视频网站开发架构做网站卖专业卖文玩
1. 两阶段终止-interrupt
Two Phase Termination
在一个线程T1中如何“优雅”终止线程T2?这里的【优雅】指的是给T2一个料理后事的机会。
错误思路
● 使用线程对象的stop()方法停止线程(强制杀死)
—— stop()方法会真正杀死线程,如果这时线程锁住了共享资源,那么当它被杀死后就再也没有机会释放锁,其它线程将永远无法获取锁
● 使用System.exit(int)方法停止线程
—— 目的仅是停止一个线程,但这种做法会让整个程序都停止
2. 两阶段终止-interrupt分析
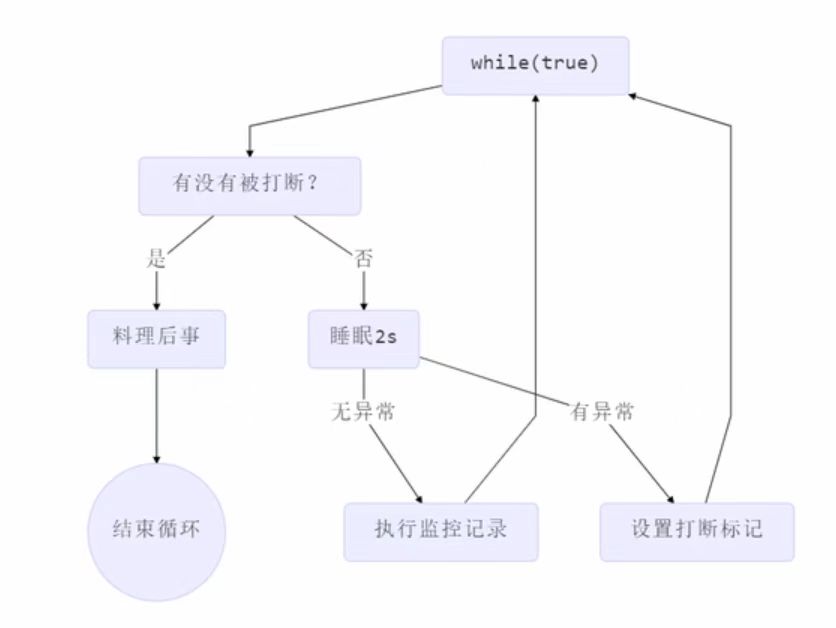
有如下场景,做一个系统的健康状态监控(记录电脑CPU的使用率、内存的使用率)实现定时监控。实现这样一个场景,可用一个后台的监控线程不断记录。
代码实现:
import lombok.extern.slf4j.Slf4j;@Slf4j(topic = "c.Test")
public class Test {public static void main(String[] args) throws InterruptedException {TwoPhaseTermination tpt=new TwoPhaseTermination();// 启动监控线程(每隔1秒执行监控记录)tpt.start();// 模拟非正常打断,主线程经过3.5后,被interrupt()===>优雅打断Thread.sleep(3500);tpt.stop();}
}
// 监控类代码
