网站制作课题组免费国内ip
Shell脚本异常傲娇,出错后、执行完根本不给你机会让你查看报错信息、输出信息,直接闪退。
废话不多说,调教方法如下,直接在Shell脚本末尾加上如下代码:
1、实现方式一
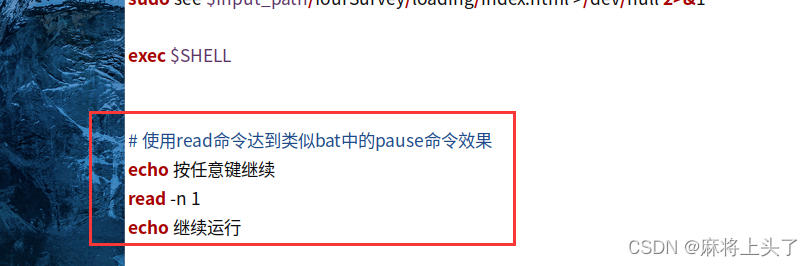
1.1 使用read命令达到类似bat中的pause命令效果
直接在原来的脚本末尾,加上下面一段代码,实现类似bat中的pause命令效果
# 使用read命令达到类似bat中的pause命令效果
echo 按任意键继续
read -n 1
echo 继续运行例:
某.sh文件内容如下图,执行完或出错后直接闪退。
末尾加上代码:
1.2 运行效果
运行完毕,弹出提示 按任意键继续
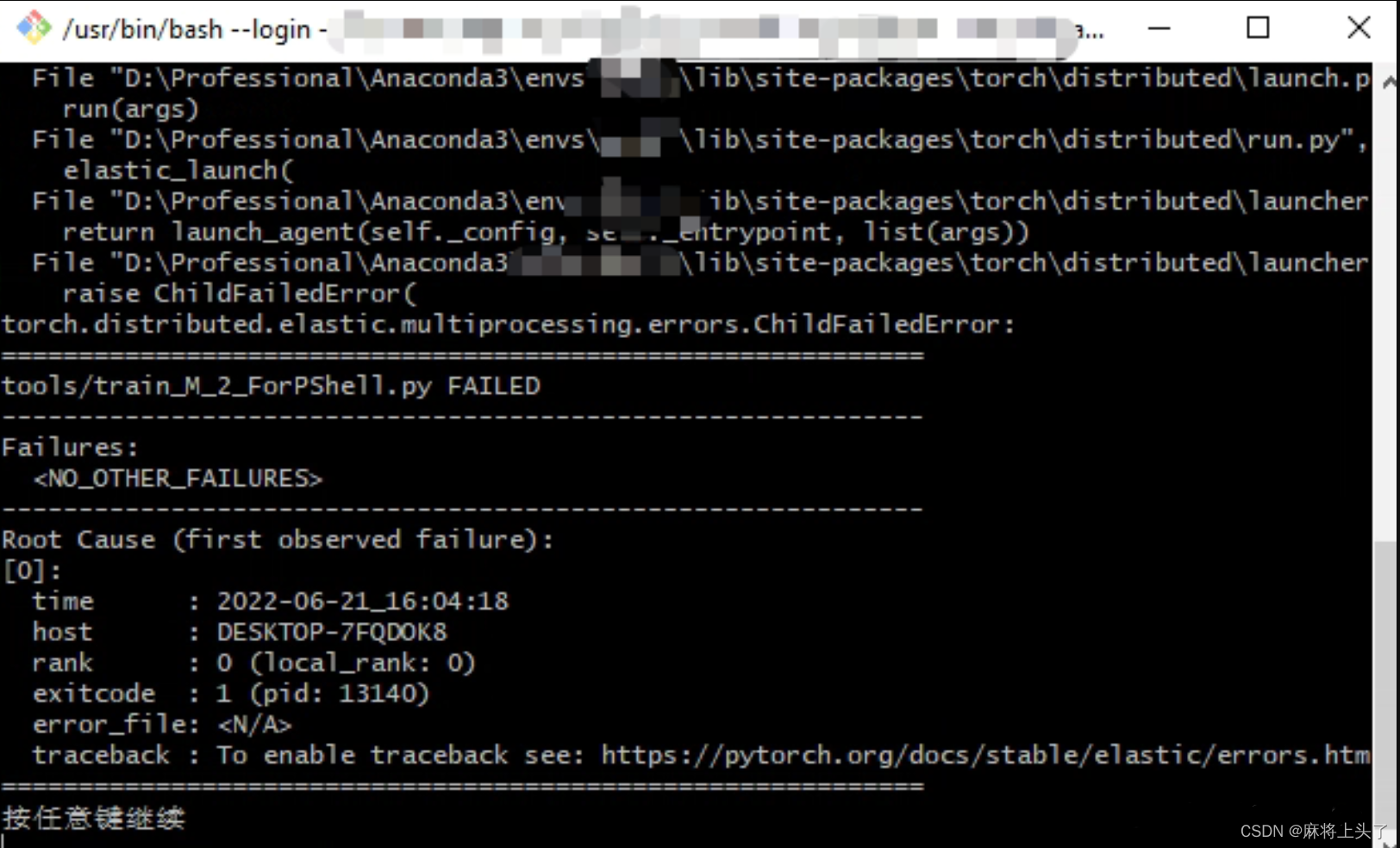
