长沙手机网站制作法律网站建设价格
学习资料
软件工程知识点总结_嘤桃子的博客-CSDN博客
软件工程学习笔记_软件工程导论第六版张海藩pdf-CSDN博客
【软件工程】软件工程期末试卷习题课讲解!!_哔哩哔哩_bilibili
【拯救者】软件工程速成(期末+考研复试+软考)均适用. 支持4K_哔哩哔哩_bilibili
软件工程导论-张海藩(第六版)期末+考研复习_哔哩哔哩_bilibili
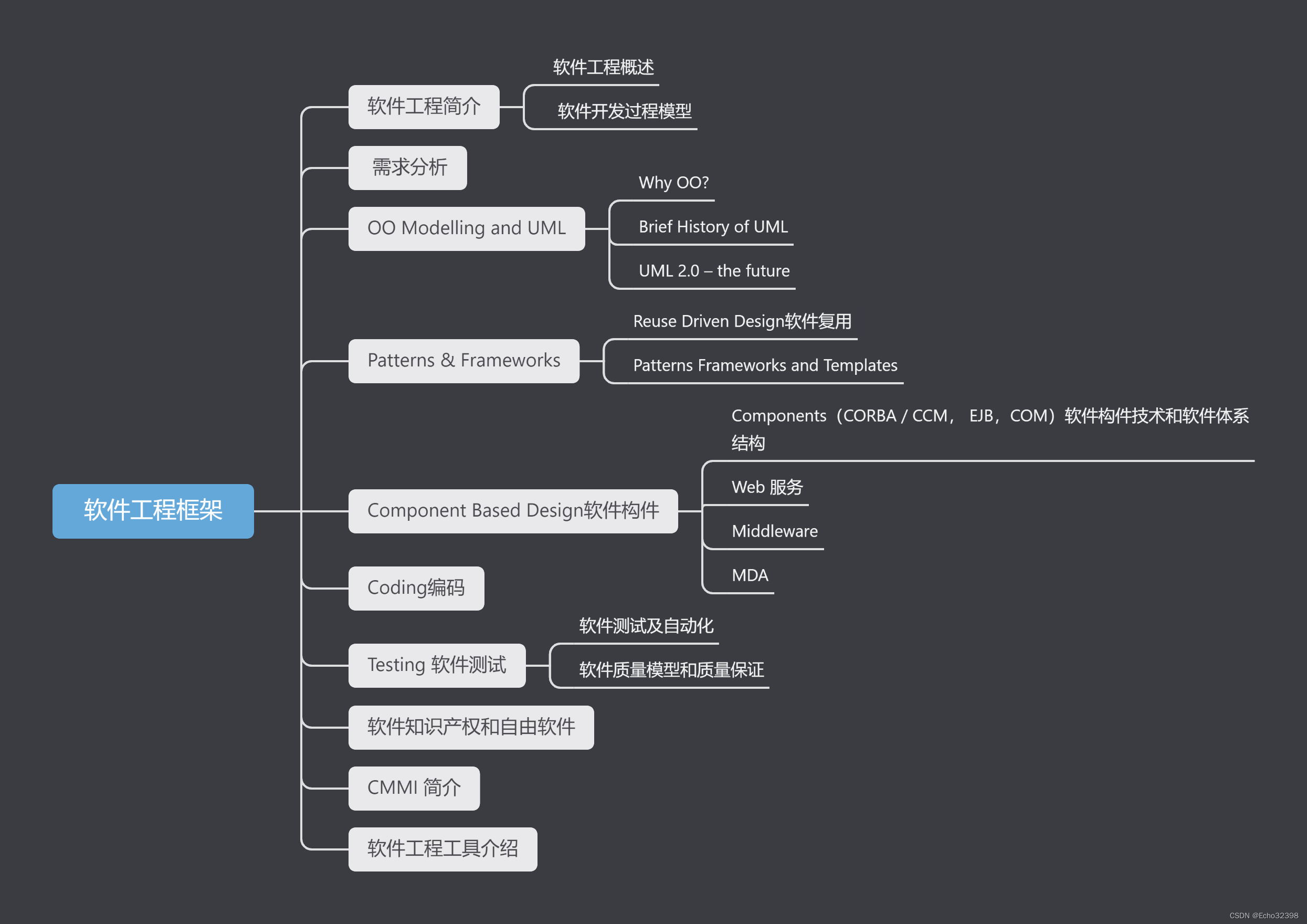
总体框架
考试要求
考试:无期中考试,只有一次期末考试,形式为书面的闭卷考试。内容以课堂所讲和作业要求为准。注意:期末考试一定会考要求写程序代码的题目!!!
