大型营销型网站制作网站服务器租用多少钱
目录
最初安装Visual Studio 2010学习版是因为计算机二级 C语言考试而装,现如今考完试后便可卸载掉了,安装简便而卸载却没有uninstall.exe文件。故本文提供卸载方式。
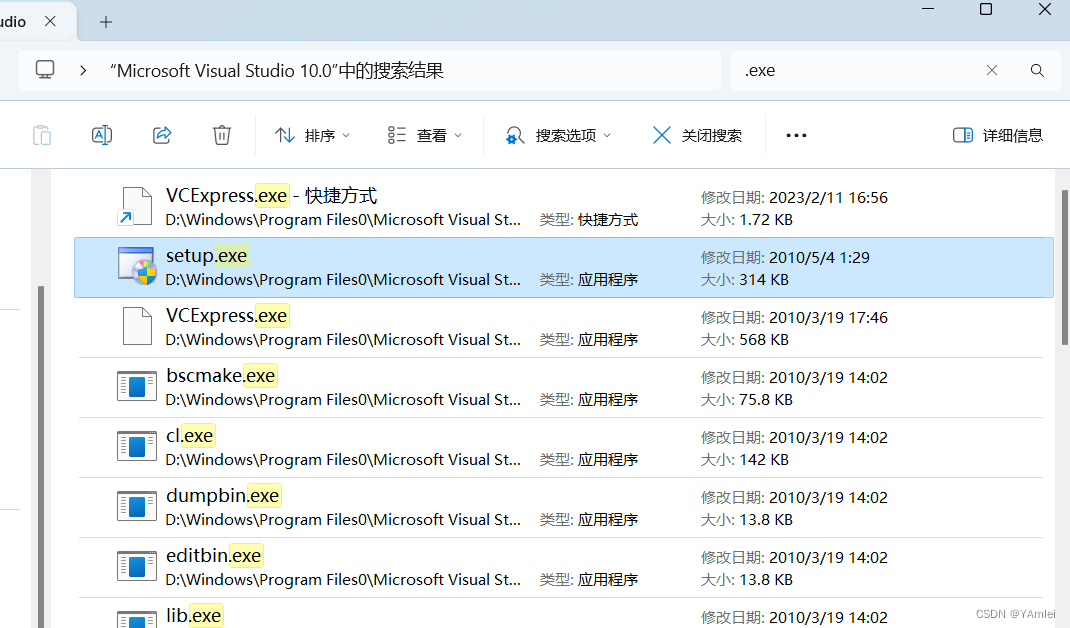
进入到程序目录,找到setup.exe文件,也可以在程序目录搜索setup.exe文件:
Microsoft Visual Studio 10.0\Microsoft Visual C++ 2010 Express - CHS
点击后等待……
点击卸载、下一步
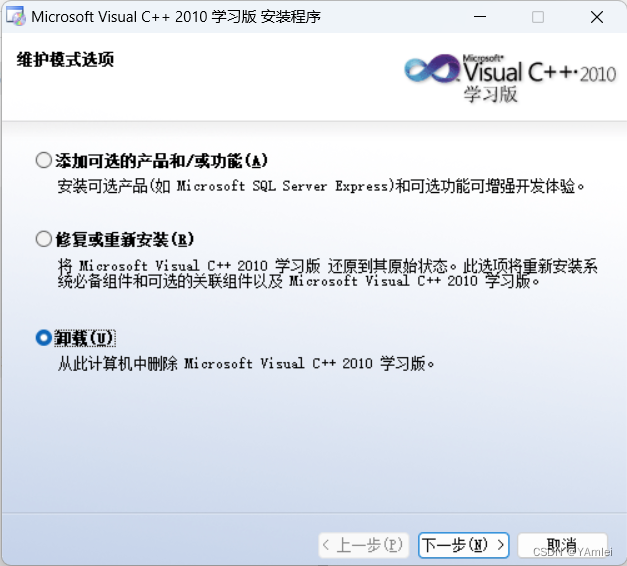
卸载完毕。