合肥建设云个人服务平台电商网站建设关键词优化
1. vue的 nextTick的原理
首先vue实现响应式并不是数据发生变化后dom立即更新,而是按照一定的策略 异步执行dom更新的。
vue在修改数据后,试图不会立即进行更新,而是要等同一事件循环机制内所有数据变化完成之后,在统一更新
nextTick可以让我们在下次dom更新循环结束之后执行延迟回调,用于获取更新后的dom
事件循环机制:
在浏览器中,我们可以将我们的执行任务分为微任务和宏任务
宏任务: 整体javascript,setTimeout,setInterval,setLmmediate
微任务:promise.then promise.all
具体执行顺序:
首先加载js代码,然后在执行里面的同步任务,在执行的过程中如果遇到了异步任务,会把他放到一个任务队列中,在任务队列里面,会判断是宏任务还是微任务,首先会执行宏任务,因为弘任务是整体的javascript代码,所以第一步会先执行宏任务,在执行宏任务的过程中,如果遇到微任务,同样道理,也会把他当到当前的任务队列里面,等这个宏任务执行完毕之后,再去执行当前的微任务,当前微任务执行完毕之后,再去执行下一个宏任务。
<template><div><div>{{ count }}</div><div @click="handleClick">click</div></div>
</template><script>export default {data() {return {count:0}},methods: {handleClick() {for (let i = 0; i < 1000; i++) {this.count++}}},}
</script>
当点击按钮,count会被循环1000次,每次count+1,都会出发count的setter方法,然后修改真实的dom,按此逻辑,真个过程,dom会被更新1000次,而dom的每次更新是非常消耗性能的,而且这样的操作是完全没有必要的,所以vue在内部派发更新时做了优化,也就是并不是每次数据更新,都会去出发回调,而是把更新的数据放到一个任务队列里面,等待所有的数据都更新完毕之后,再去执行回调函数,更新最后的dom
vue.nextTick 原理:
vue中数据变化到dom变化,是一个异步的过程,一旦观察到数据发生变化,vue就会开启一个任务队列,然后把在同一个事件循环中观察的数据变化的Watcher(vue源码中的watcher类是用来更新dep类收集到的依赖的)推送到这个队列中。
如果这个watcher被触发多次,他只会被推送到队列一次,这种缓存行为可以有效的去掉重复数据造成的不必要的计算和dom操作,而到了下一个事件循环时,vue会清空队列,并进行dom更新。nextTick的作用是为了在数据发生变化之后等待vue完成更新dom,可以在数据变化之后立即使用vue。nextTick,js是单线程语言,nextTick的实现就是利用了事件循环的宏任务和微任务。
vue.nextTick的应用:
1.在create生命周期中操作dom
create钩子函数的时候,dom其实并没有进行挂载和渲染,此时是无法操作dom的,我们将操作dom的代码可以方法nextTick只。
<template><div><span ref="text">12345</span></div>
</template><script>
export default {created() {// 会直接报错this.$refs.text.innerHTML = '2222222'this.$nextTick(() => {this.$refs.text.innerHTML = '2222222'})},
}
</script>
2.修改数据获取dom的值
当我们修改了data里的数据时,并不能立即通过操作dom去获取到里面的值,或者说页面的值没有发生变化
<template><div><span ref="text">{{ a }}</span><span>{{ b }}</span><span >{{ c }}</span></div>
</template>
<script>
export default {data() {return {a: 0,b:0,c:0,}},methods: {chage() {this.a = 12// 你会发现获取的值没有发生改变 this.b = this.$refs.text.innerHTMLthis.$emit('check', this.a)//通过加入nextTick后,获取的值才会发生改变,这是在dom更新之后的值this.$nextTick(() => {this.c = this.$refs.text.innerHTML})}},
}
</script>
3.还有一种情况就是在做修改的时候,model对话框没有渲染父组件带过的值
// 通过父组件点击修改或者查看,如果不用nextTick你会发现从父组件带过来的record参数没有被渲染到model对话框上,这个应为visibel为true的时候model还没dom还没有被更新,所以setFieldsValue是不生效的,必须用nextTick异步更新dom之后在去渲染数据edit(record) {this.form.resetFields();this.model = Object.assign({}, record);this.visible = true;this.$nextTick(() => {this.form.setFieldsValue(pick(this.model,"kpilevel","classify",...));});},
2.vue修改数据后页面不重新渲染的问题
在对一个对象遍历之后进行属性添加添加成功之后页面不刷新的问题
<template><div><span v-for="(value, key) in params" :key="key">{{ value }}</span><a-button type="primary" @click="handleClick" icon="search">查询</a-button></div>
</template><script>
export default {data() {return {params: {a: '1',b: 2,c: 3,}}},methods: {handleClick() {this.params.d = 13// 这里能够打印出来,但是页面没有刷新console.log(this.params);}},
