网站设置右击不了如何查看源代码58同城旧房翻新
一、行业背景
随着国民经济的蓬勃发展,工业用电和居民用电需求迅速增加,电厂、变电站、输电线路高负荷运转,一旦某个节点发生故障,对生产、生活造成巨大的影响。目前电力行业生产现场人员、设备较多,而生产监督员有限,在电力作业过程中无法实现全方位、全过程的安全巡检和管控,因作业人员的违规行为无法得到预警和控制而引发的事故也频频发生,带来极大危害和造成损失。
二、方案概述
TSINGSEE青犀依托视频监控技术以及AI视频智能分析能力,将电力系统日常巡线、抢修现场的音视频实时地传输至由EasyCVR视频平台构建的监控中心,后台人员不仅能通过视频实时了解各线路传输点的日常运行状态,同时借助AI智能分析能力,能对作业中存在的违规操作和行为进行识别与预警,协助管理员及时进行处理,提高巡线效率。
在巡视人员工作时,需要配备手持单兵设备,在重大事故现场需要配备单兵手提箱。设备具备视频、对讲、录像、报警、抓拍、定位、集群呼叫、多方会审,能将事故现场的视频实时传输至EasyCVR视频监控平台,供管理人员决策,并且能通过这些设备,双方之间可以实时沟通,更快、更准确地找到事故原因,提供解决办法。
对于工程抢修车,安装车载子系统,配备4G车载硬盘录像机、车载摄像机、键盘、车载电话等设备,工程车车载摄像头采集的现场视频画面也能传输至EasyCVR视频监控平台,有效保障抢修车辆与后台的实时视频通信。
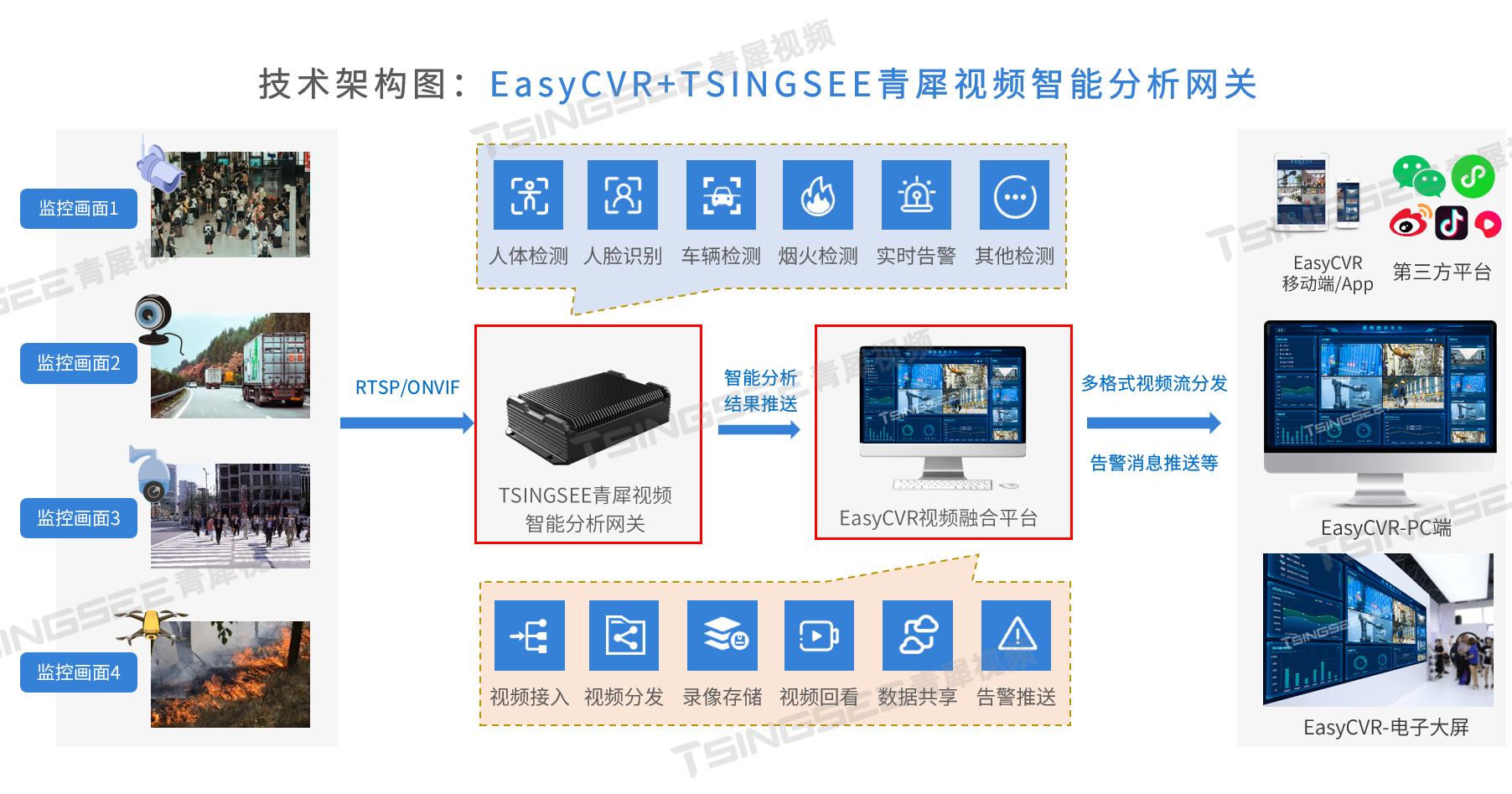
视频监控联网平台EasyCVR支持多协议方式接入(国标GB/T28181、RTMP、RTSP/Onvif协议,海康Ehome、海康SDK、大华SDK、宇视SDK、华为SDK、萤石SDK、乐橙SDK等),兼容多类型的设备接入,支持单画面、多画面显示,可选择任意一路或多路视频观看,视频窗口数量1、4、9、16个可选。

三、方案特点
1)集中视频监控
所有变电站现场监控图像实时传送到监控中心,实现远程监控功能,支持视频上墙、电子大屏、拼接大屏等多终端显示,还支持视频轮巡播放,提高监管效率。
2)风险预警报警
对于非法闯入的人员入侵或设备盗窃行为进行AI智能检测与预警,保护财产安全;对作业人员的违规操作、未按照规范着装的行为进行实时检测与预警,提醒安全作业。

具体算法包括:未戴安全帽检测、未穿工服检测、未穿长袖检测、人员入侵检测、打电话/玩手机/抽烟检测、人员倒地检测、烟火检测等。
3)应急指挥
当对设备检修时,远程中心可以通过视频画面实时了解检修过程,并指导复杂操作过程。
4)日巡管理
监控中心能对各变电站的日常巡查管理,将视频、数据进行保留,形成日巡管理记录表,平台支持视频实时录像与回看,录像文件支持云存储、下载、分享等,方便后期查阅。
5)信息完备
视频监控系统同时可以传送多种环境信息,包括环境温度、湿度、电压值、电流量等实时信息。