淘宝客的网站怎么做wordpress调用子分类
题目链接
相交链表
题目描述
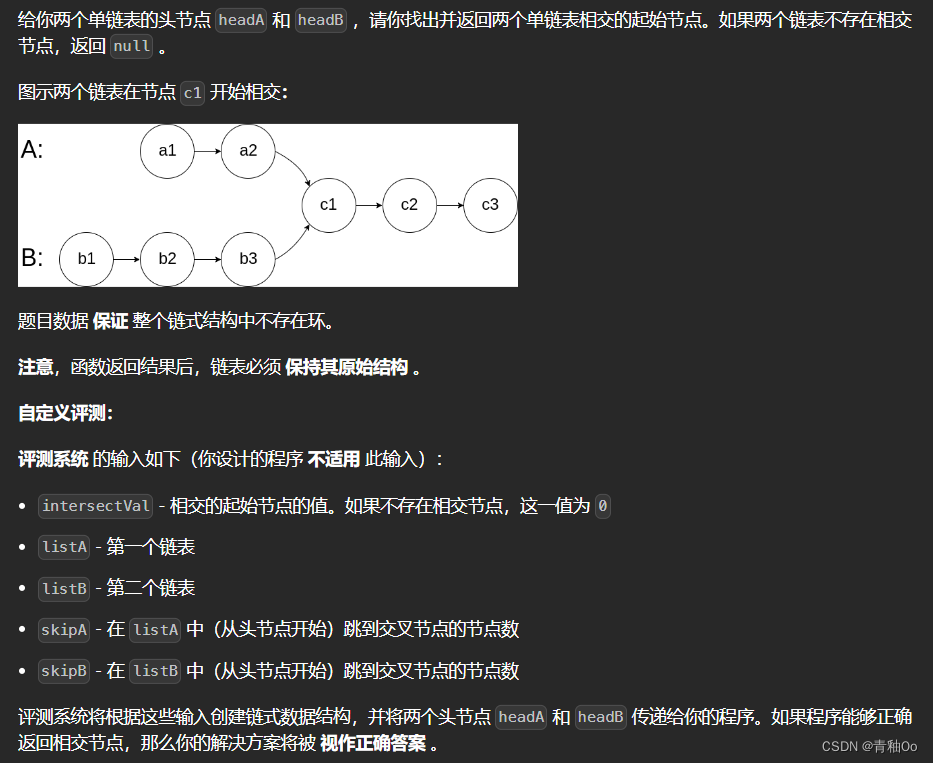


注意点
- 保证 整个链式结构中不存在环
- 函数返回结果后,链表必须 保持其原始结构
- 如果 listA 和 listB 没有交点,intersectVal 为 0
解答思路
- 两个链表从头开始遍历,如果其是在同一个位置处相交,则在第一次遍历就可找到交汇处,如果其不在同一个位置相交,则A链表遍历后接上B链表,B链表遍历后接上A链表,在第二次遍历时可在同一个位置找到交汇处,如果两个链表不相交,则会在第二次遍历后共同指向空
代码
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {ListNode nodeA = headA;ListNode nodeB = headB;while (nodeA != null || nodeB != null) {if (nodeA == null) {nodeA = headB;}if (nodeB == null) {nodeB = headA;}if (nodeA == nodeB) {return nodeA;}nodeA = nodeA.next;nodeB = nodeB.next;}return null;}
}
关键点
- 无