}
</script>
问题分析: 应为vue2是用过Object.defineProperty实现数据响应式,组件初始化才递归遍历item,这时候并没有给item的每个属性添加set和get方法,所有后来并没有给newVal设置成响应式数据,结果就是修改后不会视图更新。
const item = {}
Object.defineProperty(obj, 'oldProperty', {get() {console.log(`get oldProperty:${val}`);return val},set(newVal) {if (newVal !== val) {console.log(`set oldProperty:${newVal}`);val = newVal}}
})
}
组件初始化时,对data中的item进行递归遍历,对item的每一个属性进行劫持,添加set,get方法。我们后来新加的newProperty属性,并没有通过Object.defineProperty设置成响应式数据,修改后不会视图更新。
所以vue不允许再以创建的实例上动态的添加新的属性。但是如果想实现数据和试图同步更新,要怎么操作:
1.vue.set( )
target: 需要更改的数据源(可以是一个对象或者数组)
key:需要更改的具体数据,如果是数组元素更改,key表示索引,如果是对象,key表示键值
value:重新赋的值
Vue.set( target, propertyName/index, value )this.$set(this.params, "newProperty", "新值");
this.$set(this.params, 13, {key: 'newkey', name: '888'})
2. Object.assign( )
this.params = Object.assign({},this.params,{newProperty:'新值'})3. $forceUpdate( )
这种迫使vue强制刷新,迫使dom重新渲染,他会影响本身,还有涉及到的子组件以及插槽,都会更新,一般是不建议使用
this.params.newProperty = "新值"
this.$forceUpdate();4. 通过扩展语法 …
const aa = { ...this.params, d: 13 }this.params = aa
5.同过在组件添加一个key,对key来进行修改
<span :key="componentKey" /><span v-for="(value, key) in params" :key="key">{{ value }}</span><a-button type="primary" @click="handleClick" icon="search">查询</a-button>handleClick() {this.params.d = 13this.componentKey += 1}
3. 聊一聊vue里面组件之间的传值
首先总结一下vue里面传值的几种关系:

如上图所示, A与B、A与C、B与D、C与F组件之间是父子关系; B与C之间是兄弟关系;A与D、A与E之间是隔代关系; D与F是堂兄关系,针对以上关系 我们把组件之间传值归类为:
1.父子组件之间的通讯
2.非父子组件之间的通讯(兄弟组件 隔代关系组件)
vue里面组件通许的方式:
- props/$emit
- $children / $parent
- ref / refs
- provide / reject
- eventBus
- $attrs / $linteners
- vuex
- localStorage / sessionStorage
1.父组件向子组件传值
<template><div class="section"><com-article :articles="articleList"></com-article></div>
</template>
<script>
import comArticle from './test/article.vue'
export default {name: 'HelloWorld',components: { comArticle },data() {return { articleList: ['1', '2', '3'] }}
}
</script><template><div><span v-for="(item, index) in articles" :key="index">{{ item }}</span></div><script>export default {props: ['articles']}
</script>
2.子组件向父组件传值
<template><div class="section"><com-article :articles="articleList" @onEmitIndex="onEmitIndex"></com-article><p>{{ currentIndex }}</p></div>
</template>
<script>
import comArticle from './test/article.vue'
export default {name: 'HelloWorld',components: { comArticle },data() {return { currentIndex: -1, articleList: ['小姐姐', '小妹妹', '小富婆'] }},methods: {onEmitIndex(idx) {this.currentIndex = idx}}
}
</script>// prop 只可以从上一级组件传递到下一级组件(父子组件),即所谓的单向数据流。而且 prop
只读,不可被修改,所有修改都会失效并警告。<template><div><div v-for="(item, index) in articles" :key="index" @click="emitIndex(index)">{{ item }}</div></div>
</template><script>
