网站营销活动大学生html5网页大作业
shiro整合redis
前言:shiro默认的session是存储在jvm内存中的,这样会导致java服务内存占用更大以及一旦服务器宕机或者版本迭代需要重启服务时,缓存中的数据不能恢复,导致用户需要重新登录认证,体验很差。因此利用第三方服务作为缓存十分重要。
shiro有相关的shiro-redis整合的依赖包,使用起来也十分方便,下面就介绍下使用方法
本文前提是已搭建好shiro的简单框架,配置好realm以及配置类(设置好SecurityManager等)
1.引入shiro-redis依赖
<!-- shiro --><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-spring</artifactId><version>1.13.0</version></dependency> <!-- shiro-redis --><dependency><groupId>org.crazycake</groupId><artifactId>shiro-redis</artifactId><version>3.3.1</version></dependency>
2.配置redis数据源
其实不需要配置,因为在下面的RedisManager是直接将参数设置进入的,yaml文件的配置并不生效。
但是因为其他业务也可能用到redis,所以在yaml中配置,下面的RedisManager可以通过@Value(“$spring.redis.xxx”)进行引入,避免撤换redis数据源时,需要修改多处地方。
spring:redis:host: 127.0.0.1port: 6379database: 0jedis:pool:max-idle: 8min-idle: 0max-active: 8max-wait: -1timeout: 0
3.配置ShiroConfig类
在ShiroConfig类中,将redis设置为session的缓存,在原有基础上添加以下代码
/*** redisManager* @return*/public RedisManager redisManager() {RedisManager redisManager = new RedisManager();// 高版本的shiro-redis,取消setPort方法,需要将Port和Host写在一起redisManager.setHost("127.0.0.1:6379");// 配置过期时间redisManager.setTimeout(1800);return redisManager;}/*** cacheManager* @return*/public RedisCacheManager cacheManager() {RedisCacheManager