小影 wordpress网站优化模板
操作流程
准备两个服务器
主服务器配置
1>修改主配置文件 /etc/my.cnf
[mysald]
log-bin=mysql-bin //[必须]启用二进制日志server-id=12>重启 mysql 服务
3>创建mysql用户并授权
mysql> GRANT REPLICATION SLAVE ON ** to 'slaver'@%' identified by '123456;4>查看当前主服务器信息
mysql> show master status;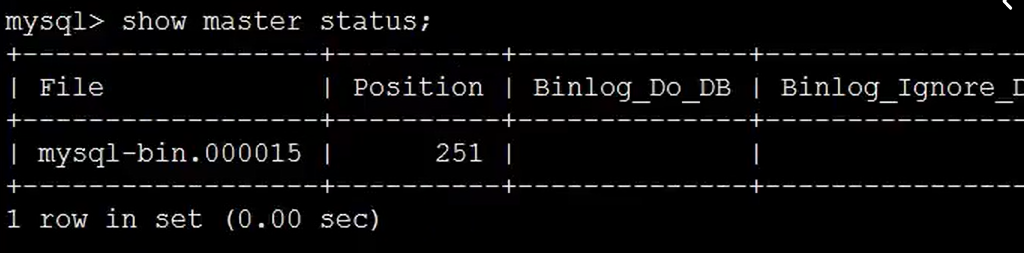
从服务器配置
1>修改主配置文件 /etc/my.cnf
[mysgld]
server-id=2 //这里必须要跟主服务器区分开2>设置主服务器相关参数
change master to master_host=[主服务器IP地址',master_user='用户名",master_password="密码',master_log_file='日志文件地址',master_log_pos=位置;
master_log_file
master_log_pos
数据参考上图 File position
mysgl> change master to master_host='192.168.209.128',master_user=slaver,master_password='123456',master_log_file='mysql-bin.000015',master_log_pos=251;3>启动同步
mysql> start slave4>查看从服务器状态
mysql> show slave status \G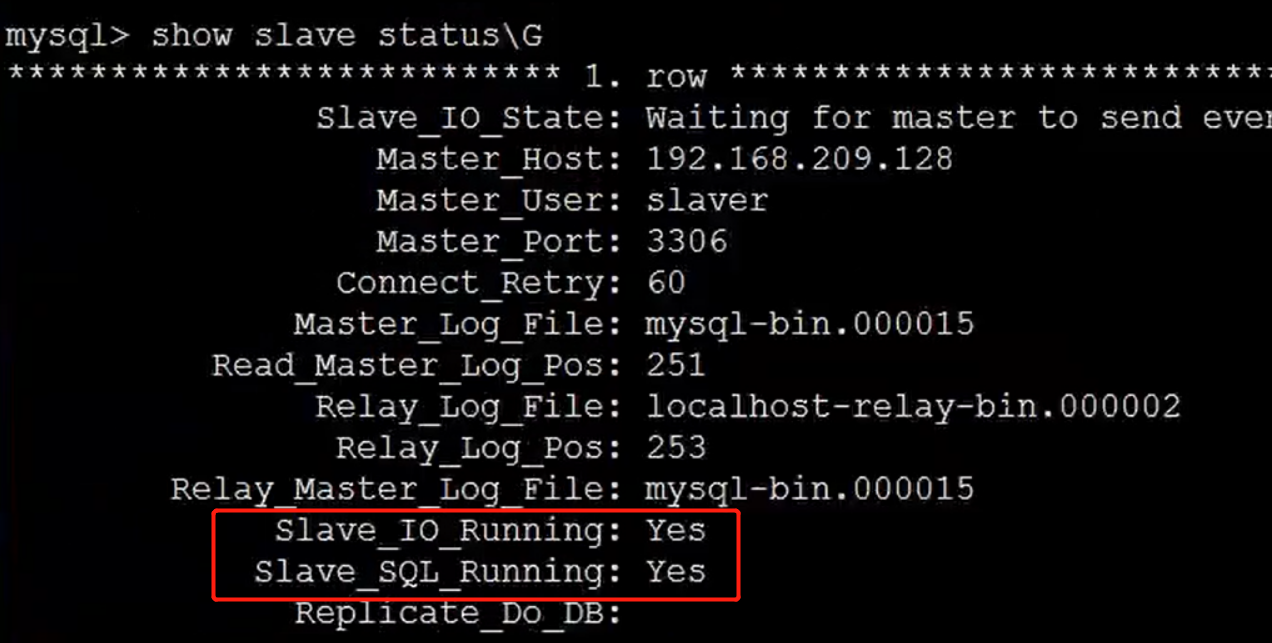
这两个yes表示从服务器链接成功
最后测试下在主服务器修改数据,从服务器是否同步