合肥网站建设多少钱2017主流网站风格
一、问题简介-
kt6368A蓝牙芯片无法透传 可能是什么问题呢?
KT6368A蓝牙芯片,在使用上还是非常的简单,总共也就8个腿,焊接也是很容易的事情
出现不能透传,大概率有如下2点原因
- 硬件问题,比如:没焊好,没供电,晶振没焊好、芯片坏掉了等等
- 软件问题,比如:测试app您不会用,不知道如何开启notify【发送数据至app的通道,也可以叫属性】等等
-
二、详细分析
2.1 芯片外围元器件
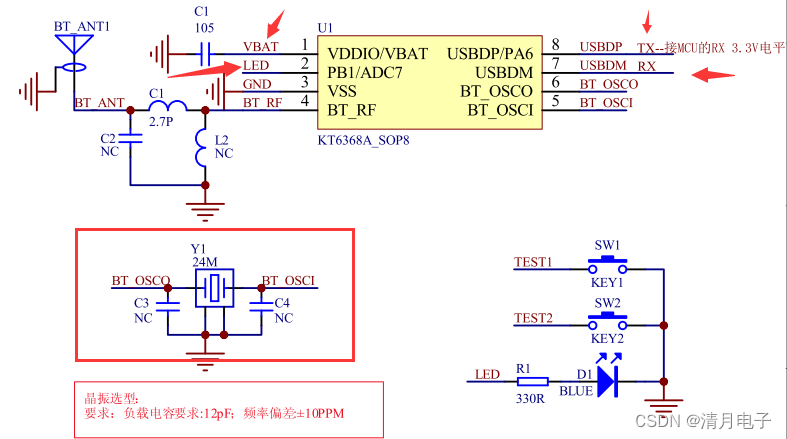
外围电路实在是没啥,一颗105电容,一个晶振搞掂,注意晶振是24M,10ppm 12pf的参数
- 再来说明这个问题,这里拿【KT6368A双模版本】来举例,万用表测试结果:3.3V供电
==》KT6368A的2脚也就是LED脚,上电是输出高电平3.3V ,1秒之后输出低电平0.002V
==》KT6368A的5脚晶振也就是BT-OSCI脚,正常起振是0.576V 。没有电压则是没有起振,不正常
==》KT6368A的6脚晶振也就是BT-OSCO脚,正常起振是0.532V 。没有电压则是没有起振,不正常
==》KT6368A的7脚也就是rx脚,正常是2.8V 。注意这个2.8v是芯片内置弱上拉
==》KT6368A的8脚也就是tx脚,正常是3.3V 。
2.2 APP的测试-安卓端

测试的话一定要善用工具,如上图所示,足够测试了
特别说明:ble的uuid我们是按照自己的标准,如果您用您以前的app,出现连不上,或者连上不能交互数据
这个是很正常的,因为uuid不一样,通讯的通道不一样
不懂,请问一下贵司的工程师,或者百度搜搜,这个是什么意思,因为几句话是讲不清楚的,属于的懂得自然懂,不懂的教不会
三、总结
KT6368A是相当简单的一款产品,使用起来应该是没任何问题才对,既然有问题,那么就好好的看一下芯片的手册,不急不躁认真核对一下,基本硬件问题居多