建设银行网站上改手机wordpress 导出数据
文章目录
- 一、变量命名
- 二、变量级别
- 三、.变量设定和使用方式
- 1.在playbook中直接定义变量
- 2.在文件中定义变量
- 3.使用变量
- 4.设定主机变量和清单变量
- 5.目录设定变量
- 6.用命令覆盖变量
- 7.使用数组设定变量
- 8.注册变量
- 9.事实变量
- 10.魔法变量
- 四、JINJA2模板
- 五、 Ansible的加密控制
- 练习
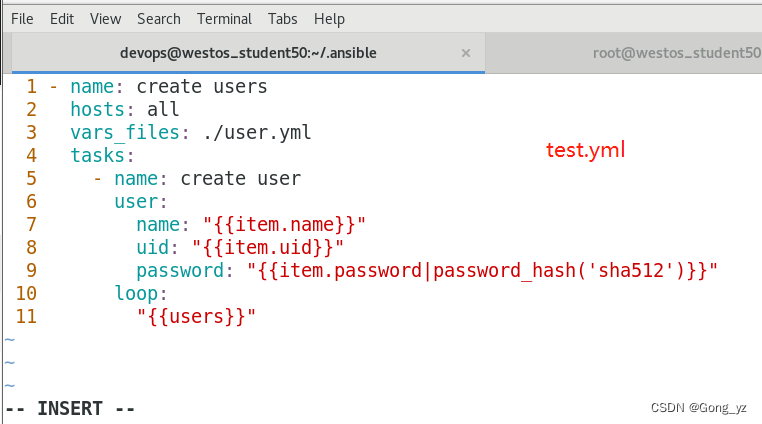
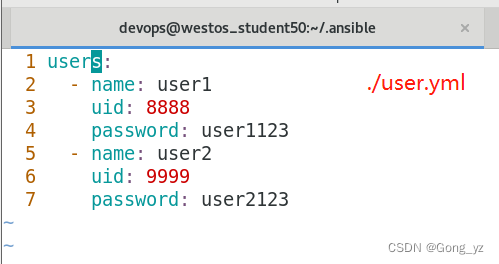
- 1.用变量指定用户的各项信息:name,uid,password等
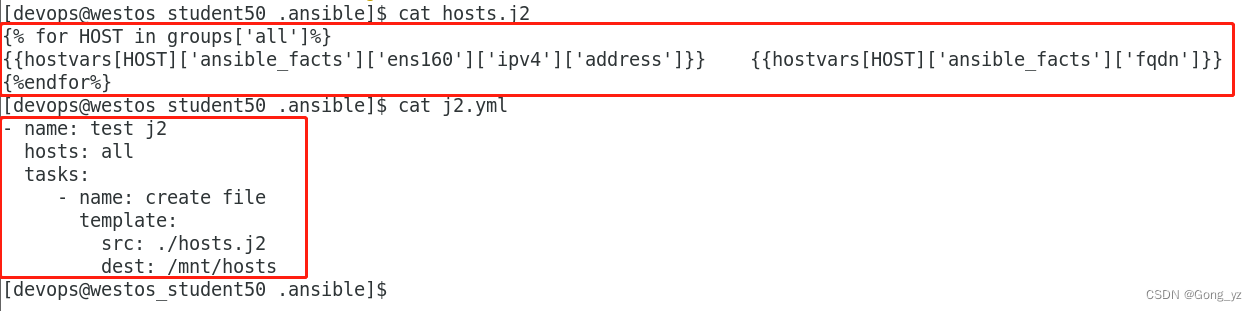
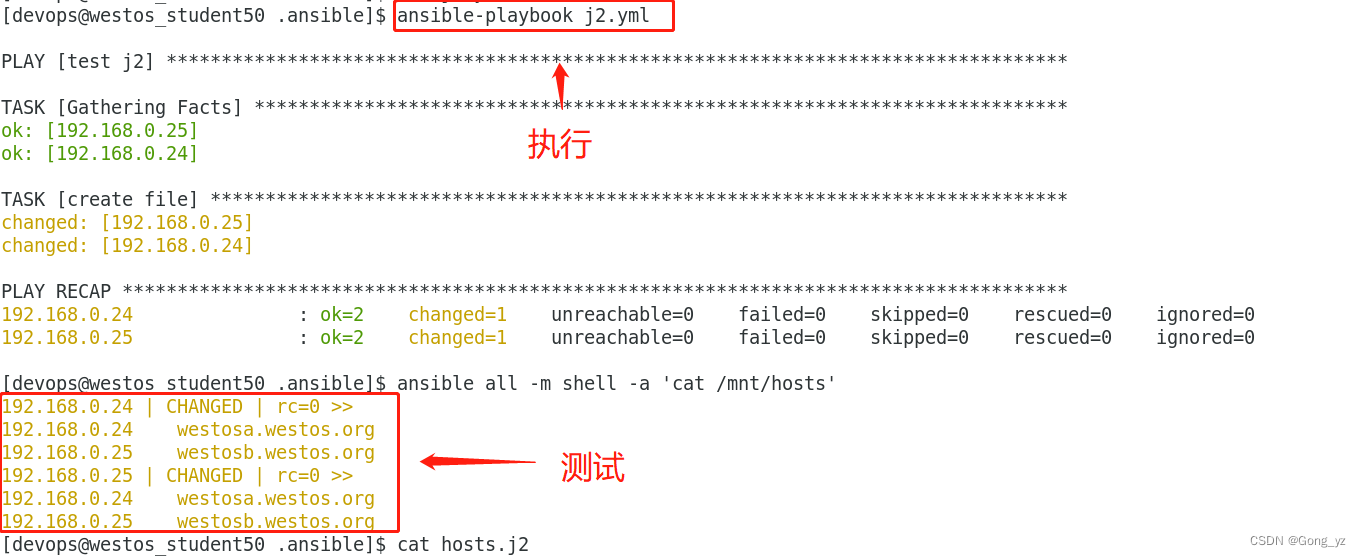
- 2.事实变量:在受控主机的生成/mnt/hosts文件,包括ip和主机名
- 3.使用JINJA2在/mnt/hosts中生成ip和主机名
一、变量命名
只能包含数字,下划线,字母
只能用下划线或字母开头
二、变量级别
全局: 从命令行或配置文件中设定的
paly: 在play和相关结构中设定的
主机: 由清单,事实收集或注册的任务变量优先级设定:
狭窄范围优先于广域范围,即paly>主机>全局
三、.变量设定和使用方式
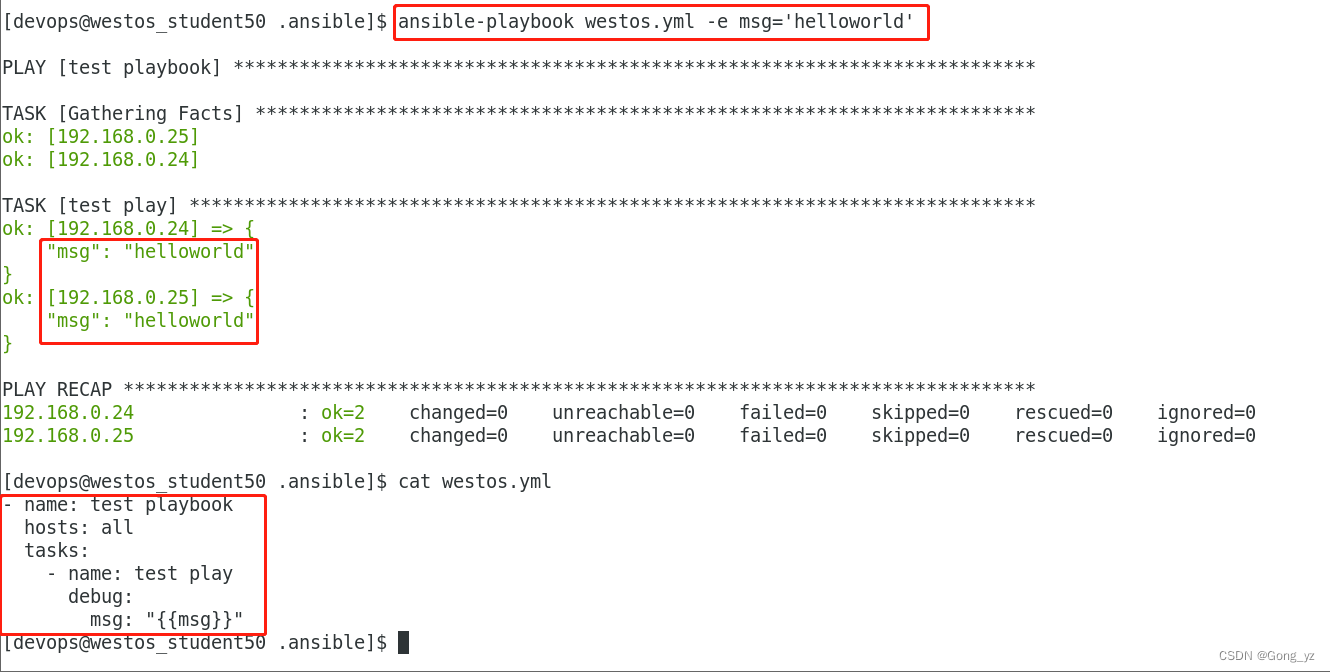