@Slf4j(topic = "c.TwoPhaseTermination")
class TwoPhaseTermination{// 创建监控线程private Thread monitor;// 启动监控线程public void start(){// 创建线程对象monitor=new Thread(()->{// 不断被执行监控while (true){// 获取当前线程对象,判断是否被打断Thread current = Thread.currentThread();if(current.isInterrupted()){// 若被打断log.debug("料理后事");break;}// 若未被打断(每隔2s执行睡眠,进行监控操作)try {Thread.sleep(1000); // 情况1===>非正常打断(睡眠过程中)log.debug("执行监控记录"); // 情况2===>正常打断} catch (InterruptedException e) {e.printStackTrace();// 重新设置打断标记(sleep()被打断后会清除打断标记)current.interrupt();}}});monitor.start();}// 停止监控线程public void stop(){// "优雅"打断monitor.interrupt();}
}运行结果:
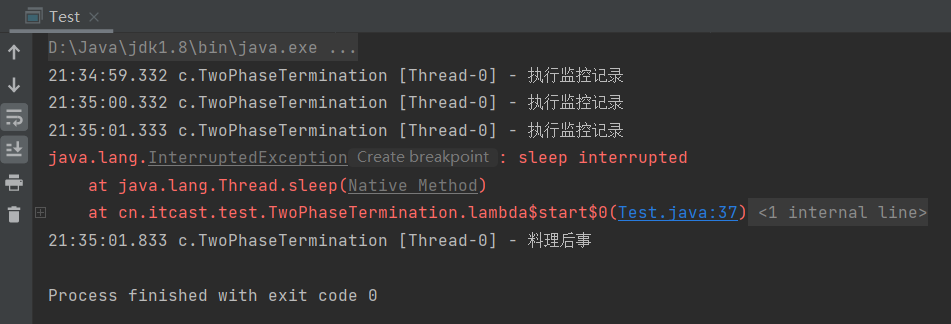
分析:监控线程每隔1s监控系统,主线程处于休眠状态,3.5秒后休眠状态被打断