export default {props: ['articles'],methods: {emitIndex(index) {this.$emit('onEmitIndex', index)}}
}
</script>
二. $children / $parent 直接简单点写法:
this.$parentthis.$children
这种方式是直接通过children 或者parent获取组件上的所有对象实例,并且他还是一个数组,我们一般要获取需要这么写
this.$children[0].age,通过索引获取到自己想要的子组件,当子组件比较多的时候,如果后期某个子组件删除了或者新增,对应的索引有可能会发生变化,既不利于维护,所以在实际开发中用的比较少。
同样的this. $parent获取父组件的所有实例对象,当涉及到公共子组件的时候,定义的名称可能耦合性比较高,如果以这种方式去修改父组件的状态,很容易出问题,甚至调试都很不方便,所以也一般用的比较少。
3. ref / refs
ref:如果在普通的 DOM 元素上使用,引用指向的就是DOM 元素,可以操作dom元素的方法,如果用在子组件上,引用就指向组件实例,可以通过实例直接调用子组件的方法或数据
<template><span>{{name}}</span>
</template>
<script>
export default {data() {return {name: 'xxxx'}},
}
</script><template><component-a ref="comA"></component-a><span ref="spanRef">1234</span><a-button type="primary" @click="handleClick">xx</a-button>
</template>
<script>
export default {methods: {handleClick(){console.log(this.$refs.spanRef.innerHtml); // 1234const comA = this.$refs.comA;console.log(comA.name)}},
}
</script>
4.provide / reject
5.eventBus
eventBus可以作为全局组件通信(任意的两个组件,没有任何关联的组件),可以直接进行交流的通讯方案,eventBus通常用来做全局范围内通信的一个常用方案,非常灵活 使用简单而且很轻
在vue2里面的使用:
import Vue from 'vue'
// main.js 中// 第一种定义方式
Vue.prototype.$eventBus = new Vue()// 第二种定义方式
window.eventBus = new Vue();**触发事件:**
// params 多个参数
this.$eventBus.$emit('eventName', param1,param2,...)//使用方式二定义时
eventBus.$emit('eventName', param1,param2,...)**监听事件**
//使用方式一定义时
this.$eventBus.$on('eventName', (param1,param2,...)=>{//需要执行 逻辑代码// params 多个参数
})//使用方式二定义时
eventBus.$on('eventName', (param1,param2,...)=>{//需要执行 逻辑代码
})**移除事件,在开发过程中,当离开当前页面时要取消坚挺,避免事件被反复出发,和造成内存泄漏**
//使用方式一定义时
this.$eventBus.$off('eventName');//使用方式二定义时
eventBus.$off('eventName');
EventBus的原理是什么? 直接上代码
class MyEventBus {constructor() {// 存储所有事件对应的回调的对应关系/*** key : [ callback, callback ]*/this.items = {};}// 监听$on(eventName, callback) {if (!this.items[eventName]) {//一个事件可能有多个监听者this.items[eventName] = [];}this.items[eventName].push(callback)// 简化版写法 等同于上面// (this.items[eventName] ||= []).push(callback)}// 触发监听$emit(eventName, ...args) {if (!this.items[eventName]) return;this.items[eventName].forEach(ca => ca(...args))}// 去掉监听$off(eventName) {this.items[eventName] = []}
}
export default new MyEventBus();
Vue3种移除了$on $off等自带自定义事件的相关方法,因此在vue3中使用mitt来代替eventBus
//在utils目录下,新建 mitt.js 文件,写入下面代码进行封装import mitt from 'mitt'const emitter =new mitt()export default emitter// 在使用中直接引入import emitter from '../api/mitt'emitter.on('foo', e => console.log(e) ) //emitteremitter.emit('foo', 'emitter')// 用法 引入封装好的mitt即可直接使用mitt,但需要注意:注册事件最好在钩子onMounted中进行,并且注册的事件需要在onUnmounted钩子中移除。如果不移除同样有可能会造成反复调用,和内存泄漏等问题// 引入 mittimport emitter from '../api/mitt'// 注册emitter.on('eventName', function(e) {console.log(e)})// 调用emitter.emit('eventName', 'emitter')// 移除emitter.off('eventName')5. $attrs / $linteners