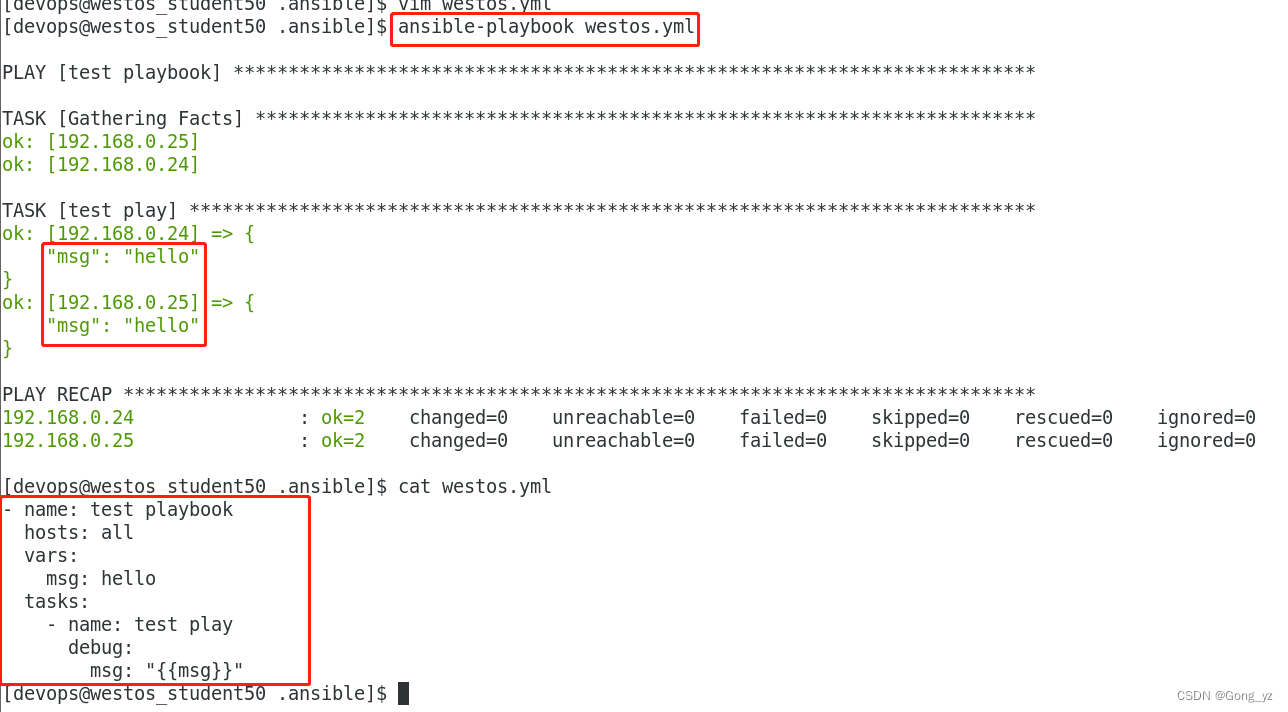
1.在playbook中直接定义变量
---
- name: test varhosts: allvars:USER: westosuser
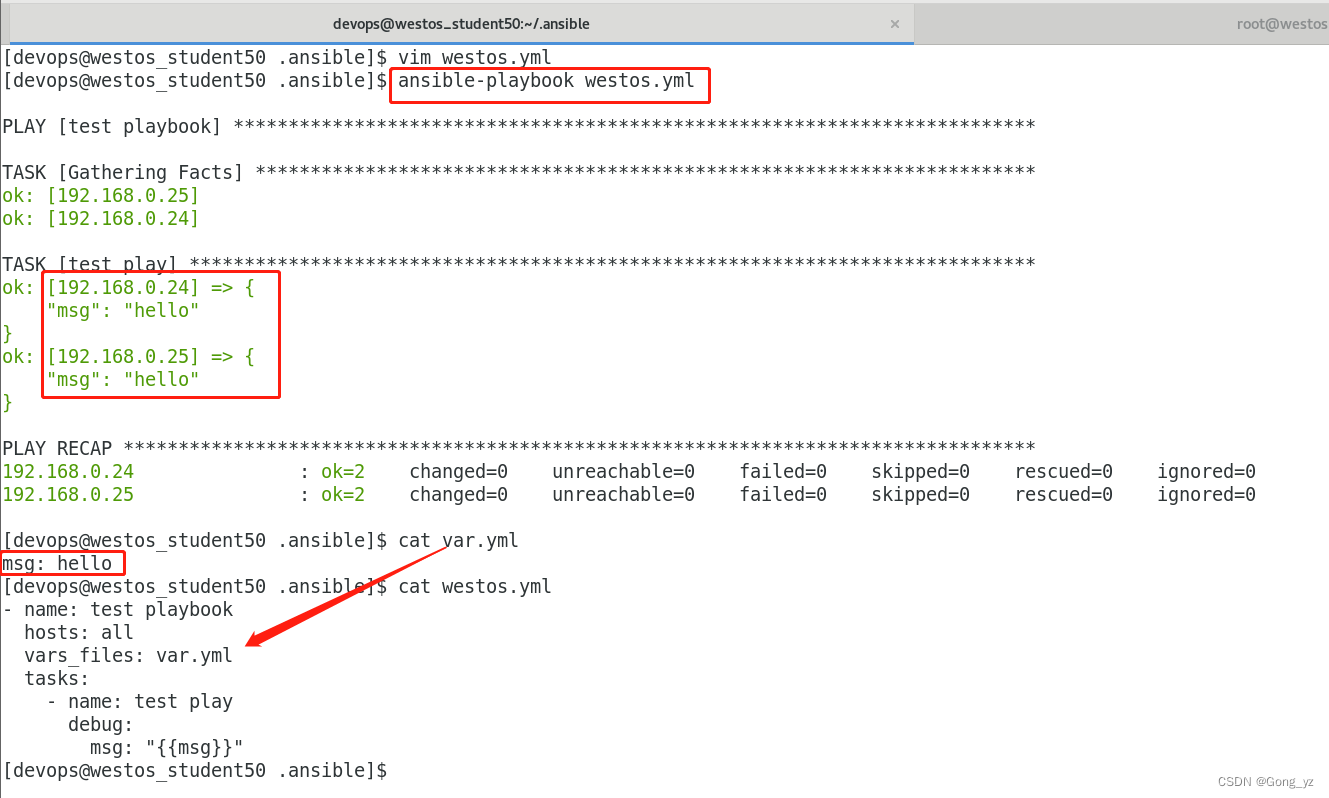
2.在文件中定义变量
vim user_list.yml
---
user: westosuservim westos.yml
---
- name: Create Userhosts: allvars_files:- ./user_list.yml
3.使用变量
tasks:- name: create useruser:name: "{{ USER }}"
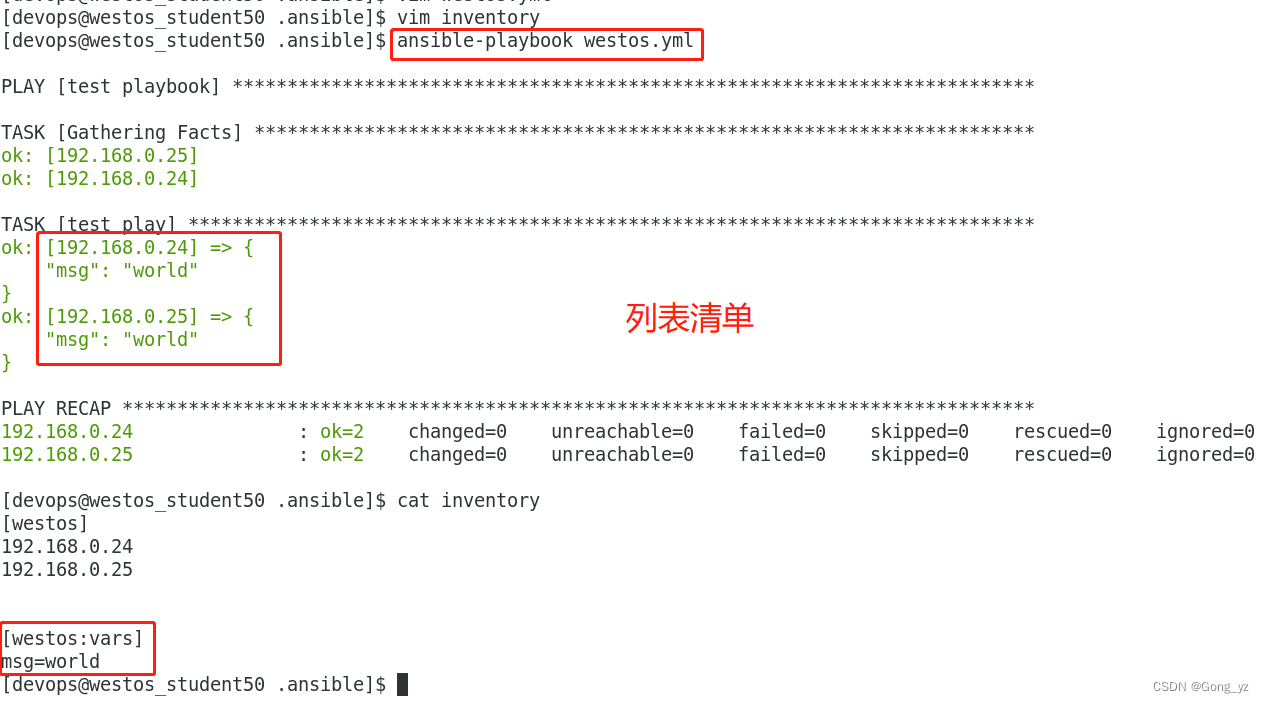
4.设定主机变量和清单变量
在定义主机变量和清单变量时使用
vim inventory
[westos_list1]
172.25.0.254
172.25.0.1
[westos_list2]
172.25.0.2
[westos_list3]
172.25.0.3
[westos_group:children]
westos_list2
westos_list3
[westos_list1:vars]
USER=westos1
[westos_group:vars]
USER=westos2

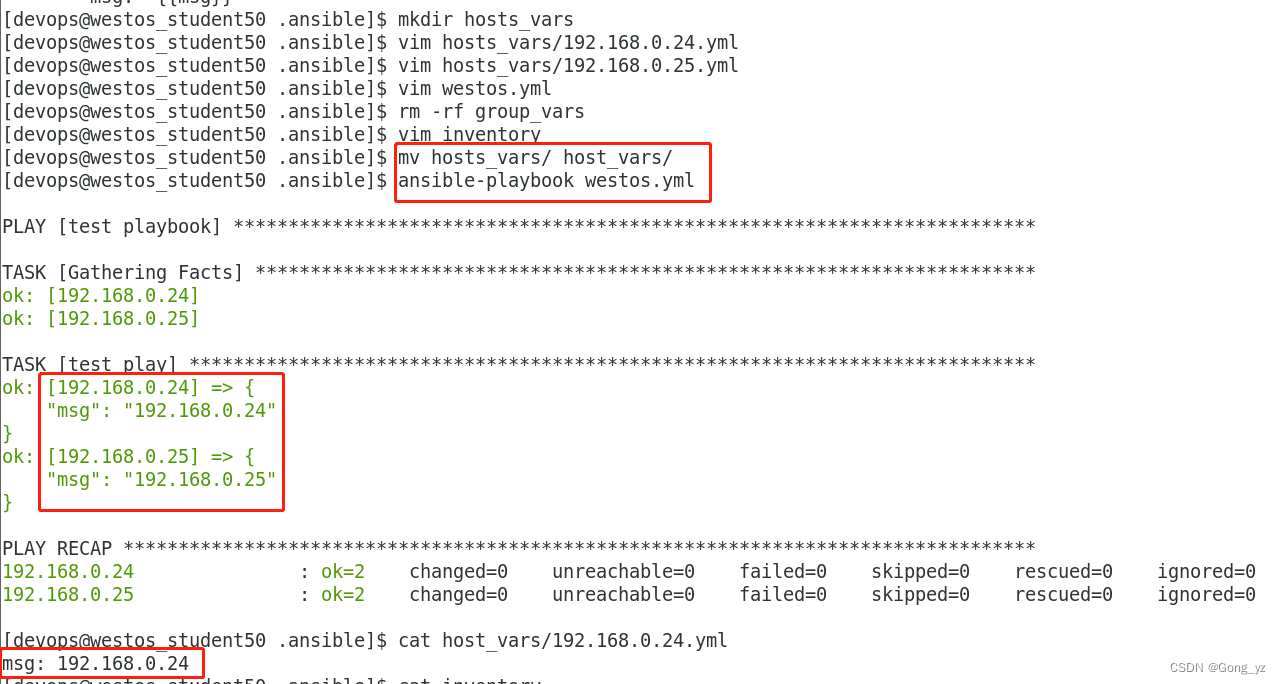
5.目录设定变量