这样,运行出错后、执行完,可以有足够的时间来查看报错信息、输出信息。按任意键关闭窗口或者点击关闭窗口。
2、实现方式二
2.1 增加一个sleep 10000来防止窗口自动关闭
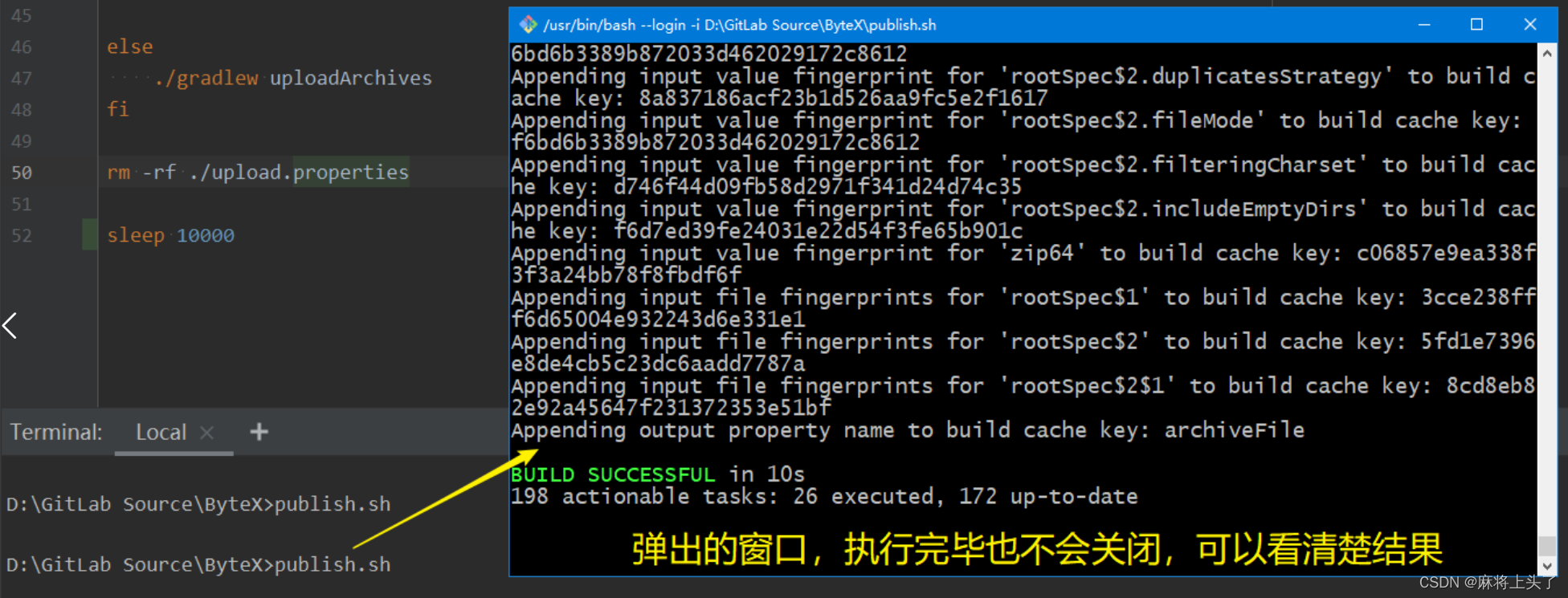
然后 我在这个文件的结尾,增加一个sleep 10000,如下所示

2.2 运行效果
这样运行该publish.sh的时候,就不会主动关闭窗口了。
3、实现方式三
3.1 使用tail -f /dev/null命令:
#!/bin/bash
# 你的脚本命令# 在脚本的最后添加这行
tail -f /dev/null4、实现方式四
4.1 使用read -n 1命令:
#!/bin/bash
# 你的脚本命令# 在脚本的最后添加这行
echo "Press any key to continue..."
read -n 1