$attrs:用于多层次组件传递参数(组件标签的attribute,class和style除外),爷爷辈组件向孙子辈组件传递参数(注:参数不能被父辈prop识别,一旦被父辈prop识别且获取,则孙子辈组件不能获取到该参数) 并且 v-bind不能被简写
$listeners:用于多层次组件传递事件监听器,爷爷辈组件向父辈、孙子辈、曾孙子辈……组件传递事件(与 $attrs 不同,不存在半路被拦截的情况)v-on 不能用简写 @,虽然不报错,但是也不生效
<template><div>GrandFather:<index1 :dataMessage="dataMessage" :dataCode="dataCode" :dataList="dataList" :grendClick="grendClick"@hancleClick="handleClick" @handleSelect="handleSelect" aaa="this is a undefiend" /></div>
</template><script>
import Index1 from "./index1";
export default {props: { dataStatus: Number },components: { Index1 },data() {return {a: 0,dataMessage: 1234,dataCode: "400",dataList: [1, 2, 3, 4, 5],};},methods: {handleClick() {console.log(1234);},handleSelect() {console.log(456);},grendClick() {console.log("grendClick");},},
};
</script><script>
import Index2 from './index2.vue';
export default {inheritAttrs: false,components: { Index2},props: {dataMessage: {default: 0,type: Number},grendClick: {default: () => {return Function}}},data() { return { adus: '12345' } },created() {// 这个从一级组件的dataMessage被当前页截取了。console.log(this.dataMessage, 'dataMessage');},methods: {handleClickB() {console.log('this is B');this.grendClick()},},
}
</script><template><div><span>GrandSon</span><a-button type="primary" @click="handleClickC">GrandSon</a-button><span ref="spanRef">1234</span></div>
</template><script>
export default {inheritAttrs: false,methods: {handleClickC() {console.log(this.$attrs, 'attrs'); // 从最上级带过来的变量console.log(this.$listeners, 'listeners'); // 从最上级带过来方法},},
}
</script>关于Vue的inheritAttrs的理解:
vue官网对于inheritAttrs的属性解释:默认情况下父作用域的不被认作 props 的 attribute 绑定 (attribute bindings) 将会“回退”且作为普通的 HTML attribute 应用在子组件的根元素上。
如果你不希望组件的根元素继承特性,你可以在组件的选项中设置 inheritAttrs: false。
直接看效果: 当设置为true,默认是为true的

当设置为false时后:这也算的上是一点点小优化策略吧
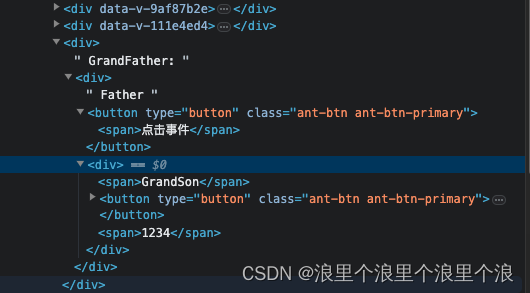
7.localStorage / sessionStorage
这个我们用的应该是比较多的,我们在vue里面用的比较多的Vul-ls
import Vue from 'vue'
import Storage from 'vue-ls'// vue-ls 的配置
const storageOptions = {namespace: 'vue_', // key 键的前缀(随便起)name: 'ls', // 变量名称(随便起) 使用方式:Vue.变量名称 或 this.$变量名称storage: 'local' // 作用范围:local、session、memory
}Vue.use(Storage, storageOptions)
就不做具体的操作了
浏览器缓存里面有个可以监听缓存变化的方法:废话不多说 上代码
export const resetSetItem = (key: string, newVal: string) => {if (key === 'reportcenterList') {// 创建一个StorageEvent事件const newStorageEvent = document.createEvent('StorageEvent')const storage = {setItem: function (k, val) {sessionStorage.setItem(k, val)// 初始化创建的事件newStorageEvent.initStorageEvent('setItem', false, false, k, null, val, null, null)// 派发对象window.dispatchEvent(newStorageEvent)}}return storage.setItem(key, newVal)}
}// 调用resetSetItem('reportcenterList', JSON.stringify(val))console.log('监听到数据变化')const reportcenterList = sessionStorage.getItem('reportcenterList') || ''