group_vars ##清单变量,目录中的文件名称与主机清单名称一致
host_vars ##主机变量,目录中的文件名称与主机名称一致
1.group_vars ##清单变量,目录中的文件名称与主机清单名称一致

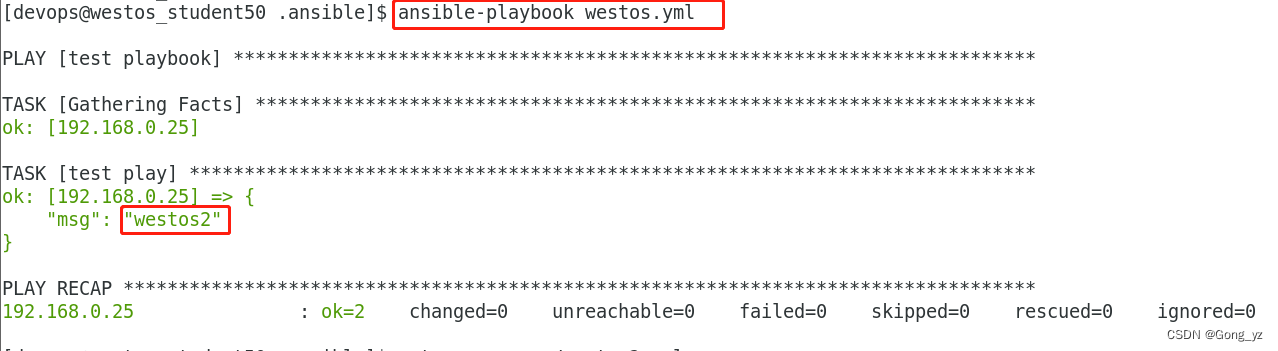
2.host_vars ##主机变量,目录中的文件名称与主机名称一致
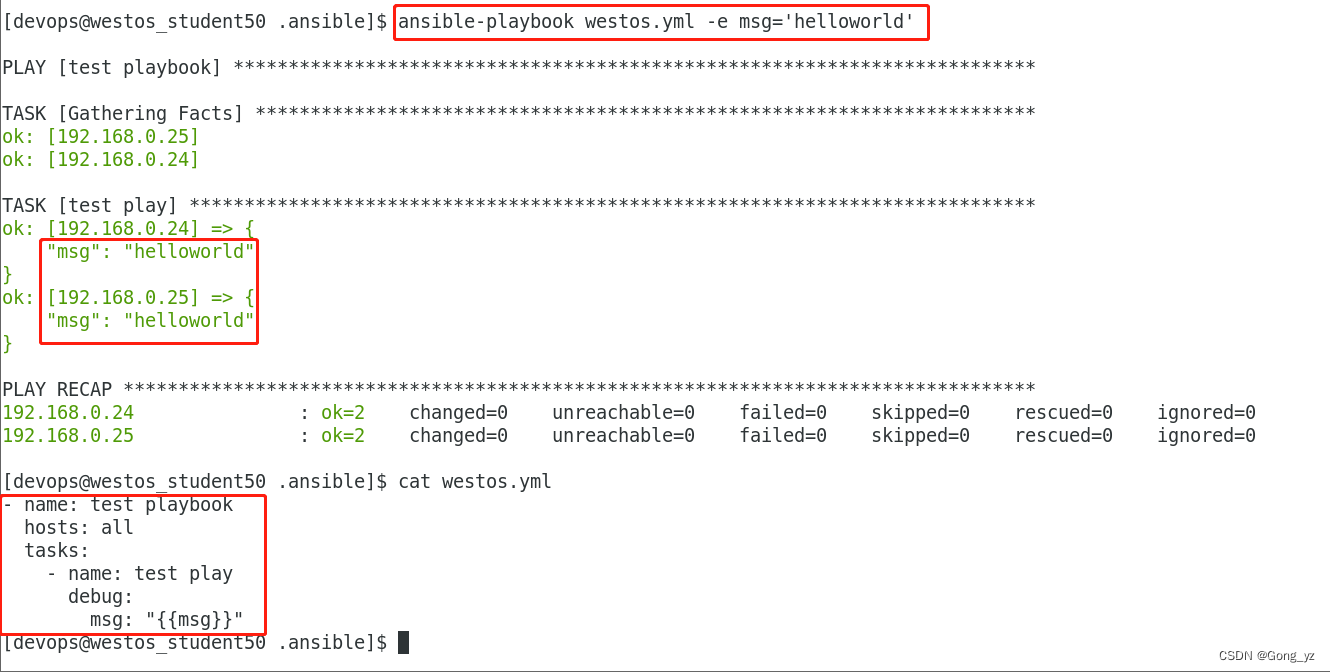
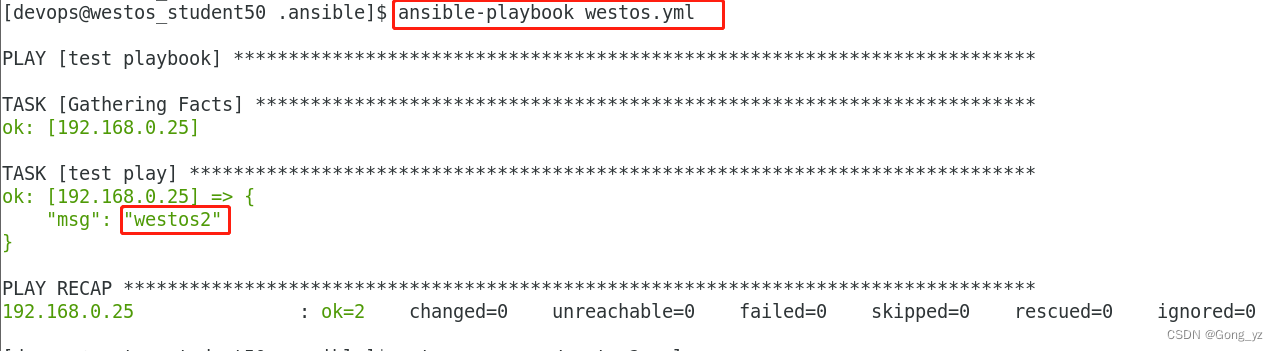
6.用命令覆盖变量
ansible-playbook user.yml -e "USER=hello"
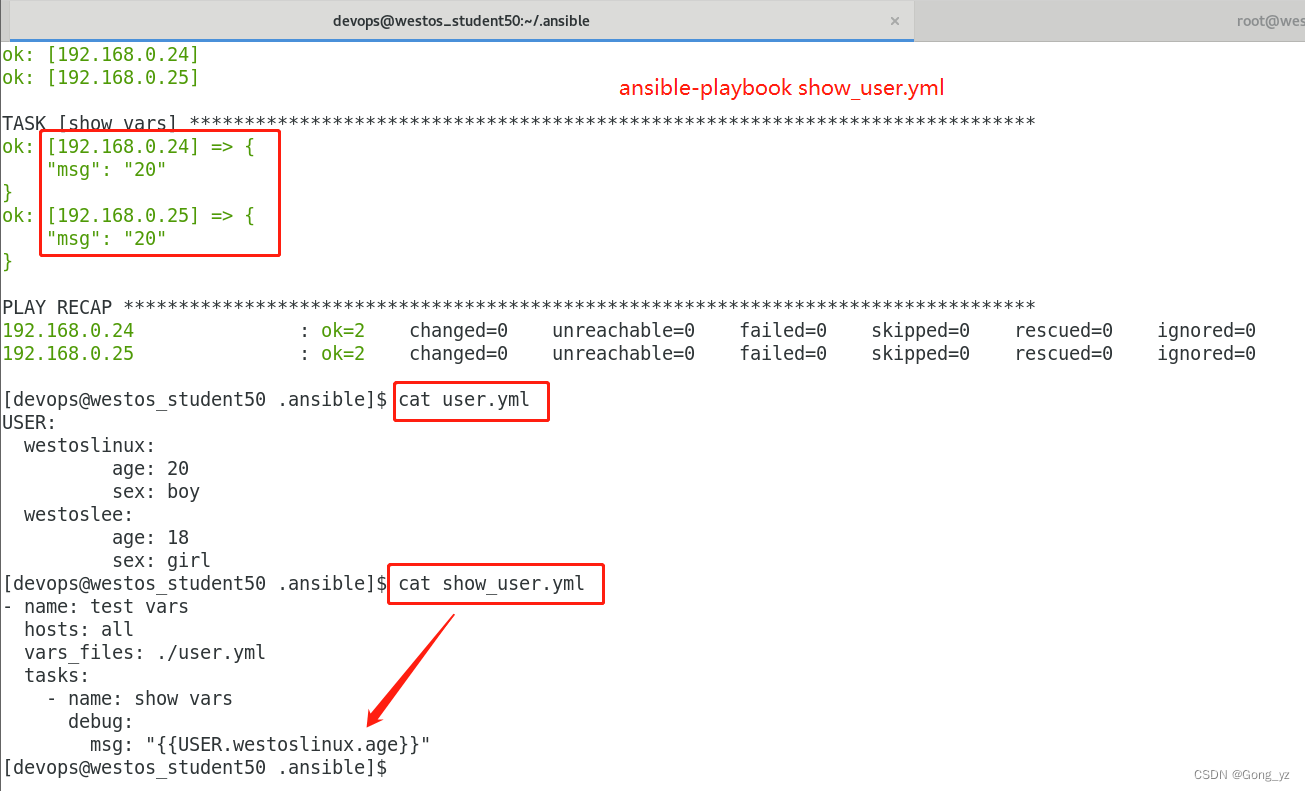
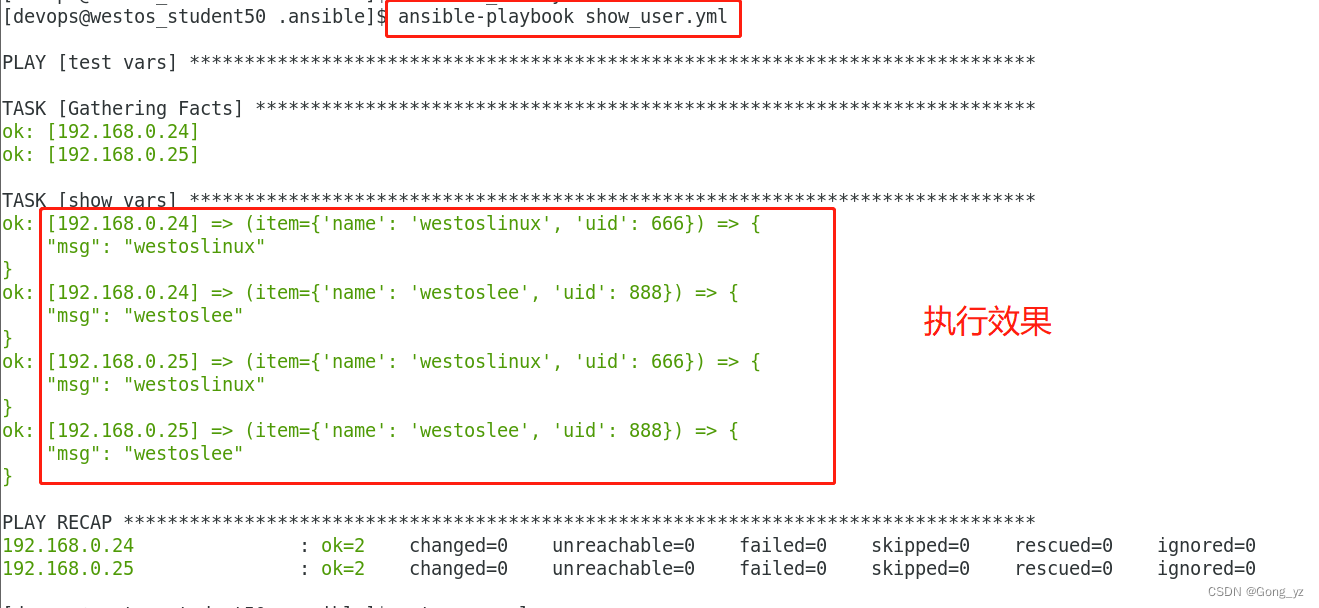
7.使用数组设定变量
vim user_var.yml
---
USER:lee:age: 18obj: linuxwestos:age: 20obj: java#vim user.yml
- name: Create Userhosts: allgather_facts: novars_files:./user_var.ymltasks:- name: create usershell:echo "{{USER['lee']['age']}}"echo "{{USER.westos.obj}}"create web vhost
