什么软件可以刷网站排名太原seo建站
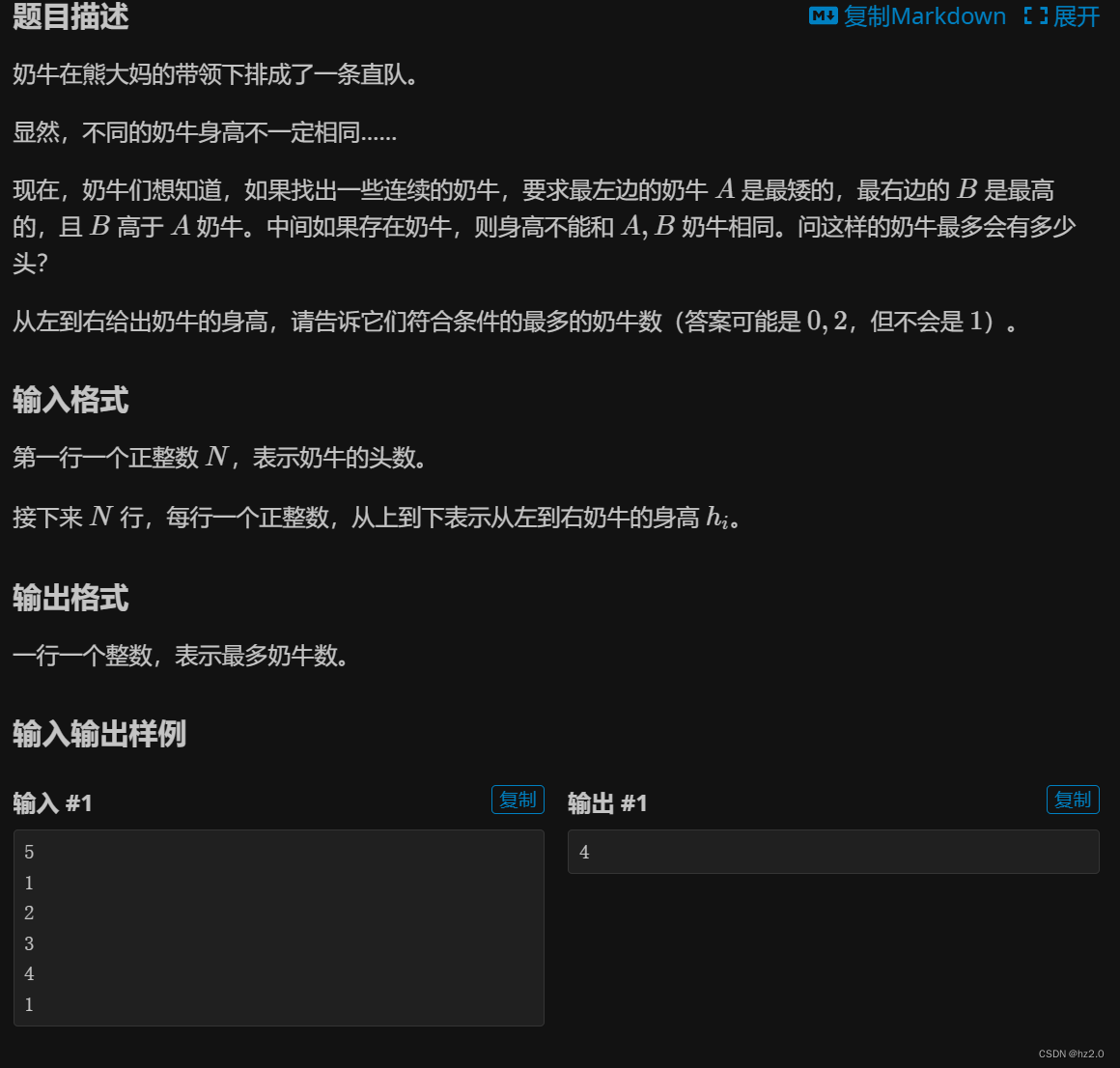
题目
P6510 奶牛排队 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
思路
1.dp求最大。(dp即前后关联)arr[]用于存储输入的数据,brr[i]用于存储以第i头牛为右端点的队列最大值。
2.数组空间不够大,我们可以自己开辟对空间(new)
3.注意:int *p=new(10)表示的是开辟一个空间,里面存储的是10,把地址赋给p。int *p=new[10]表示开辟一个长度为10的空间,并把该段空间的首地址赋给p。特别需要注意的是空间里的值是乱序的而非0。其中第1个地址的值可以表示为*p或者p[0]。
代码
#include<iostream>
#include<vector>
using namespace std;
typedef unsigned long long ull;
ull* arr = new ull[1e5];//存储数据
ull* brr = new ull[1e5];//存储以i为右端点的最长队列
int main()
{ull n,i,max=0;cin >> n;arr[0] = 0;for (i = 1; i <= n; i++) cin >> arr[i];//输入数据for (i = 0; i <= n; i++)brr[i] = 0;//初始化for (i = 1; i <= n; i++) {if (arr[i] > arr[i - 1])//当前牛比前一个高brr[i] = brr[i-1] + 1;}for (i = 1; i <= n; i++) {if (brr[i] > max)max = brr[i];}cout << max;delete[]arr;delete[]brr;
}
//自己编译器能过,不知道为什么洛谷上编译错误,求大佬解答嘻嘻嘻