网站风格设计描述网站查外链
开头语:
你好呀,我是计算机学长猫哥!如果有相关需求,文末可以找到我的联系方式。
开发语言:
Java
数据库:
MySQL
技术:
Java + JSP + Servlet + JavaBean
工具:
IDEA/Eclipse、Navicat、Maven
系统展示
首页

管理员功能模块

用户功能模块

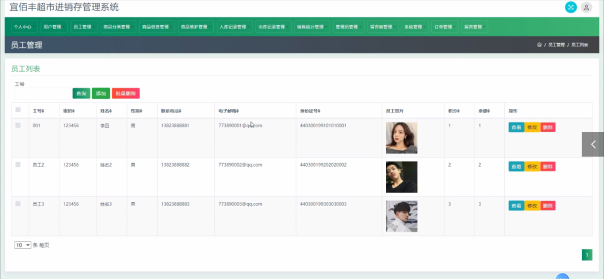
员工功能模块
摘要
21世纪的今天,随着社会的发展,信息科学化管理的重要性日益凸显。宜佰丰超市进销存管理系统的开发,旨在通过科学化的管理提高信息存储的准确性和工作效率。本文介绍了该系统的研究现状、开发背景、设计目标、需求分析和设计方案,并对系统设计和实现进行了详细论述。系统采用B/S结构,以Java为开发技术,后端使用MySQL数据库,实现了包括管理员、员工和用户在内的多功能模块,并通过具体测试验证了系统的有效性。
研究意义
宜佰丰超市进销存管理系统的研究与开发,对于提升超市的管理效率、降低运营成本、增强市场竞争力具有重要意义。系统的科学化管理有助于实现信息的快速准确处理,优化库存控制,提高销售统计的效率,从而促进超市业务的持续发展和服务质量的提升。
研究目的
本研究目的在于设计并实现一个基于Java技术的宜佰丰超市进销存管理系统,以满足现代超市管理的需求。系统旨在为用户提供一个高效、便捷、安全的管理平台,实现商品信息管理、库存记录管理、销售统计和订单管理等功能,从而提高超市的经营管理水平和市场响应速度。
代码展示
// 示例代码,展示Java与数据库连接
import java.sql.*;public class DatabaseConnection {public static Connection getConnection() {String url = "jdbc:mysql://localhost:3306/yibaifeng_db";String user = "root";String password = "password";Connection conn = null;try {Class.forName("com.mysql.cj.jdbc.Driver");conn = DriverManager.getConnection(url, user, password);} catch (Exception e) {e.printStackTrace();}return conn;}
}
总结
本文通过宜佰丰超市进销存管理系统的需求分析、设计和实现,展示了Java技术在现代商业管理中的应用。系统以其高效、稳定、安全的特点,满足了超市日常运营的多种管理需求。通过系统测试,各项功能均表现良好,验证了系统的可行性和有效性。虽然在开发过程中遇到了一些技术难题,但通过不断学习和实践,问题得到了解决,也为未来的系统优化和功能扩展积累了宝贵经验。