www.westos.com 80 ------ > /var/www/html ------> www.westos.com
linux.westos.com 80 ------> /var/www/virtual/westos.com/linux -----> linux.westos.com

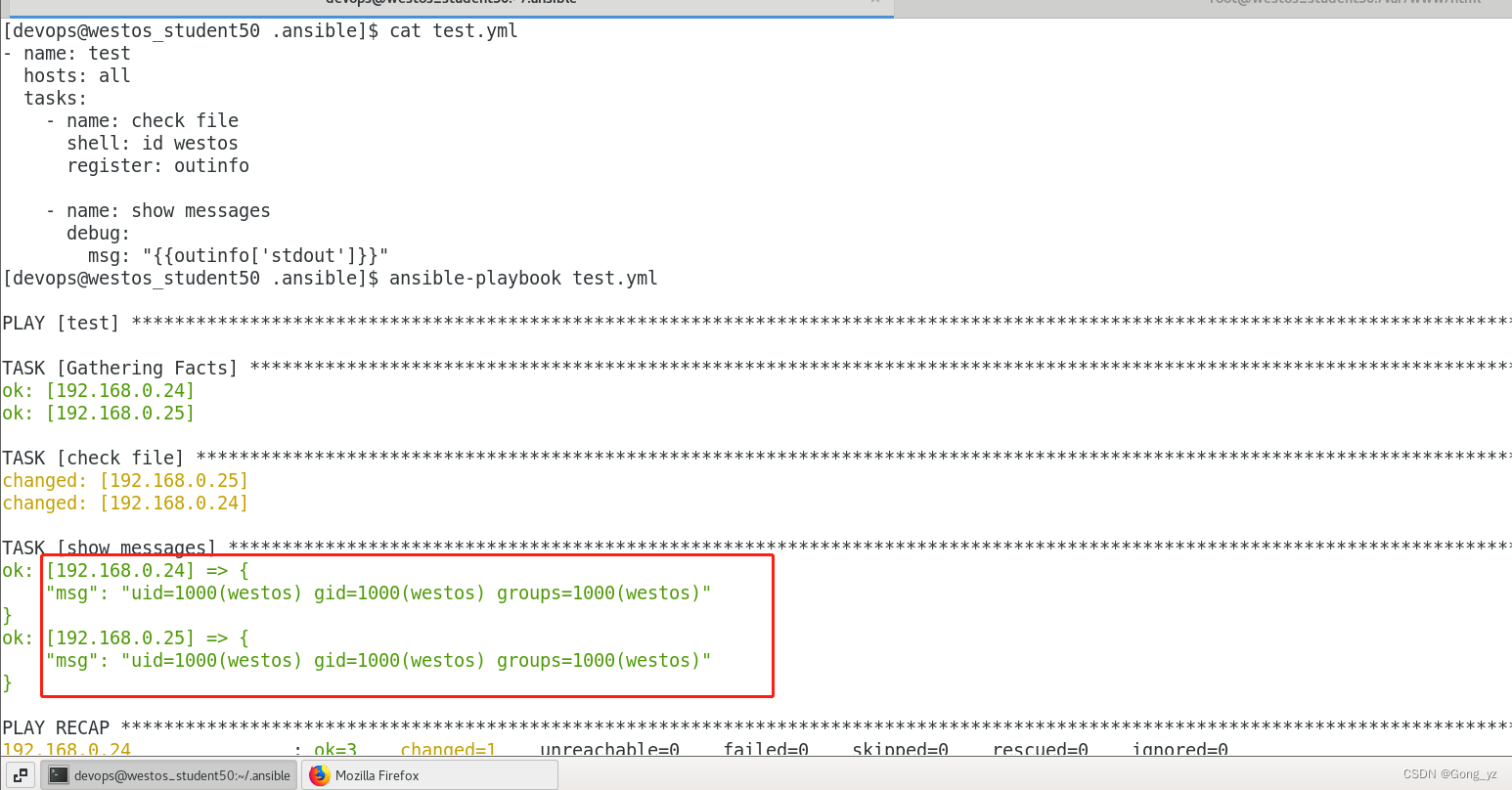
8.注册变量
#register 把模块输出注册到指定字符串中
---
- name: test registerhosts: 172.25.0.254tasks:- name: hostname commandshell:hostnameregister: info- name: show messagesshell:echo "{{info['stdout']}}"
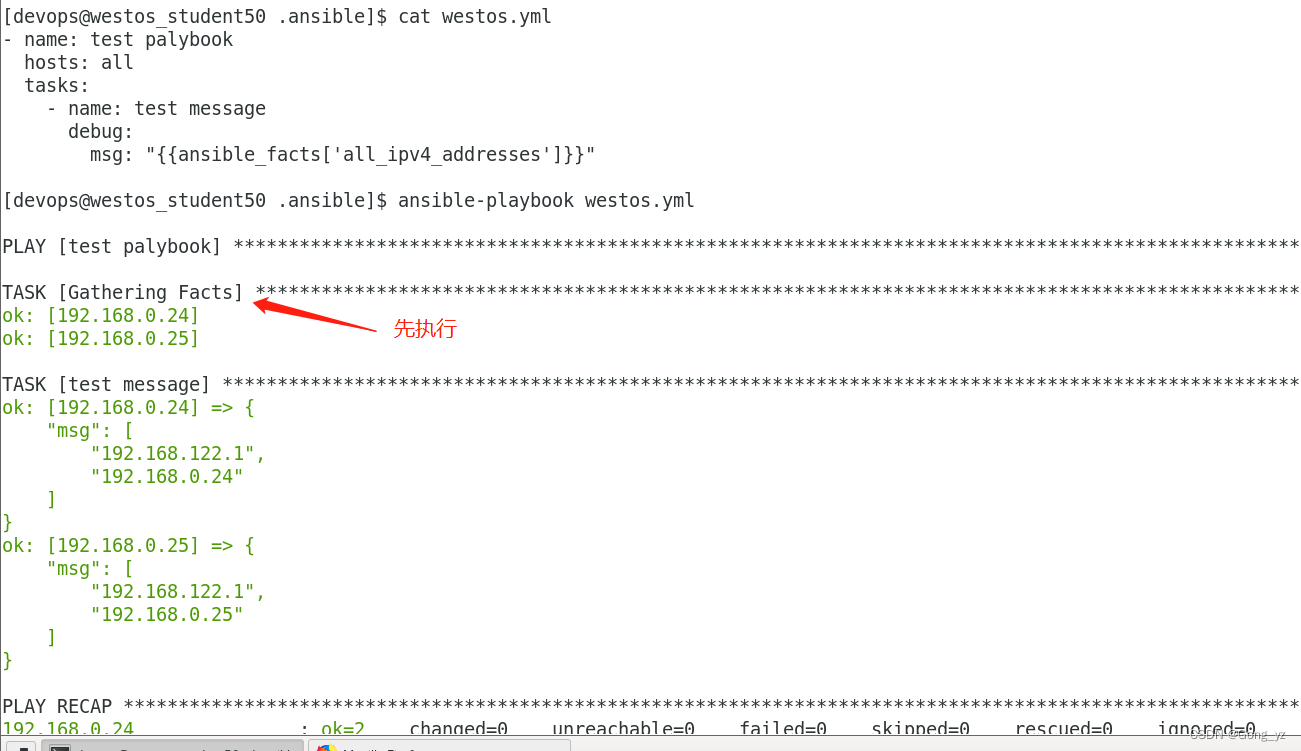
9.事实变量
事实变量是ansible在受控主机中自动检测出的变量
事实变量中还有与主机相关的信息
当需要使用主机相关信息时不需要采集赋值,直接调用即可
因为变量信息为系统信息所以不能随意设定仅为采集信息,故被成为事实变量
---
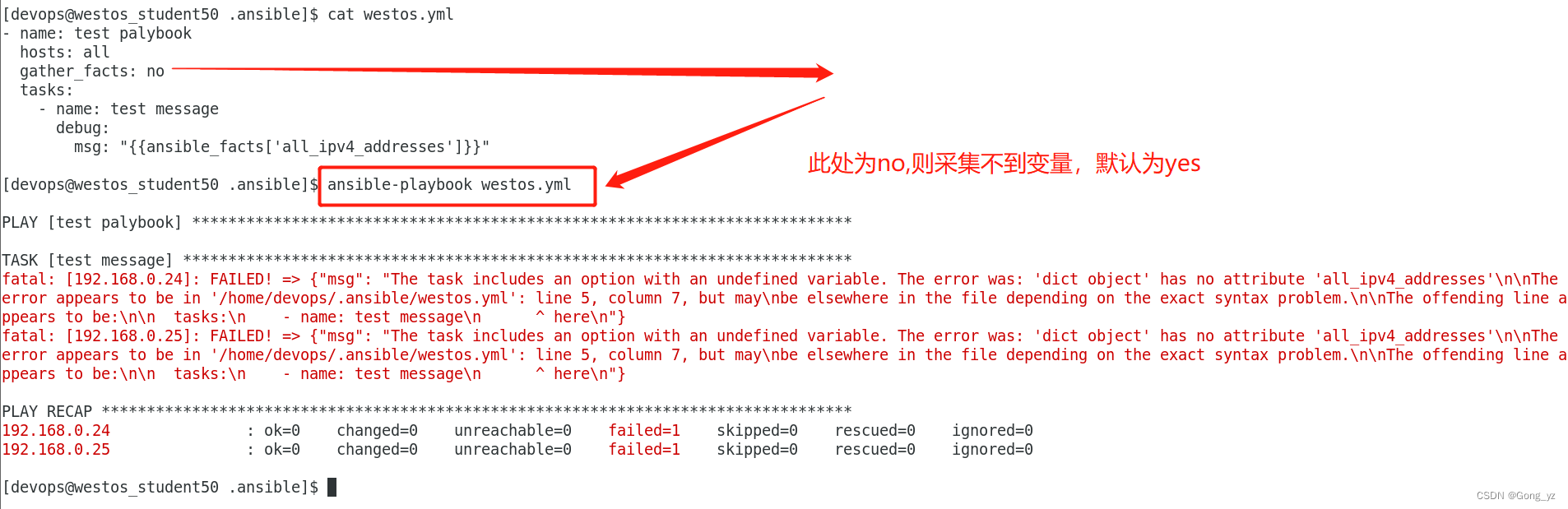
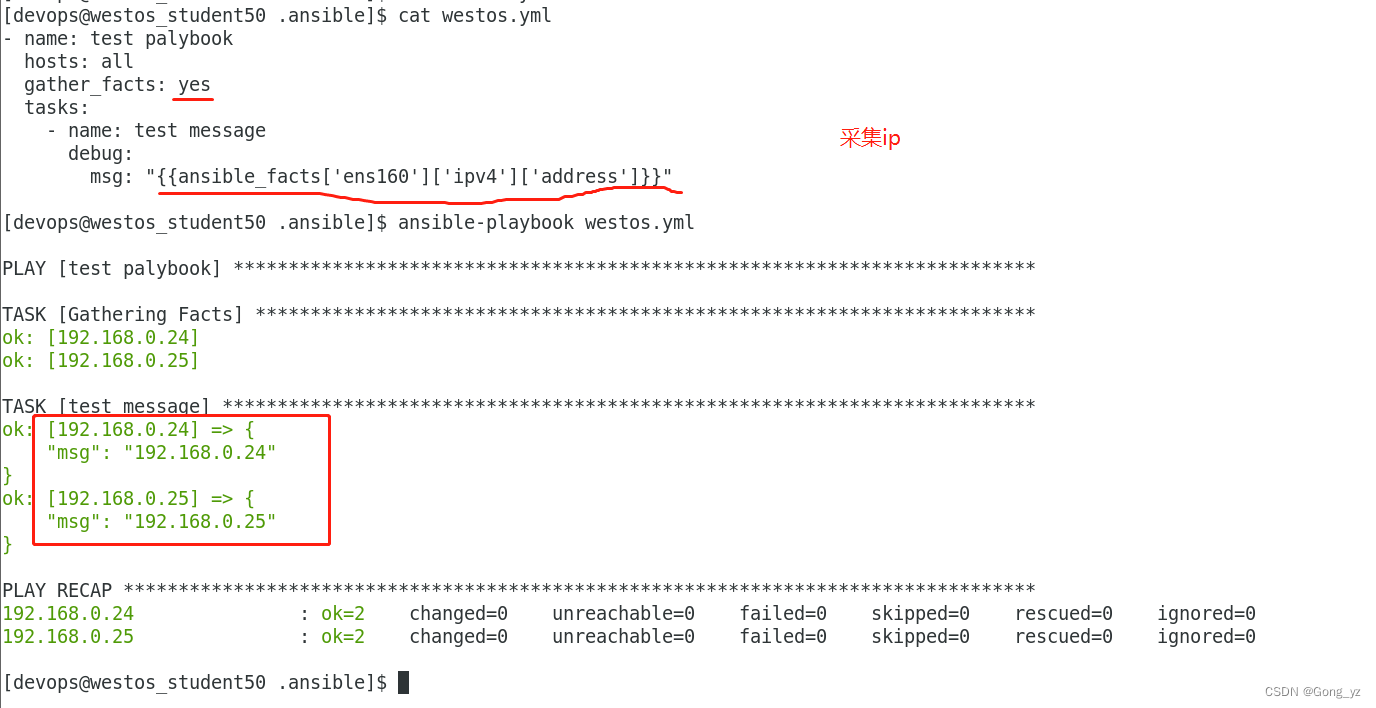
