郑州机械网站制作临沂森工木业有限公司
获取连续日期时间
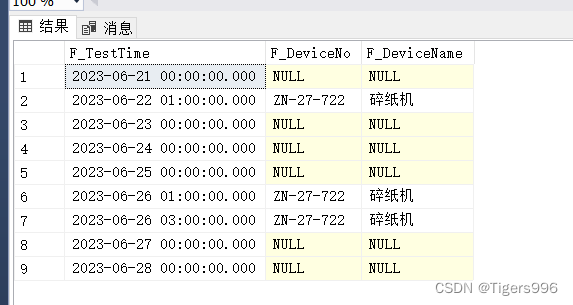
在项目中,有时候需要按日期/时间统计,例如2023-06-21至2023-06-28期间每一天的数据,如果某一天没有数据,也要查询出来,用NULL处理。
1.示例
2.连续日期效果SQL
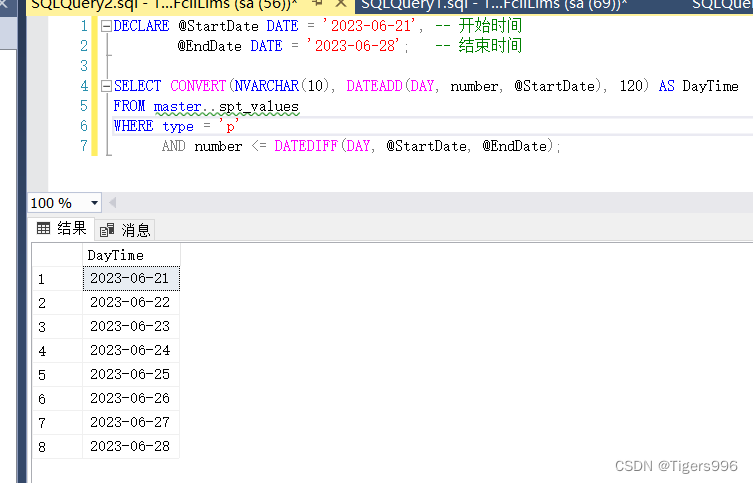
DECLARE @StartDate DATE = '2023-06-21', -- 开始时间@EndDate DATE = '2023-06-28'; -- 结束时间SELECT CONVERT(NVARCHAR(10), DATEADD(DAY, number, @StartDate), 120) AS DayTime
FROM master..spt_values
WHERE type = 'p'AND number <= DATEDIFF(DAY, @StartDate, @EndDate);
3.连续日期效果
4.完整代码
DECLARE @StartDate DATE = '2023-06-21';
DECLARE @EndDate DATE = '2023-06-28';
DECLARE @DeviceNo NVARCHAR(20) = N'ZN-27-722';
--注意where条件的位置 DeviceNo
SELECT CASE WHEN TestTime IS NULL THEN dates.Date ELSE TestTime END AS TestTime,DeviceNo,DeviceName
FROM
(SELECT CONVERT(NVARCHAR(10), DATEADD(DAY, number, @StartDate), 120) AS DateFROM master..spt_valuesWHERE type = 'p'AND number <= DATEDIFF(DAY, @StartDate, @EndDate)
) datesLEFT JOIN PreOrder ON dates.Date = CAST(TestTime AS DATE) AND DeviceNo = @DeviceNo
ORDER BY TestTime;