*****interrupted()与isInterrupted()均为判断当前线程是否被打断,表面上看起来类似。但却有着很大的区别,调用isInterrupted()不会清除打断标记,而调用interrupted()判断完后会将打断标记清除
3.interrupt-打断Park线程
打断 park 线程, 不会清空打断状态
Park线程:不是Thread中的方法, 是LockSupport工具类中的方法,其作用也是使当前线程停下来
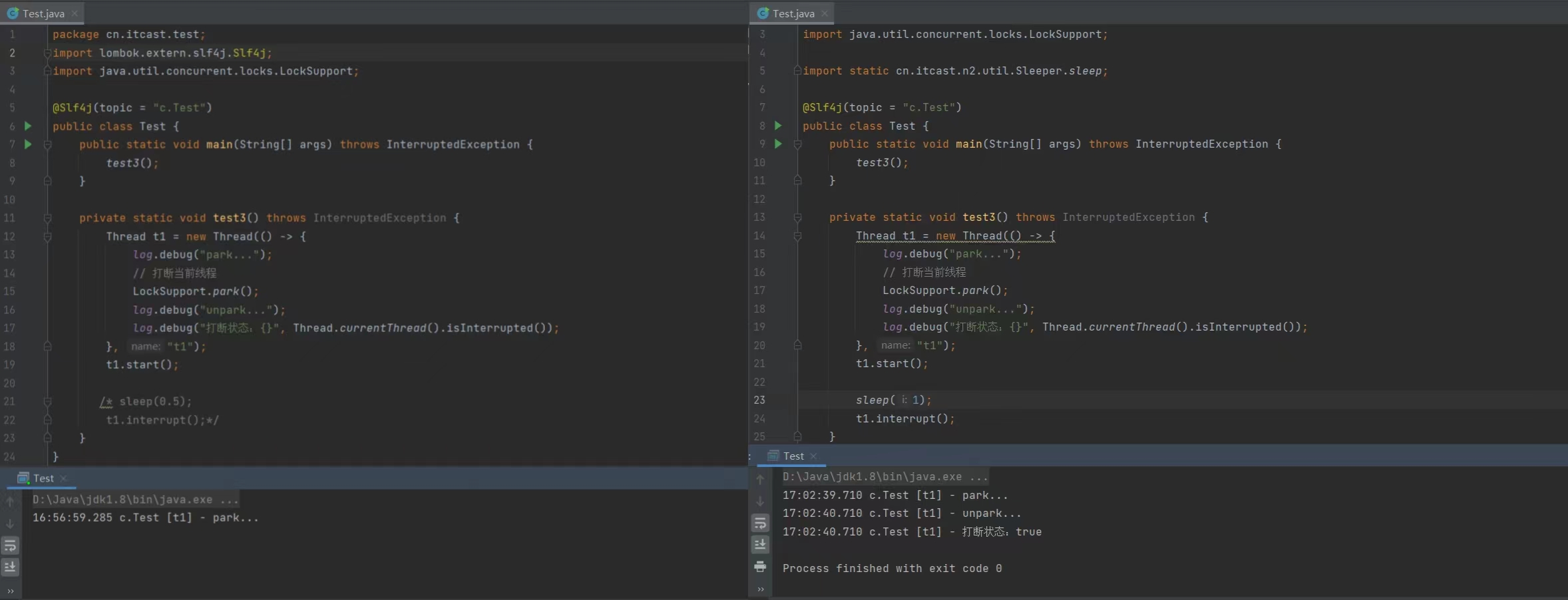
private static void test3() throws InterruptedException {Thread t1 = new Thread(() -> {log.debug("park...");LockSupport.park();log.debug("unpark...");log.debug("打断状态:{}", Thread.currentThread().isInterrupted());}, "t1");t1.start();sleep(1);t1.interrupt();
}
运行结果:调用park()后线程不会继续向下运行,使用interrupt()打断处在park状态的线程后此时线程会继续向下运行
 注意:打断标记为真的情况下,再次park会失效
注意:打断标记为真的情况下,再次park会失效
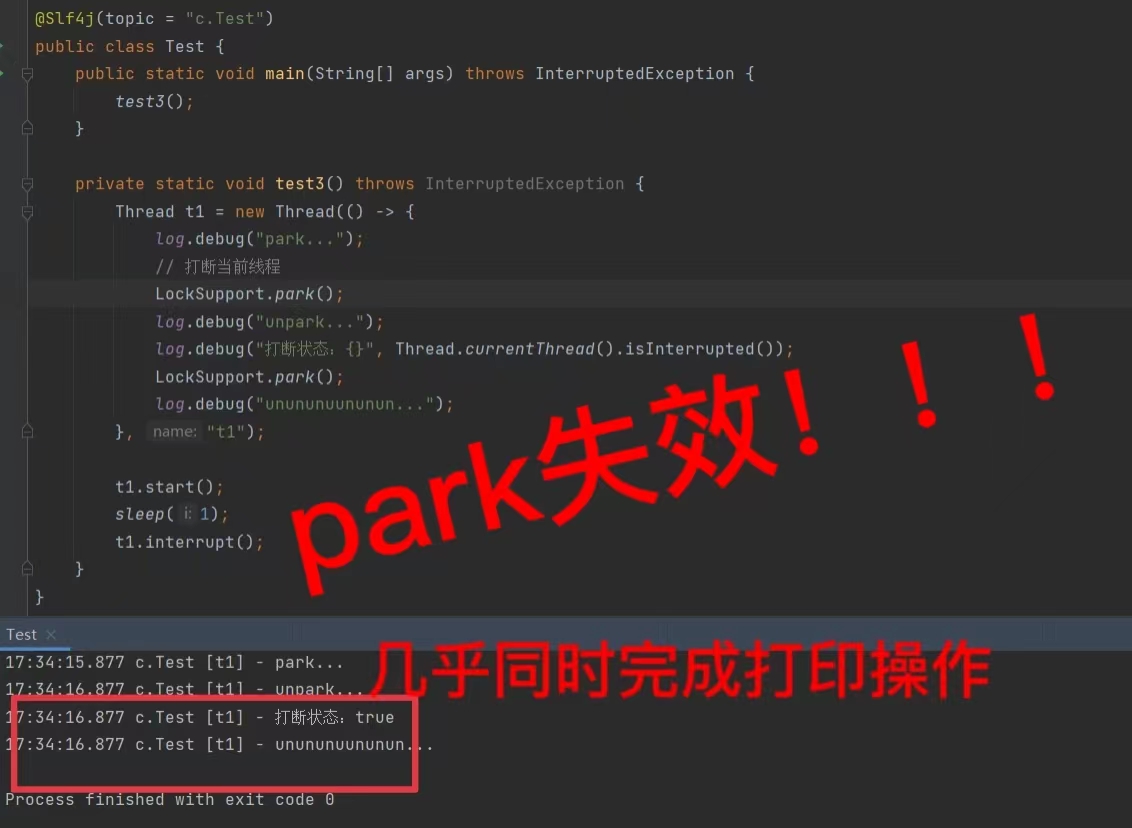
如何使其park后还能再次停止下来?
可将打断标记置为假(使用Thread.interrupted(),其会将打断标记清除,置为假)