- name: test registerhosts: 172.25.0.254tasks:- name: show messagesdebug:msg: "{{ansible_facts['architecture']}}"gather_facts: no ##在playbook中关闭事实变量收集


10.魔法变量
hostvars: ##ansible软件的内部信息
#eg:
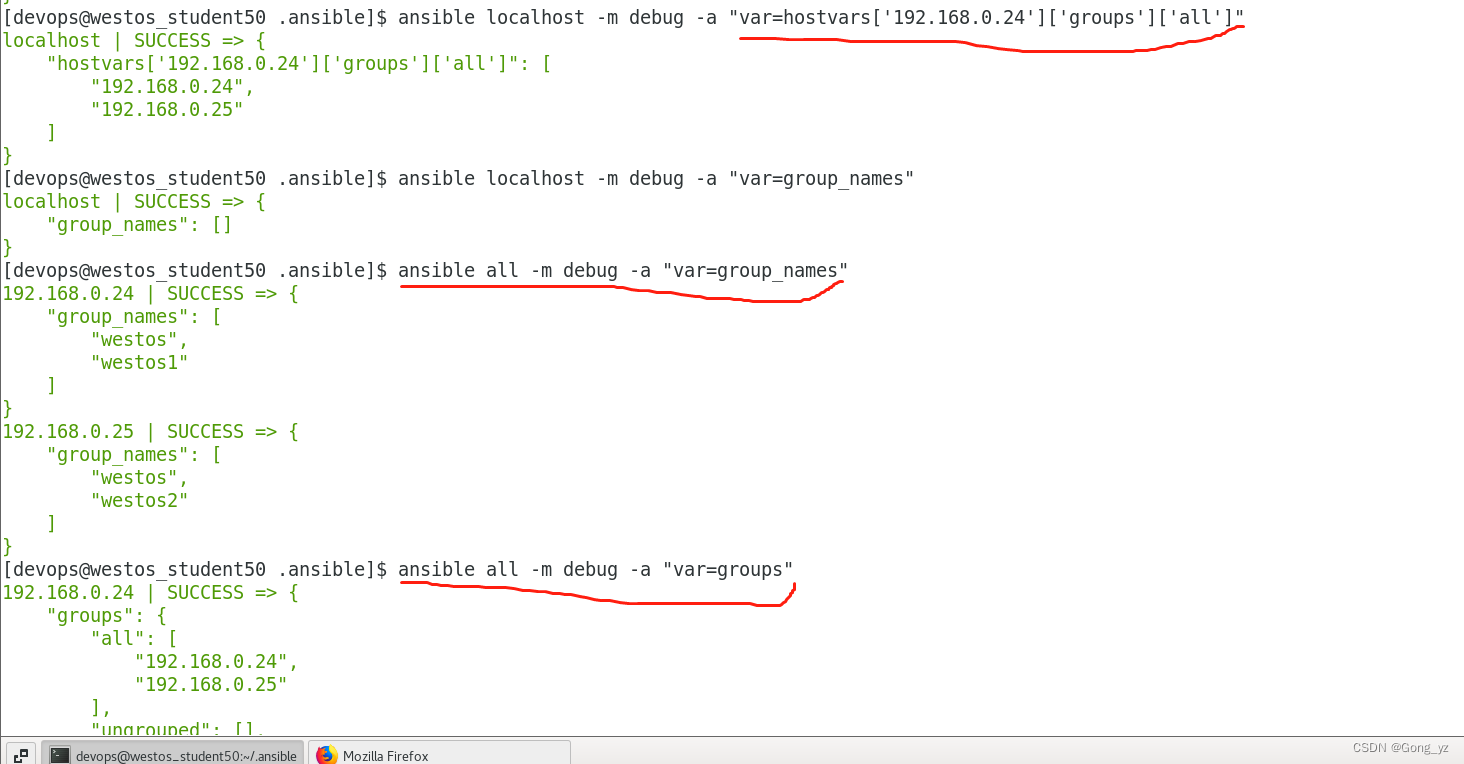
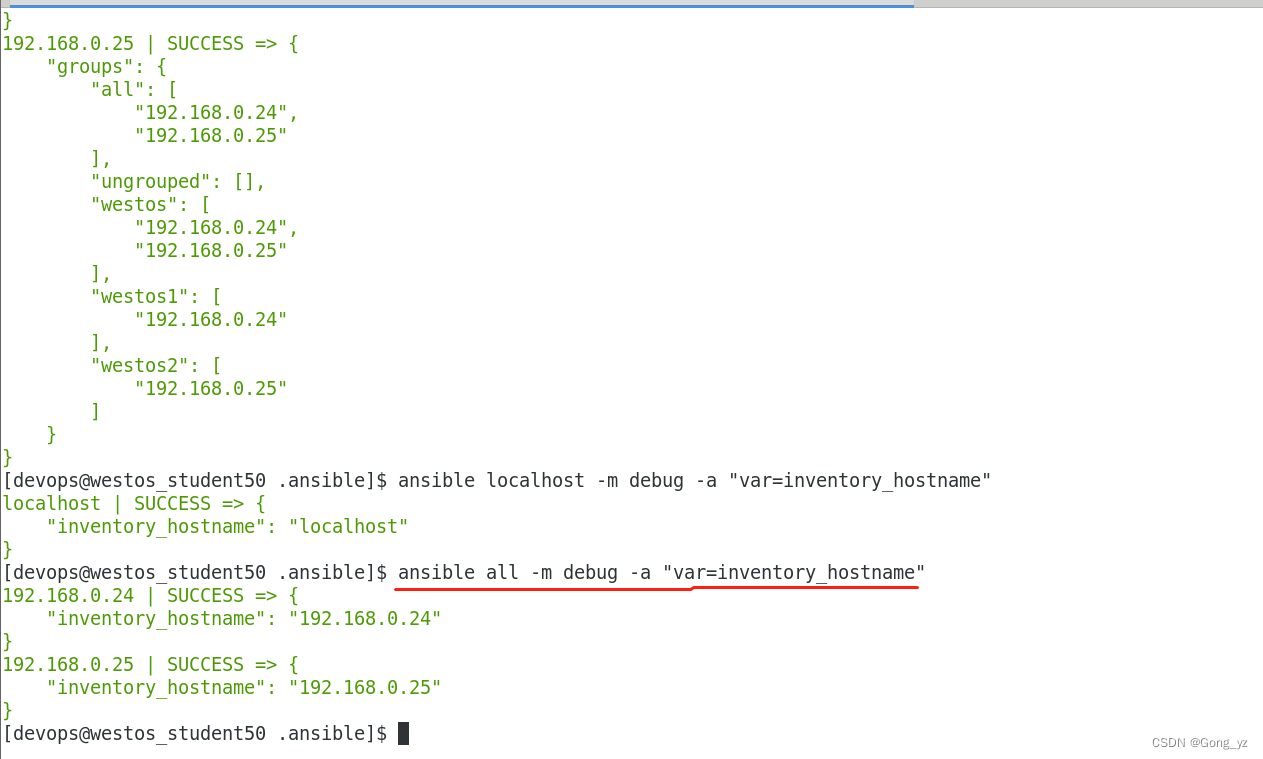
ansible localhost -m debug -a "var=hostvars"group_names: ##当前受管主机所在组
#eg:
ansible localhost -m debug -a "var=group_names"groups: ##列出清单中所有的组和主机
#eg:
ansible localhost -m debug -a "var=groups"inventory_hostname: ##包含清单中配置的当前授管主机的名称
#eg:
ansible localhost -m debug -a "var=inventory_hostname"
四、JINJA2模板
1.介绍
Jinja2是Python下一个被广泛应用的模版引擎
他的设计思想来源于Django的模板引擎,
并扩展了其语法和一系列强大的功能。
其中最显著的一个是增加了沙箱执行功能和可选的自动转义功能
相当于在Python中做了一个环境去运行,从而不影响其他的设定
2.j2模板书写规则
{# /etc/hosts line #} ##注释说明文件用途