redisCacheManager = new RedisCacheManager();redisCacheManager.setRedisManager(redisManager());return redisCacheManager;}/*** redisSessionDAO*/public RedisSessionDAO redisSessionDAO() {RedisSessionDAO redisSessionDAO = new RedisSessionDAO();redisSessionDAO.setRedisManager(redisManager());return redisSessionDAO;}/*** sessionManager*/public DefaultWebSessionManager SessionManager() {DefaultWebSessionManager sessionManager = new DefaultWebSessionManager();sessionManager.setSessionDAO(redisSessionDAO());return sessionManager;}
然后在之前的配置上,将session管理器和cache管理器注入到SecurityManager中
/*** 配置SecurityManager* @param myRealm* @return*/@Beanpublic SecurityManager securityManager(Realm myRealm){DefaultWebSecurityManager securityManager = new DefaultWebSecurityManager();//设置一个Realm,这个Realm是最终用于完成我们的认证号和授权操作的具体对象securityManager.setRealm(myRealm);securityManager.setSessionManager(sessionManager());securityManager.setCacheManager(cacheManager());return securityManager;}
4.测试
保证redis参数正常,连接正常,启动项目
访问登录连接
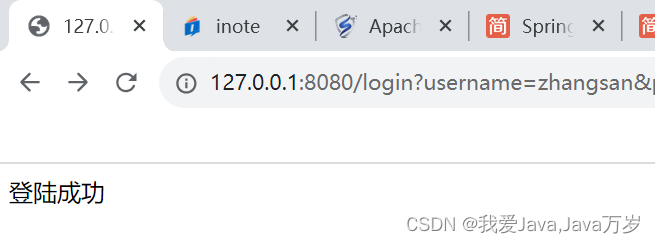
redis被成功写入,见下图
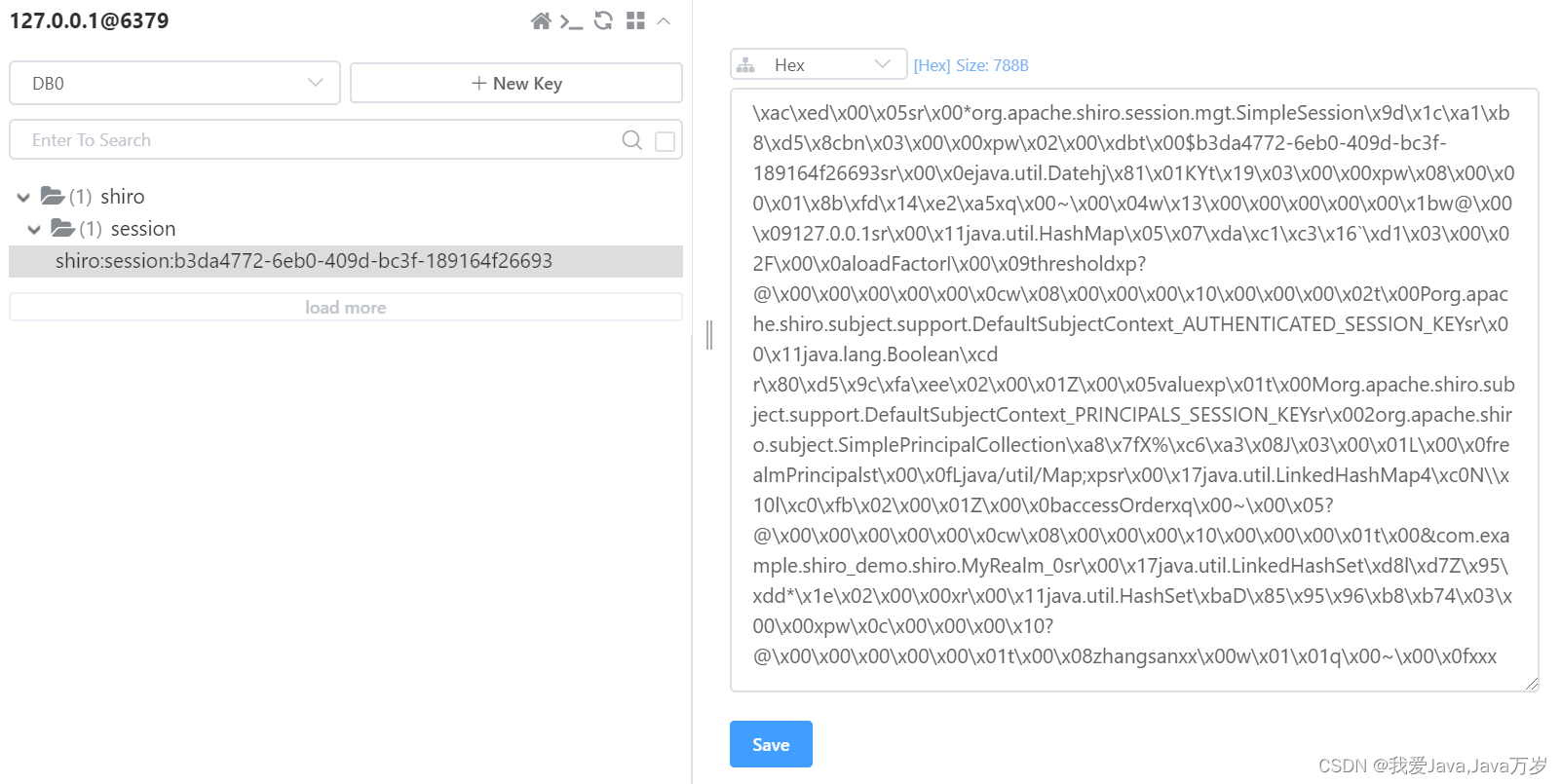
经过在doGetAuthenticationInfo方法和doGetAuthorizationInfo方法中设置简单输出语句,发现只在第一次登录时进入认证方法,第一次授权时进入授权方法。后续都不再进入该方法。
至此,Shiro+Redis集成完毕