第一章 软件工程简介
1.1 软件工程概述
1.1.1软件定义
软件是计算机系统中与硬件相互依存的另一部分,它是包括程序,数据及其相关文档的完整集合。
1.1.2软件危机
软件危机(Software Crisis):指由于落后的软件生产方式无法满足迅速增长的计算机软件需求,从而导致软件开发与维护过程中出现一系列严重问题的现象。
- 始于1960年代
- 计算机应用逐渐普及,软件的数量急剧膨胀,软件的复杂度急剧上升,软件的成本急剧增加
- 同时软件开发的效率低下,软件的质量难以保证,软件的开发周期长且难以控制,软件难以维护
1968年,NATO(北约)的一些科学家提出了“软件工程”的概念,即“为了经济的获得可靠的能在世纪机器上运行的软件,而建立和使用完善的工程原理”,企图借助于将工程原理用于软件开发,以缓解软件危机。
软件工程:采用工程的概念、原理、技术和方法来开发与维护软件,把经过时间考验而证明正确的管理技术和当前能够得到的最好的技术方法结合起来,经济的开发出高质量的软件并维护它
1.1.3传统软件的生命周期
软件计划 需求分析 软件设计(包括总体设计和详细设计) 编码 测试 运行维护
1.2软件开发过程模型
瀑布模型
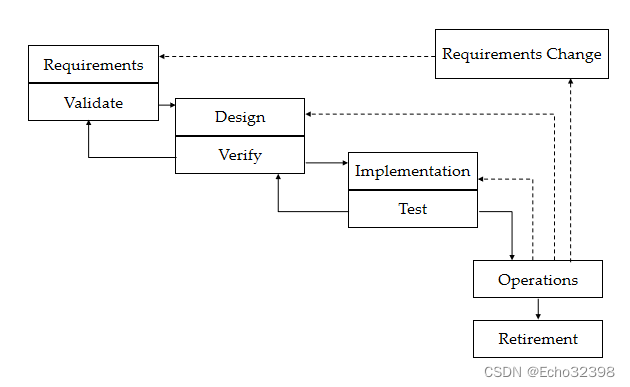
- Dr. Win Royce于70年代提出
- 广为流传和使用 (传说中的)
- 优点:1.开发进度易于掌握 2.过去开发中每个步骤的经验有助于对新的软件项目中类似步骤做出估计 3.每个阶段产生文档,有助于复用
- 最初的瀑布模型(被广为流传的)不允许迭代 (不灵活,不能处理需求的变化,难以维护)
快速模型
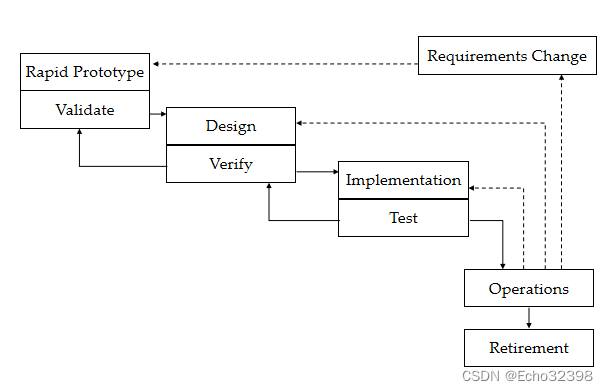
- 采用原型来帮助确定需求规范 一旦需求确定,就采用瀑布模型(或其他模型)
- 设计一旦开始,原型就不再需要:1.原型不可以作为实现的基础,因为原型工具产生的代码质量 2.用户必须被告知原型和最终产品的不同,原型并非80-90%的产品(也许不到10%)
渐增式模型
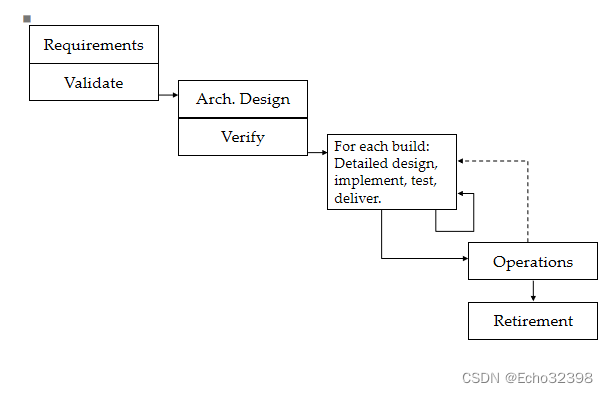
螺旋式模型
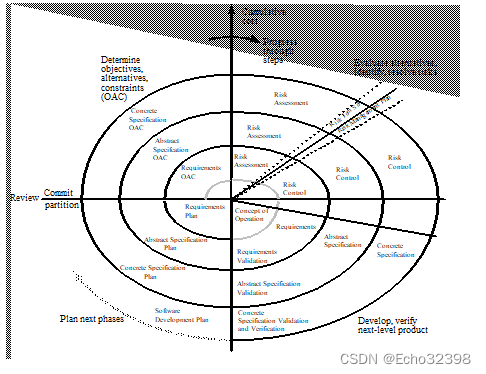
基于组件的开发模型
- 寻找Find 选择Select 调整Adapt 创建Create 组装Compose 替换Replace
考试习题可参考
(软件工程复习核心重点)第一章软件工程概论习题-CSDN博客