127.0.0.1 localhost ##文件内容
{{ ansible_facts['all_ipv4_addresses'] }} {{ansible_facts['fqdn']}} ##使用事实变量

3.for循环
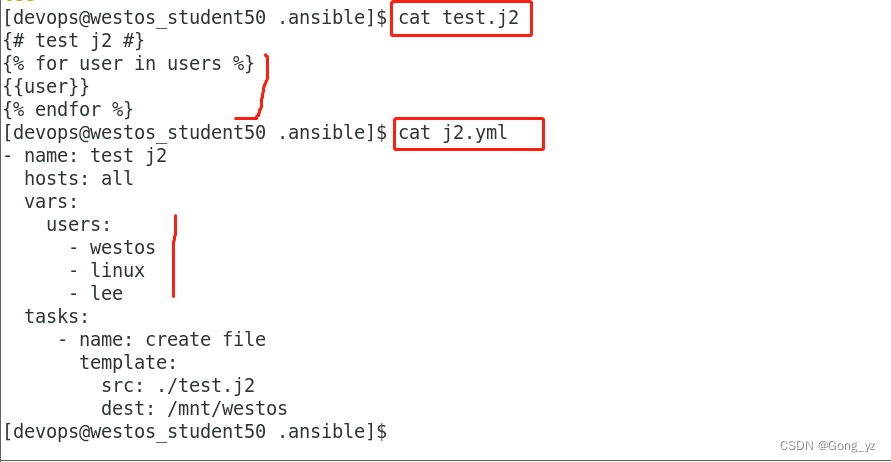
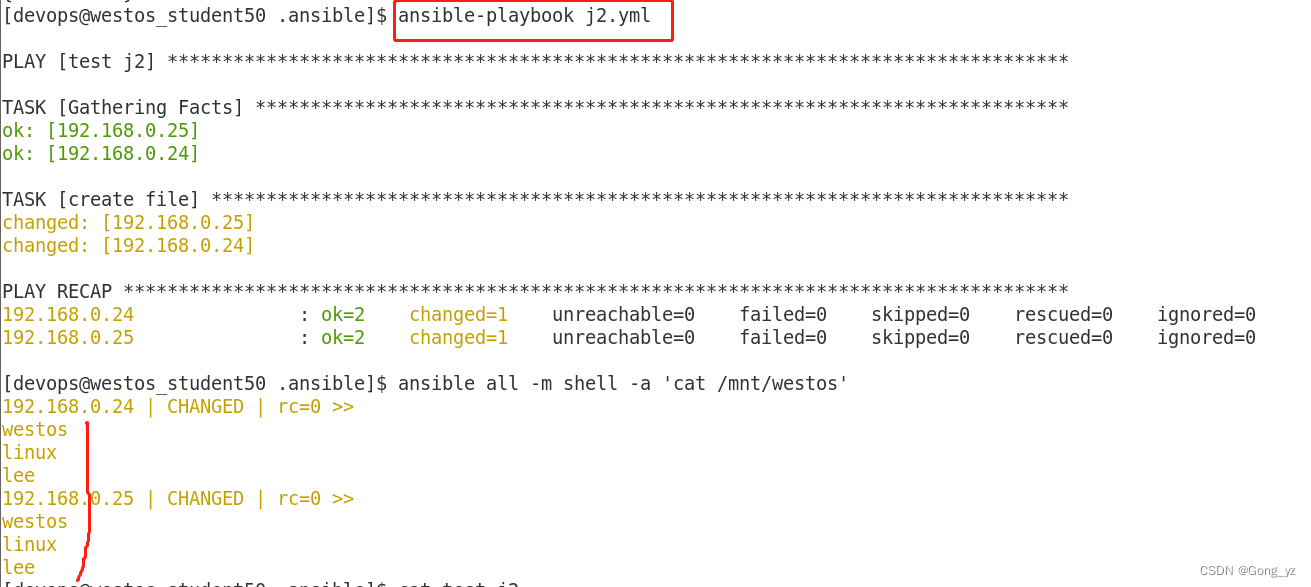
vim users.yml
users:- westos- linux- ansiblevim test.j2
{% for NAME in users %}
{{ NAME }}
{%endfor%}
4.if 判定
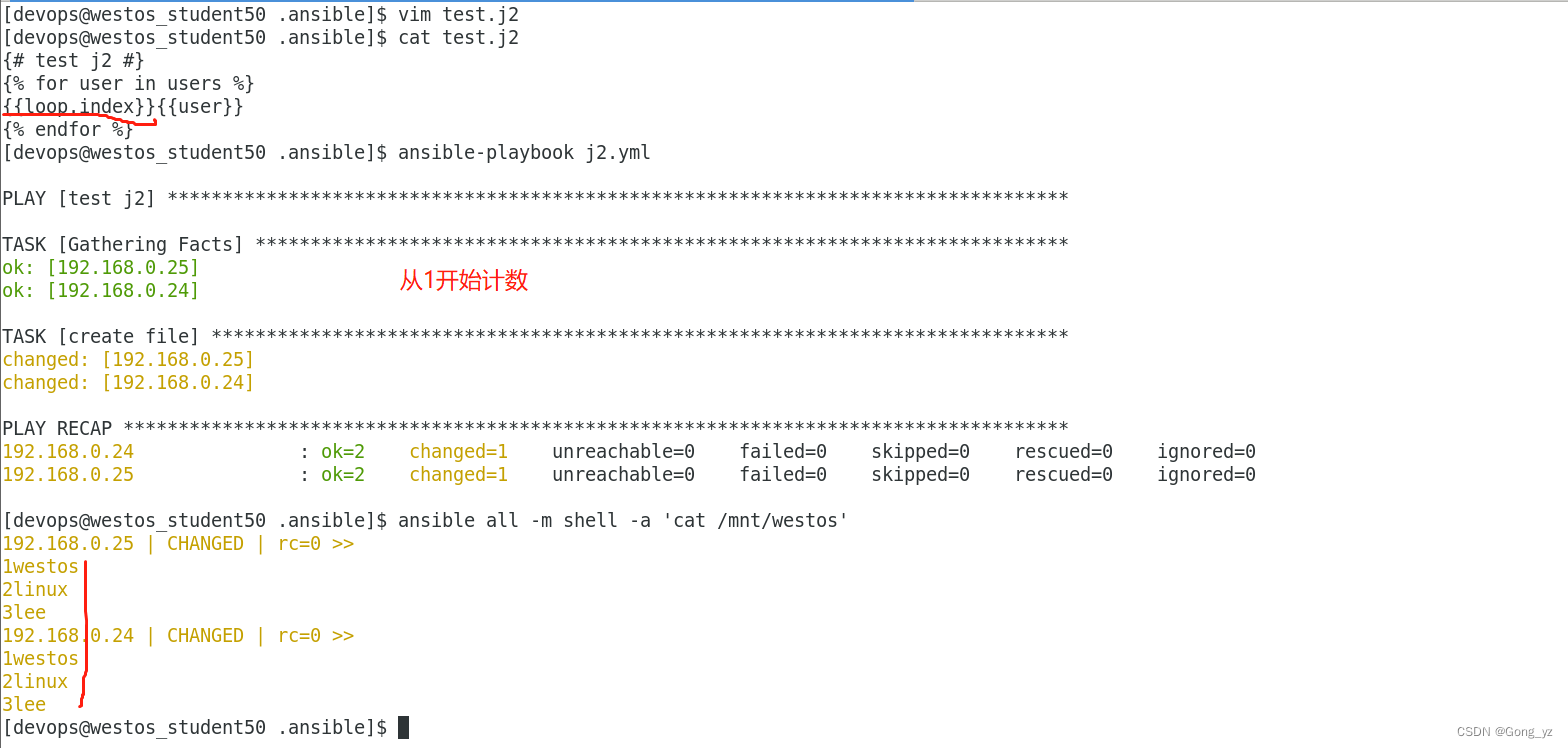
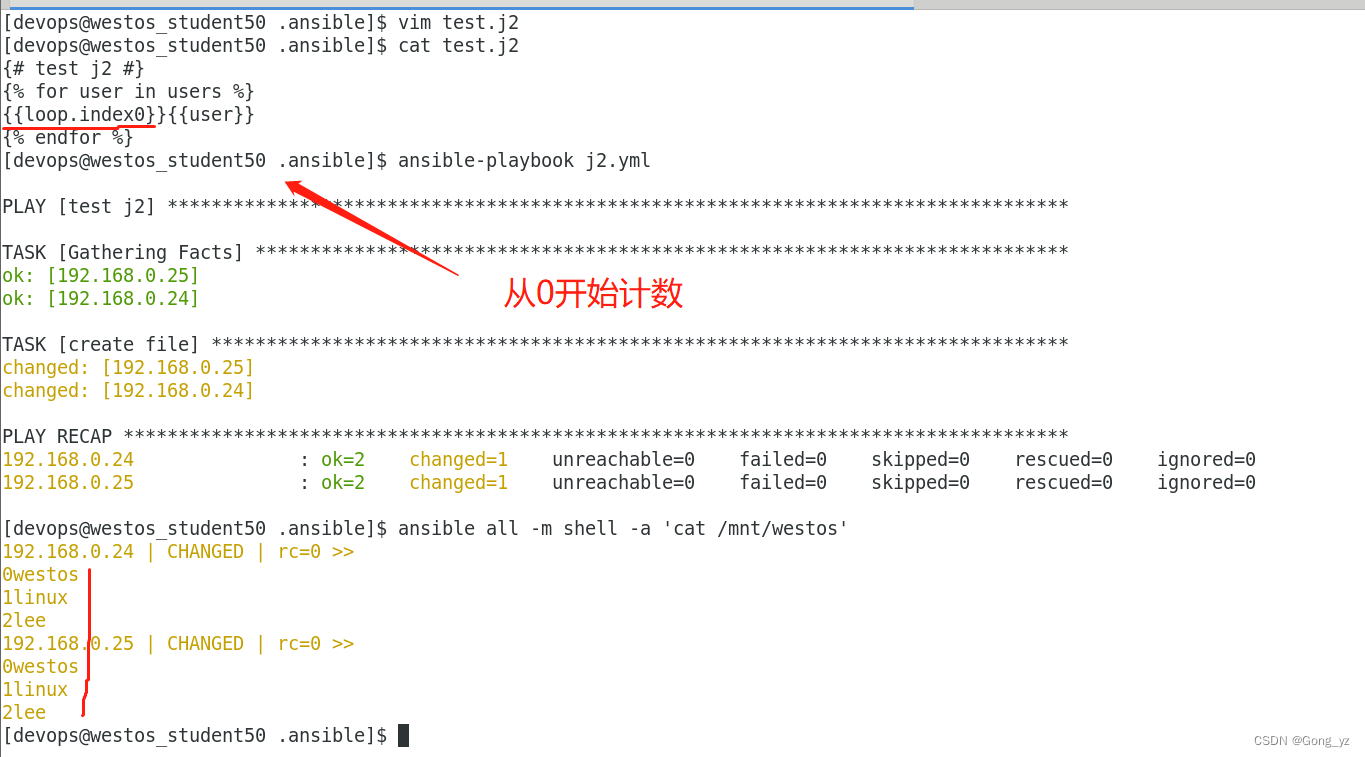
{% for NAME in users if not NAME == "ansible" %}
User number {{loop.index}} - {{ NAME }}
{%endfor%}loop.index ##循环迭代记数从1开始
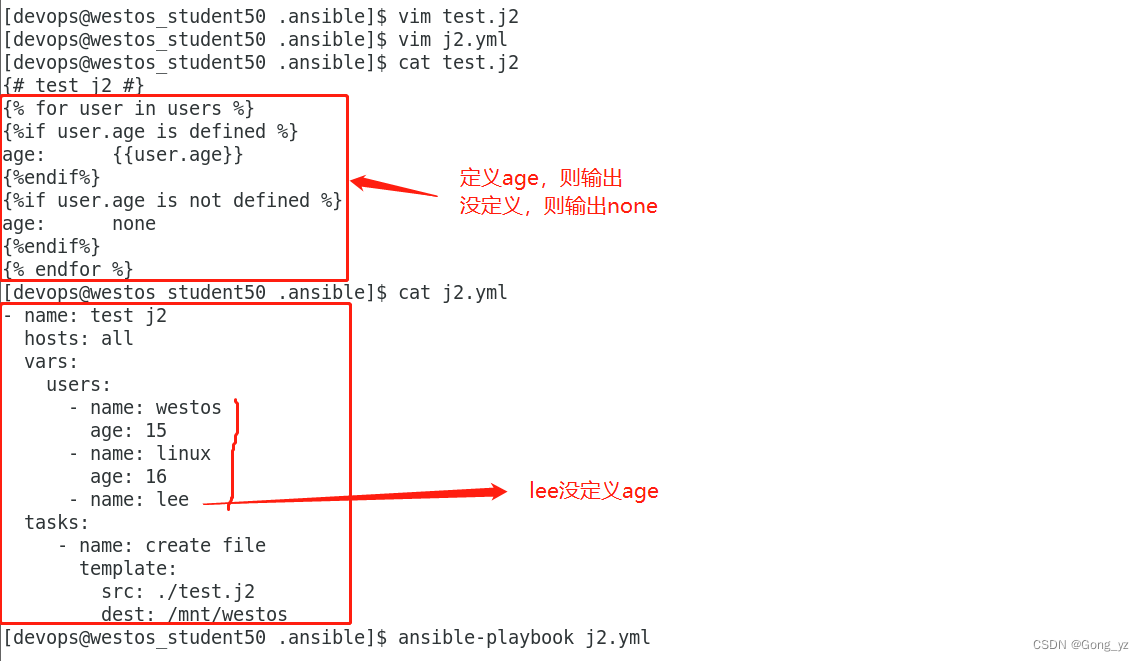
loop.index0 ##循环迭代计数从0开始{% for user in students %}
name: {{user['name']}}
{%if user['age'] is defined%}
age: {{user['age']}}
