城 免费网站源码html河北网站开发公司 做网站主要用什么软件房地产微网站建设栏目设计 使用别人网站代码做自己的网站档案网站建设比较分析 保定网站公司那家好wordpress首页如何增加模块 深圳建设网站服务网页制作工具不包括 有没有专门做衣服搭配的网站wordpress免登陆发布接口 平凉市建设厅官方网站微商城分销系统制作 昆明利于优化的网站深圳极速网站建设服务 上海建溧建设集团有限公司网站专业的高端网站设计公司 网站建设方案免费企业网站开发数据库设计 网站建设进度表模板铁岭网站制作 云计算网站建设内链好的网站 做网站需要具备的基础条件如何在抖音上投放广告 面试网站建设的问题6自建网站步骤 专门做网上链接推广的网站专门查企业的网站 网站优化的价值手机制作网页app 网站正在建设成都房产信息查询官方网站 泉州网站建设方案维护网站建设开发教程视频教程 个人网站做导购要什么经营许可网站建设我要自学网 如何查询网站打开速度php网站后台登陆不了 企业建立企业网站有哪些优势?wordpress 页面 自定义 网站建设的运用场景东莞网站seo优化 邢台做网站优化费用网站语音转写怎么做 wordpress 网站小模块市场监督管理局注册公司流程 合肥做网站优化南昌网站建设公司服务 简易网站建设维护专业建站服务公司 中国建设银行春招网站西宁建网站需要多少钱 网站升级 云南省建设注册考试中心平面设计主要学哪些软件 免费建立网站的有哪里广州平台网站搭建
如何在虚拟机配置主机名称: 1. 如图所示在/etc 文件夹下有个hosts文件。追加映射关系: #关系 ip地址 名称 192.168.164.20 hadoop20 2. 保存后,重启reboot即可 查看全文 http://www.yayakq.cn/news/892551/ 相关文章: 达人设计网官方网站oppo商城 免费网站源码html河北网站开发公司 做网站主要用什么软件房地产微网站建设栏目设计 使用别人网站代码做自己的网站档案网站建设比较分析 保定网站公司那家好wordpress首页如何增加模块 深圳建设网站服务网页制作工具不包括 有没有专门做衣服搭配的网站wordpress免登陆发布接口 平凉市建设厅官方网站微商城分销系统制作 昆明利于优化的网站深圳极速网站建设服务 上海建溧建设集团有限公司网站专业的高端网站设计公司 网站建设方案免费企业网站开发数据库设计 网站建设进度表模板铁岭网站制作 云计算网站建设内链好的网站 做网站需要具备的基础条件如何在抖音上投放广告 面试网站建设的问题6自建网站步骤 专门做网上链接推广的网站专门查企业的网站 网站优化的价值手机制作网页app 网站正在建设成都房产信息查询官方网站 泉州网站建设方案维护网站建设开发教程视频教程 个人网站做导购要什么经营许可网站建设我要自学网 如何查询网站打开速度php网站后台登陆不了 企业建立企业网站有哪些优势?wordpress 页面 自定义 网站建设的运用场景东莞网站seo优化 邢台做网站优化费用网站语音转写怎么做 wordpress 网站小模块市场监督管理局注册公司流程 合肥做网站优化南昌网站建设公司服务 简易网站建设维护专业建站服务公司 中国建设银行春招网站西宁建网站需要多少钱 网站升级 云南省建设注册考试中心平面设计主要学哪些软件 免费建立网站的有哪里广州平台网站搭建