{%endif%}
{% if user['age'] is not defined %}
age: null
{% endif%}
obj: {{user['obj']}}
{%endfor%}


5.#j2模板在playbook中的应用
#playbook1
---
- name: test registerhosts: xxxxtasks:- name: create hoststemplate:src: ./xxxx.j2dest: /mnt/hosts
#playbook2
---
- name: test.j2hosts: 172.25.0.254vars:students:- name: student1obj: linux- name: student2age: 18obj: linuxtasks:- template:src: ./test.j2dest: /mnt/list
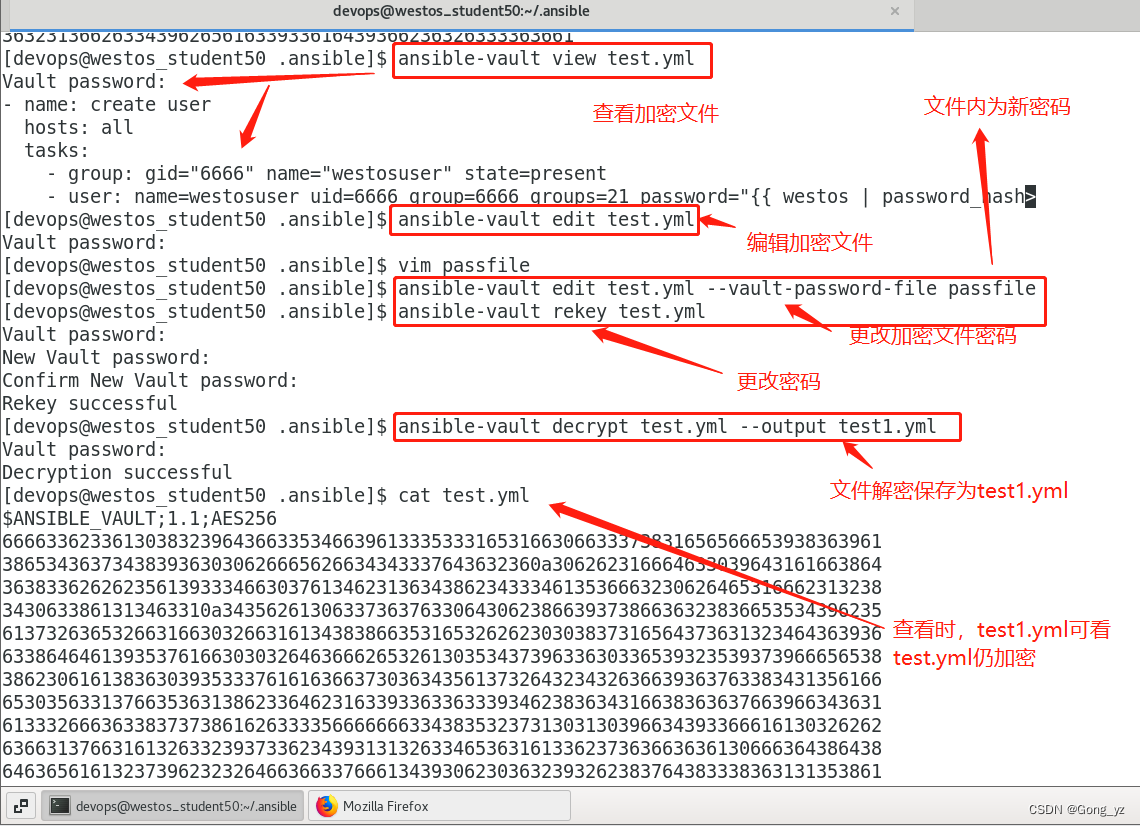
五、 Ansible的加密控制
#创建建立文件
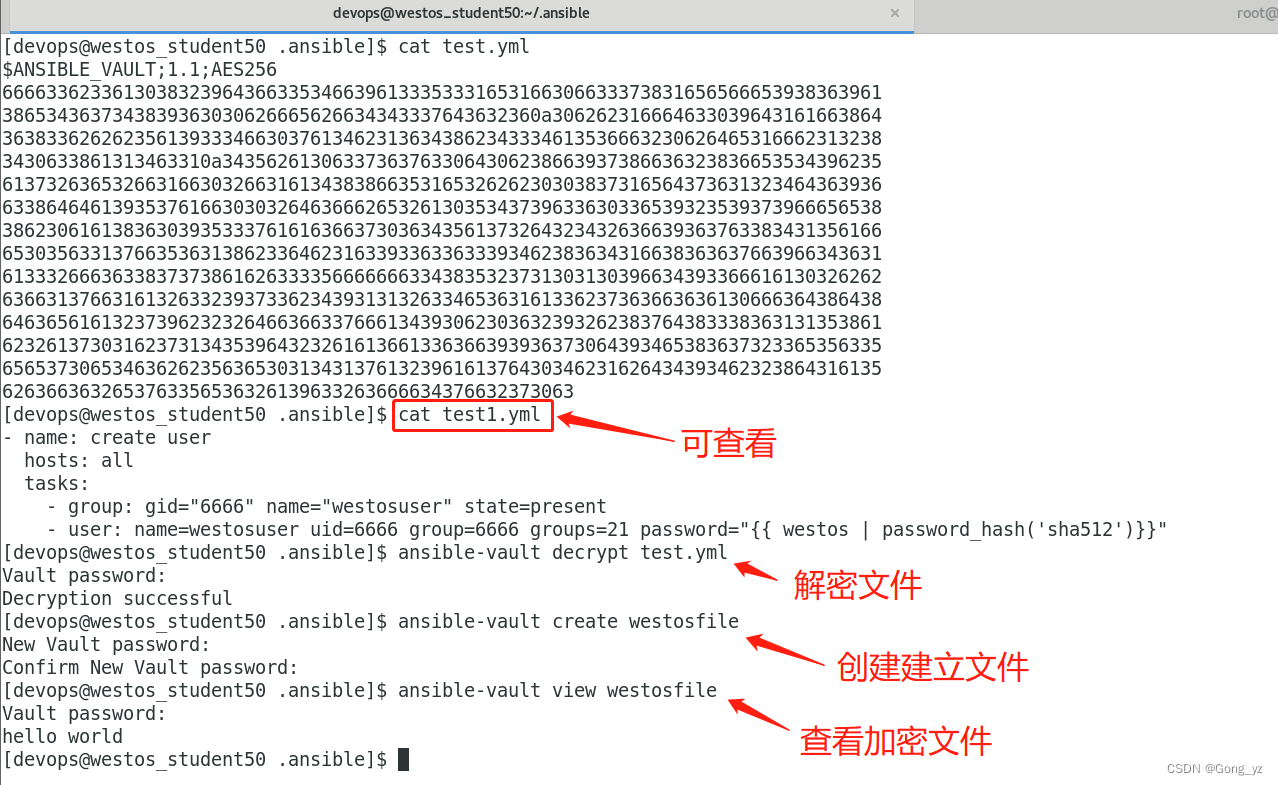
1.ansible-vault create westos
2.vim westos-vault
lee
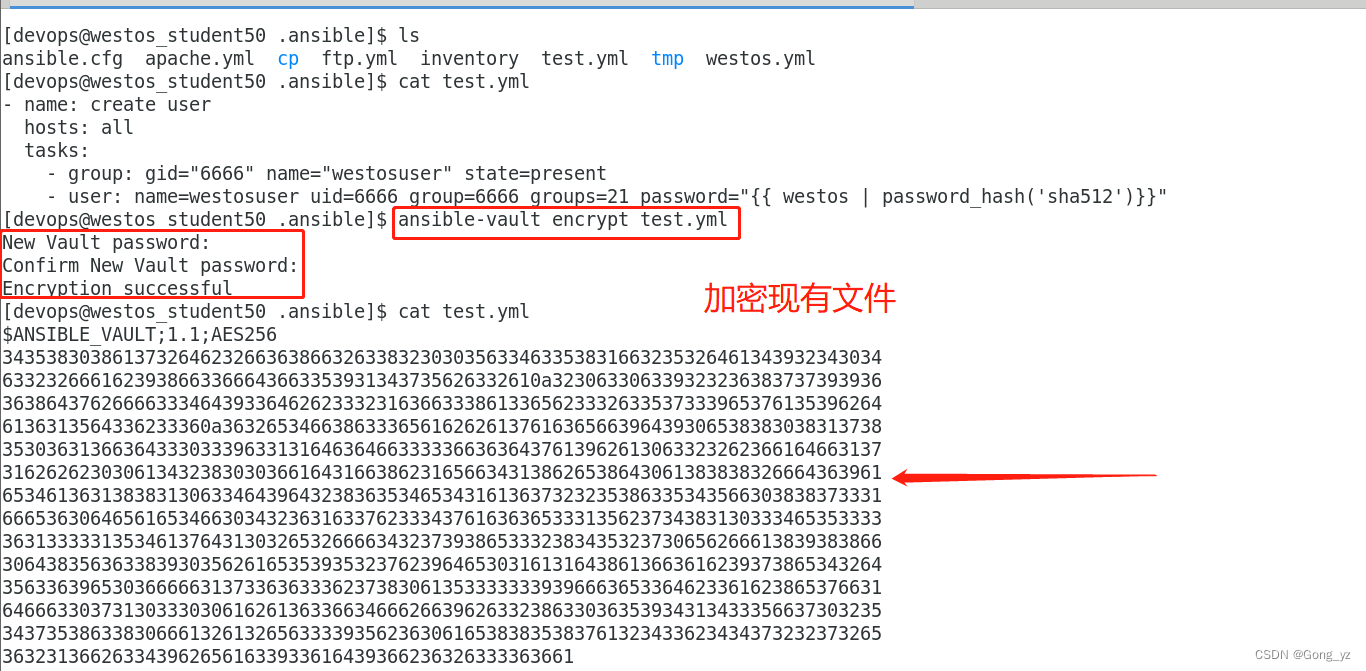
ansible-vault create --vault-password-file=westos-valut westos#加密现有文件
ansible-vault encrypt test#查看加密文件
ansible-vault view westos
ansible-vault view --vault-password-file=westos-valut westos#编辑加密文件
ansible-vault edit westos1
ansible-vault edit --vault-password-file=westos-valut westos##解密文件
ansible-vault decrypt westos ##文件永久解密
ansible-vault decrypt westos --output=linux ##文件解密保存为linux##更改密码
ansible-vault rekey westos1
ansible-vault rekey westos1 --new-vault-password-file=key1
#playbook#
ansible-playbook apache_install.yml --ask-vault-pass
练习
1.用变量指定用户的各项信息:name,uid,password等
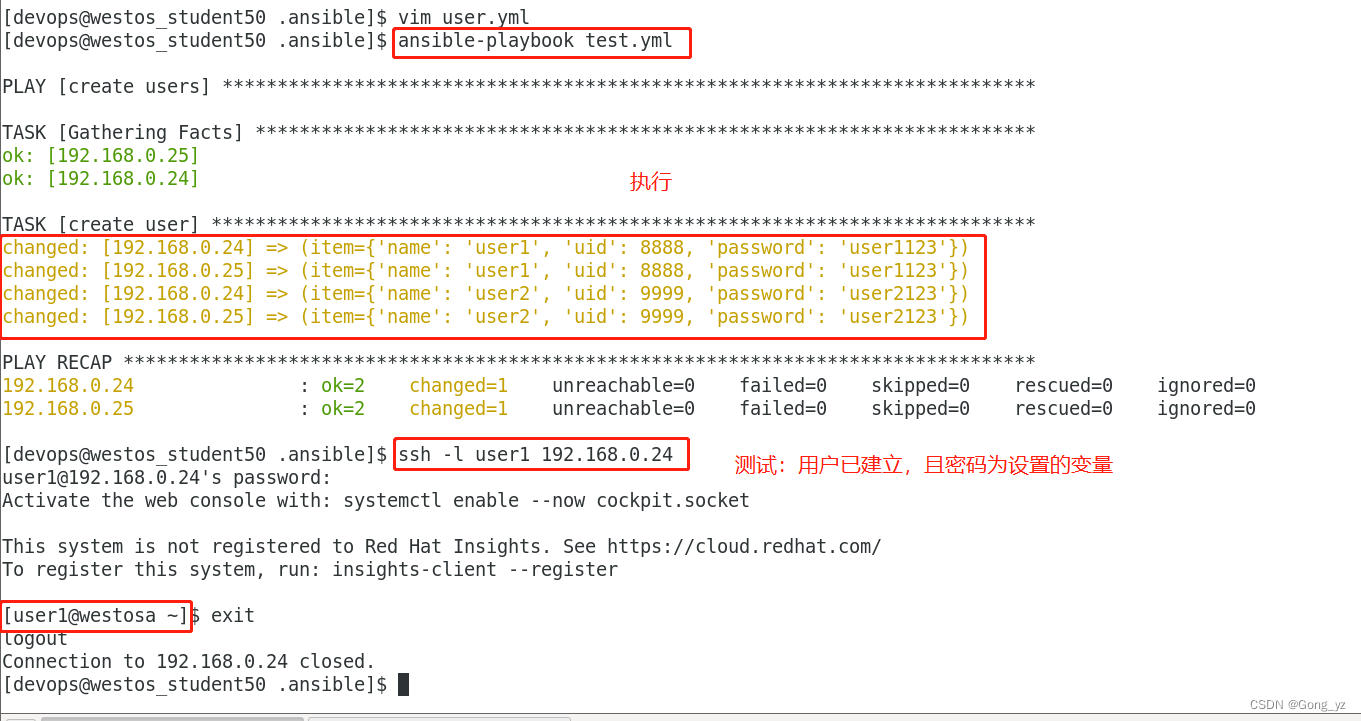
2.事实变量:在受控主机的生成/mnt/hosts文件,包括ip和主机名
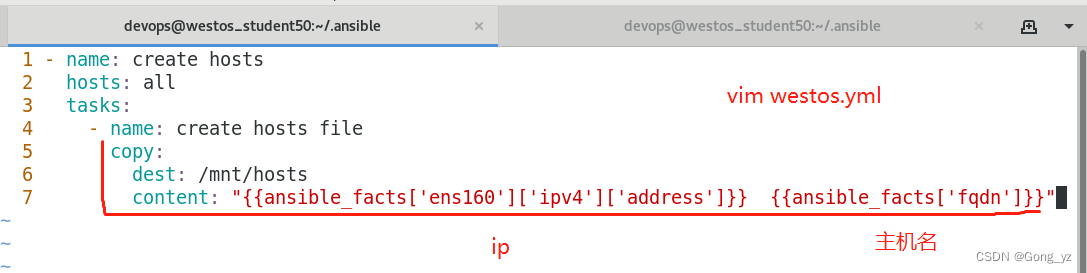

3.使用JINJA2在/mnt/hosts中生成ip和主机名
与事实变量、魔法变量联合使用